Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl-Tutored Reinforcement Learning: an application to the Herding Problem
Paper and Code
Nov 27, 2019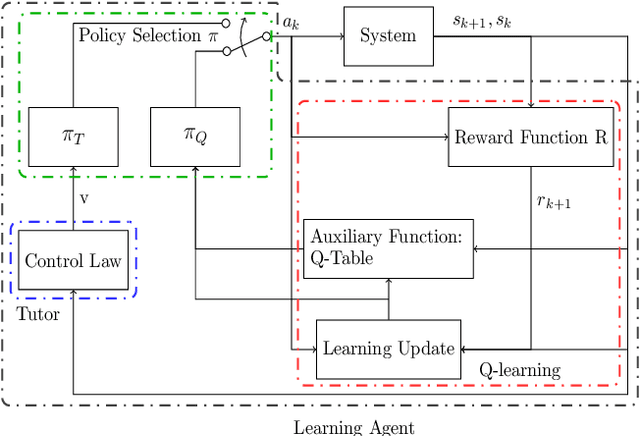
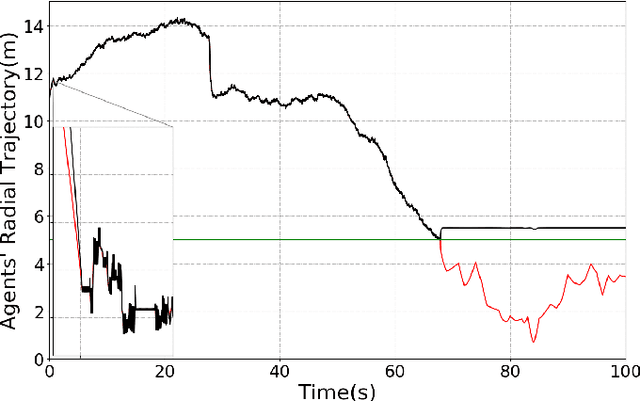
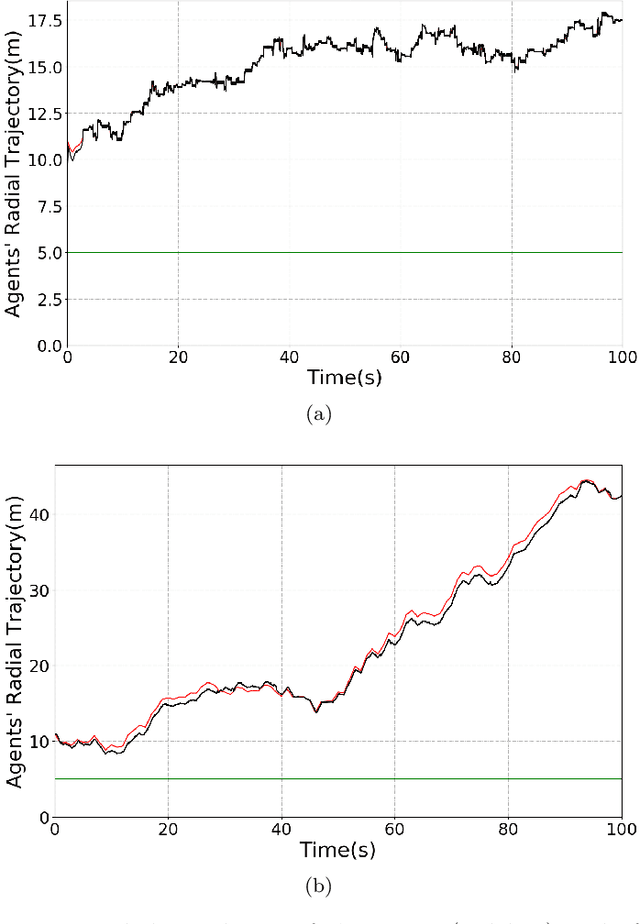
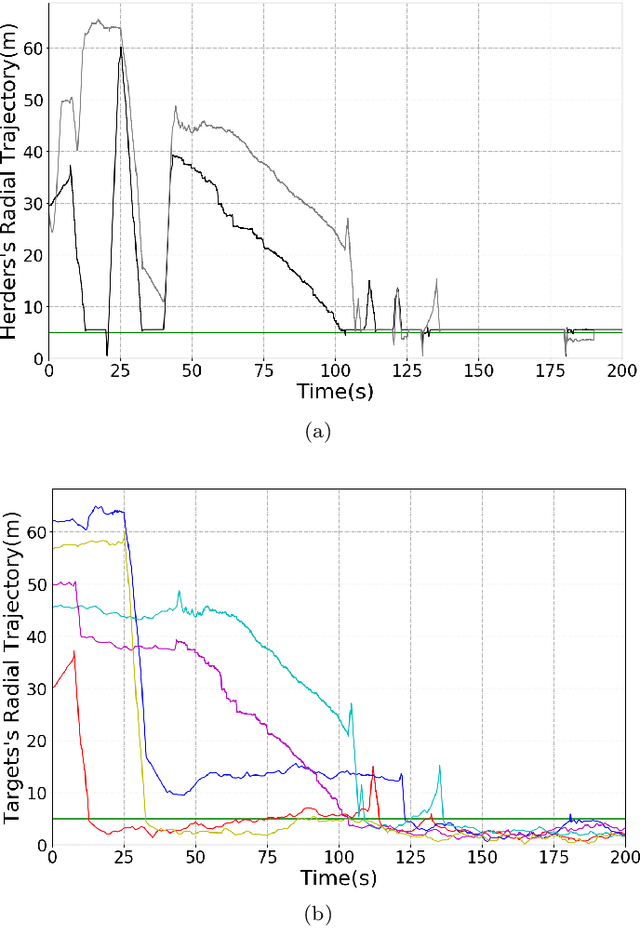
In this extended abstract we introduce a novel control-tutored Q-learning approach (CTQL) as part of the ongoing effort in developing model-based and safe RL for continuous state spaces. We validate our approach by applying it to a challenging multi-agent herding control problem.
View paper on