 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifier Crafting: Turn Your ConvNet into a Zero-Shot Learner!
Paper and Code
Mar 20, 2021
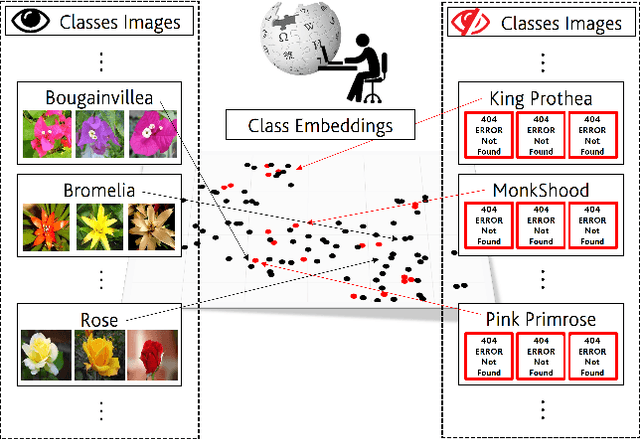
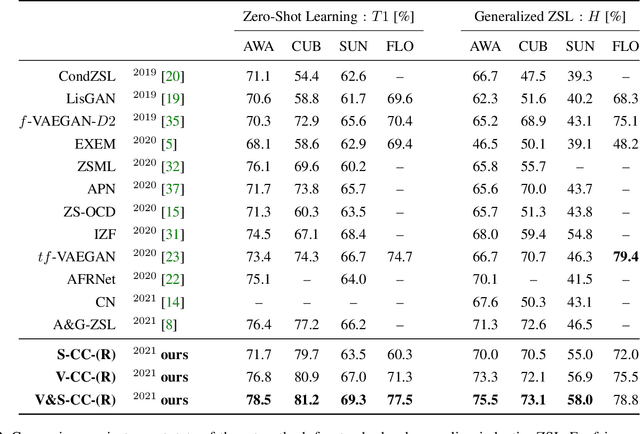
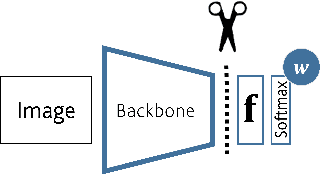
In Zero-shot learning (ZSL), we classify unseen categories using textual descriptions about their expected appearance when observed (class embeddings) and a disjoint pool of seen classes, for which annotated visual data are accessible. We tackle ZSL by casting a "vanilla" convolutional neural network (e.g. AlexNet, ResNet-101, DenseNet-201 or DarkNet-53) into a zero-shot learner. We do so by crafting the softmax classifier: we freeze its weights using fixed seen classification rules, either semantic (seen class embeddings) or visual (seen class prototypes). Then, we learn a data-driven and ZSL-tailored feature representation on seen classes only to match these fixed classification rules. Given that the latter seamlessly generalize towards unseen classes, while requiring not actual unseen data to be computed, we can perform ZSL inference by augmenting the pool of classification rules at test time while keeping the very same representation we learnt: nowhere re-training or fine-tuning on unseen data is performed. The combination of semantic and visual crafting (by simply averaging softmax scores) improves prior state-of-the-art methods in benchmark datasets for standard, inductive ZSL. After rebalancing predictions to better handle the joint inference over seen and unseen classes, we outperform prior generalized, inductive ZSL methods as well. Also, we gain interpretability at no additional cost, by using neural attention methods (e.g., grad-CAM) as they are. Code will be made publicly available.