 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Debiasing by Learnable Data Augmentation
Aug 09, 2024



Deep Neural Networks are well known for efficiently fitting training data, yet experiencing poor generalization capabilities whenever some kind of bias dominates over the actual task labels, resulting in models learning "shortcuts". In essence, such models are often prone to learn spurious correlations between data and labels. In this work, we tackle the problem of learning from biased data in the very realistic unsupervised scenario, i.e., when the bias is unknown. This is a much harder task as compared to the supervised case, where auxiliary, bias-related annotations, can be exploited in the learning process. This paper proposes a novel 2-stage learning pipeline featuring a data augmentation strategy able to regularize the training. First, biased/unbiased samples are identified by training over-biased models. Second, such subdivision (typically noisy) is exploited within a data augmentation framework, properly combining the original samples while learning mixing parameters, which has a regularization effect. Experiments on synthetic and realistic biased datasets show state-of-the-art classification accuracy, outperforming competing methods, ultimately proving robust performance on both biased and unbiased examples. Notably, being our training method totally agnostic to the level of bias, it also positively affects performance for any, even apparently unbiased, dataset, thus improving the model generalization regardless of the level of bias (or its absence) in the data.
Learning Unbiased Representations via Mutual Information Backpropagation
Mar 13, 2020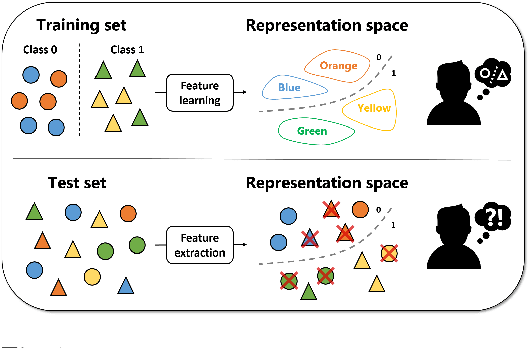
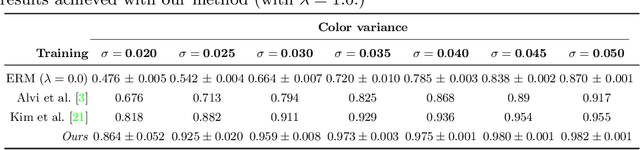
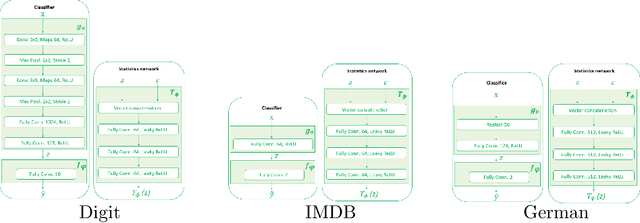
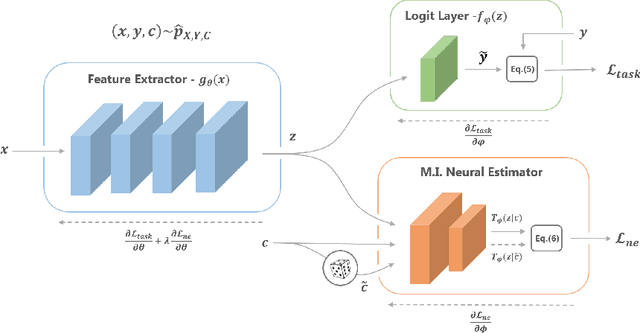
We are interested in learning data-driven representations that can generalize well, even when trained on inherently biased data. In particular, we face the case where some attributes (bias) of the data, if learned by the model, can severely compromise its generalization properties. We tackle this problem through the lens of information theory, leveraging recent findings for a differentiable estimation of mutual information. We propose a novel end-to-end optimization strategy, which simultaneously estimates and minimizes the mutual information between the learned representation and the data attributes. When applied on standard benchmarks, our model shows comparable or superior classification performance with respect to state-of-the-art approaches. Moreover, our method is general enough to be applicable to the problem of ``algorithmic fairness'', with competitive results.
Generative Pseudo-label Refinement for Unsupervised Domain Adaptation
Jan 09, 2020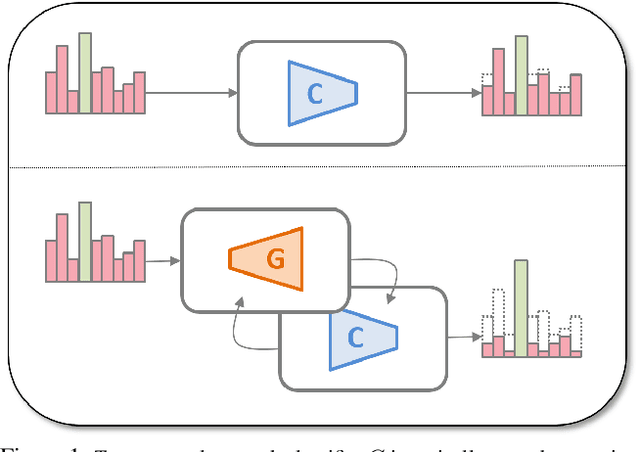
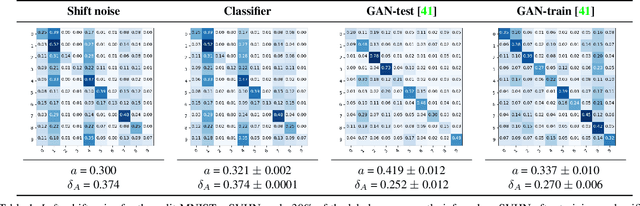
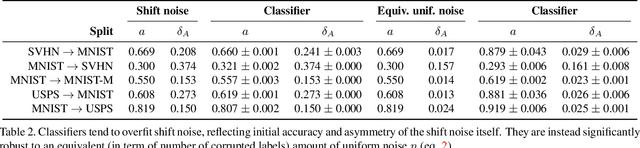
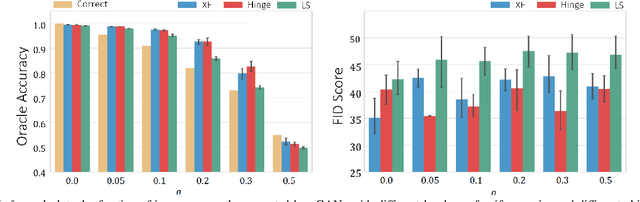
We investigate and characterize the inherent resilience of conditional Generative Adversarial Networks (cGANs) against noise in their conditioning labels, and exploit this fact in the context of Unsupervised Domain Adaptation (UDA). In UDA, a classifier trained on the labelled source set can be used to infer pseudo-labels on the unlabelled target set. However, this will result in a significant amount of misclassified examples (due to the well-known domain shift issue), which can be interpreted as noise injection in the ground-truth labels for the target set. We show that cGANs are, to some extent, robust against such "shift noise". Indeed, cGANs trained with noisy pseudo-labels, are able to filter such noise and generate cleaner target samples. We exploit this finding in an iterative procedure where a generative model and a classifier are jointly trained: in turn, the generator allows to sample cleaner data from the target distribution, and the classifier allows to associate better labels to target samples, progressively refining target pseudo-labels. Results on common benchmarks show that our method performs better or comparably with the unsupervised domain adaptation state of the art.