 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROPE: A Novel Method for Real-Time Phase Estimation of Complex Biological Rhythms
Sep 05, 2025Accurate phase estimation -- the process of assigning phase values between $0$ and $2\pi$ to repetitive or periodic signals -- is a cornerstone in the analysis of oscillatory signals across diverse fields, from neuroscience to robotics, where it is fundamental, e.g., to understanding coordination in neural networks, cardiorespiratory coupling, and human-robot interaction. However, existing methods are often limited to offline processing and/or constrained to one-dimensional signals. In this paper, we introduce ROPE, which, to the best of our knowledge, is the first phase-estimation algorithm capable of (i) handling signals of arbitrary dimension and (ii) operating in real-time, with minimal error. ROPE identifies repetitions within the signal to segment it into (pseudo-)periods and assigns phase values by performing efficient, tractable searches over previous signal segments. We extensively validate the algorithm on a variety of signal types, including trajectories from chaotic dynamical systems, human motion-capture data, and electrocardiographic recordings. Our results demonstrate that ROPE is robust against noise and signal drift, and achieves significantly superior performance compared to state-of-the-art phase estimation methods. This advancement enables real-time analysis of complex biological rhythms, opening new pathways, for example, for early diagnosis of pathological rhythm disruptions and developing rhythm-based therapeutic interventions in neurological and cardiovascular disorders.
A Personalized Data-Driven Generative Model of Human Motion
Mar 19, 2025



The deployment of autonomous virtual avatars (in extended reality) and robots in human group activities - such as rehabilitation therapy, sports, and manufacturing - is expected to increase as these technologies become more pervasive. Designing cognitive architectures and control strategies to drive these agents requires realistic models of human motion. However, existing models only provide simplified descriptions of human motor behavior. In this work, we propose a fully data-driven approach, based on Long Short-Term Memory neural networks, to generate original motion that captures the unique characteristics of specific individuals. We validate the architecture using real data of scalar oscillatory motion. Extensive analyses show that our model effectively replicates the velocity distribution and amplitude envelopes of the individual it was trained on, remaining different from other individuals, and outperforming state-of-the-art models in terms of similarity to human data.
Data-driven architecture to encode information in the kinematics of robots and artificial avatars
Mar 11, 2024


We present a data-driven control architecture for modifying the kinematics of robots and artificial avatars to encode specific information such as the presence or not of an emotion in the movements of an avatar or robot driven by a human operator. We validate our approach on an experimental dataset obtained during the reach-to-grasp phase of a pick-and-place task.
Guaranteeing Control Requirements via Reward Shaping in Reinforcement Learning
Nov 16, 2023



In addressing control problems such as regulation and tracking through reinforcement learning, it is often required to guarantee that the acquired policy meets essential performance and stability criteria such as a desired settling time and steady-state error prior to deployment. Motivated by this necessity, we present a set of results and a systematic reward shaping procedure that (i) ensures the optimal policy generates trajectories that align with specified control requirements and (ii) allows to assess whether any given policy satisfies them. We validate our approach through comprehensive numerical experiments conducted in two representative environments from OpenAI Gym: the Inverted Pendulum swing-up problem and the Lunar Lander. Utilizing both tabular and deep reinforcement learning methods, our experiments consistently affirm the efficacy of our proposed framework, highlighting its effectiveness in ensuring policy adherence to the prescribed control requirements.
CT-DQN: Control-Tutored Deep Reinforcement Learning
Dec 02, 2022One of the major challenges in Deep Reinforcement Learning for control is the need for extensive training to learn the policy. Motivated by this, we present the design of the Control-Tutored Deep Q-Networks (CT-DQN) algorithm, a Deep Reinforcement Learning algorithm that leverages a control tutor, i.e., an exogenous control law, to reduce learning time. The tutor can be designed using an approximate model of the system, without any assumption about the knowledge of the system's dynamics. There is no expectation that it will be able to achieve the control objective if used stand-alone. During learning, the tutor occasionally suggests an action, thus partially guiding exploration. We validate our approach on three scenarios from OpenAI Gym: the inverted pendulum, lunar lander, and car racing. We demonstrate that CT-DQN is able to achieve better or equivalent data efficiency with respect to the classic function approximation solutions.
Utilizing synchronization to partition power networks into microgrids
Jul 26, 2021
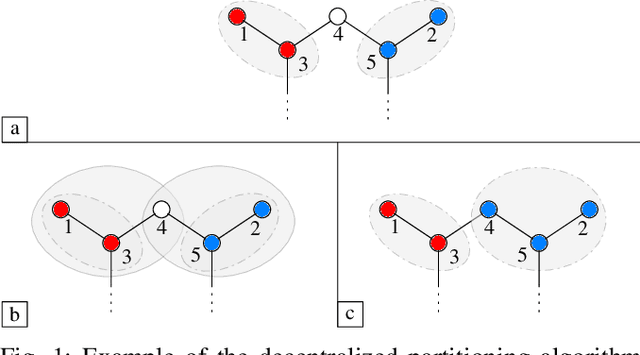
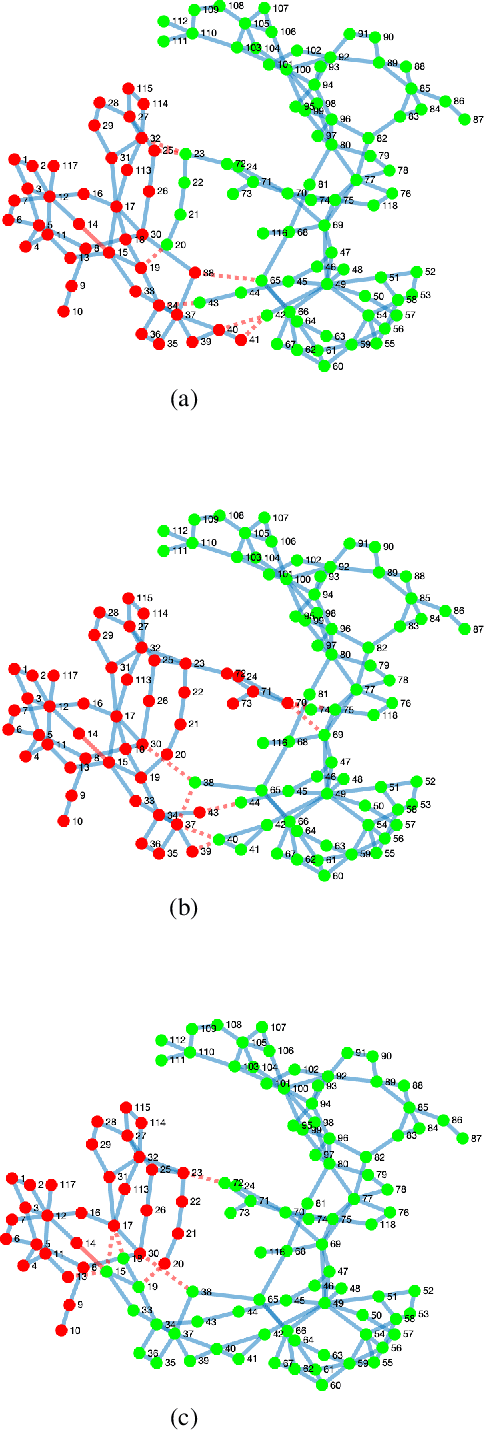
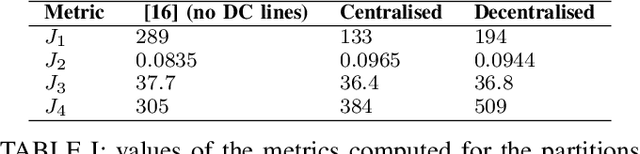
The problem of partitioning a power grid into a set of microgrids, or islands, is of interest for both the design of future smart grids, and as a last resort to restore power dispatchment in sections of a grid affected by an extreme failure. In the literature this problem is usually solved by turning it into a combinatorial optimization problem, often solved through generic heruristic methods such as Genetic Algorithms or Tabu Search. In this paper, we take a different route and obtain the grid partition by exploiting the synchronization dynamics of a cyberlayer of Kuramoto oscillators, each parameterized as a rough approximation of the dynamics of the grid's node it corresponds to. We present first a centralised algorithm and then a decentralised strategy. In the former, nodes are aggregated based on their internode synchronization times while in the latter they exploit synchronization of the oscillators in the cyber layer to selforganise into islands. Our preliminary results show that the heuristic synchronization based algorithms do converge towards partitions that are comparable to those obtained via other more cumbersome and computationally expensive optimization-based methods.
Control of Painlevé Paradox in a Robotic System
Jul 09, 2019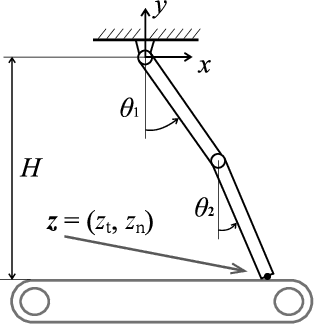
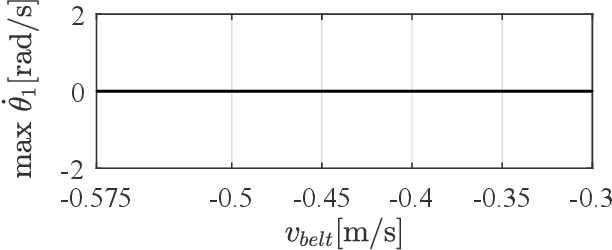
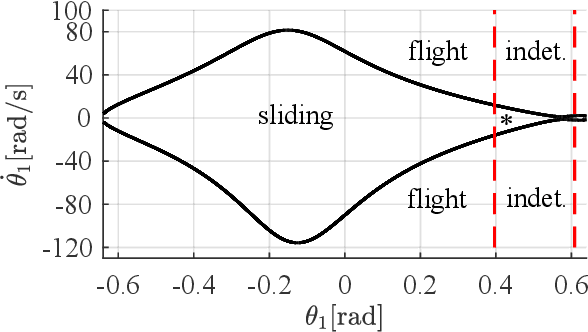
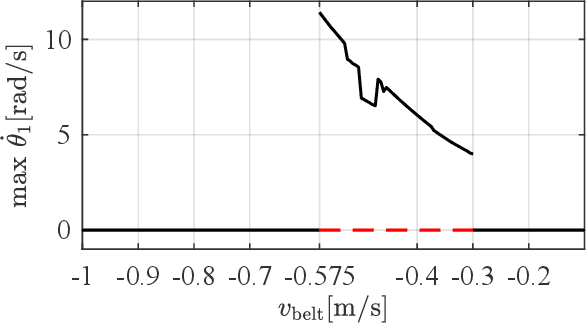
The Painlev\'e paradox is a phenomenon that causes instability in mechanical systems subjects to unilateral constraints. While earlier studies were mostly focused on abstract theoretical settings, recent work confirmed the occurrence of the paradox in realistic set-ups. In this paper, we investigate the dynamics and presence of the Painlev\'e phenomenon in a twolinks robot in contact with a moving belt, through a bifurcation study. Then, we use the results of this analysis to inform the design of control strategies able to keep the robot sliding on the belt and avoid the onset of undesired lift-off. To this aim, through numerical simulations, we synthesise and compare a PID strategy and a hybrid force/motion control scheme, finding that the latter is able to guarantee better performance and avoid the onset of bouncing motion due to the Painlev\'e phenomenon.