 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid quantum-classical graph neural networks for tumor classification in digital pathology
Oct 17, 2023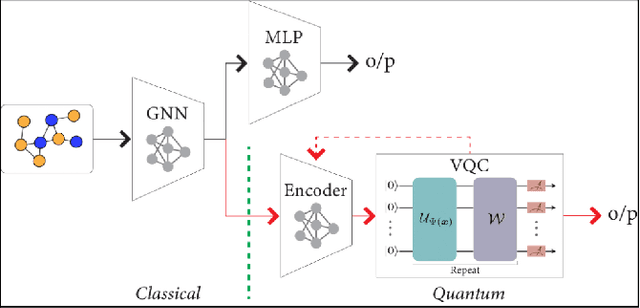
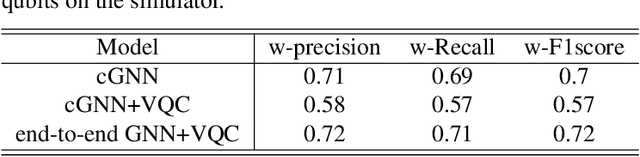
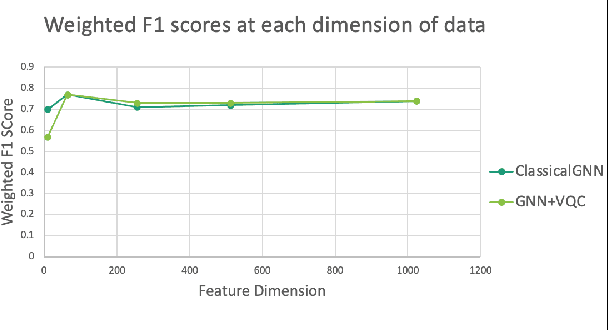
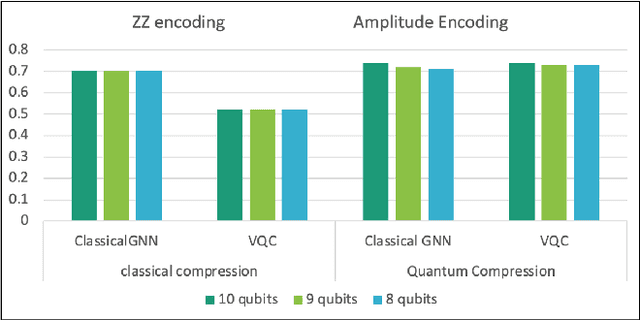
Advances in classical machine learning and single-cell technologies have paved the way to understand interactions between disease cells and tumor microenvironments to accelerate therapeutic discovery. However, challenges in these machine learning methods and NP-hard problems in spatial Biology create an opportunity for quantum computing algorithms. We create a hybrid quantum-classical graph neural network (GNN) that combines GNN with a Variational Quantum Classifier (VQC) for classifying binary sub-tasks in breast cancer subtyping. We explore two variants of the same, the first with fixed pretrained GNN parameters and the second with end-to-end training of GNN+VQC. The results demonstrate that the hybrid quantum neural network (QNN) is at par with the state-of-the-art classical graph neural networks (GNN) in terms of weighted precision, recall and F1-score. We also show that by means of amplitude encoding, we can compress information in logarithmic number of qubits and attain better performance than using classical compression (which leads to information loss while keeping the number of qubits required constant in both regimes). Finally, we show that end-to-end training enables to improve over fixed GNN parameters and also slightly improves over vanilla GNN with same number of dimensions.
Variational Learning for Unsupervised Knowledge Grounded Dialogs
Dec 06, 2021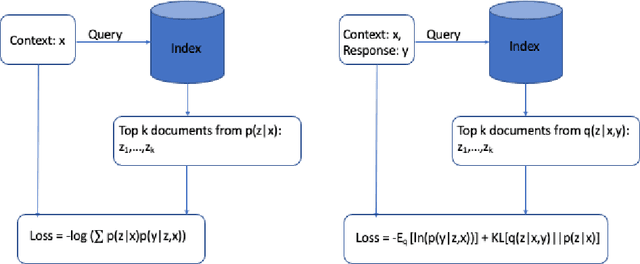
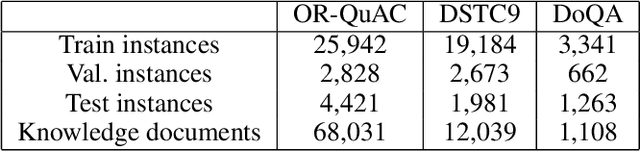
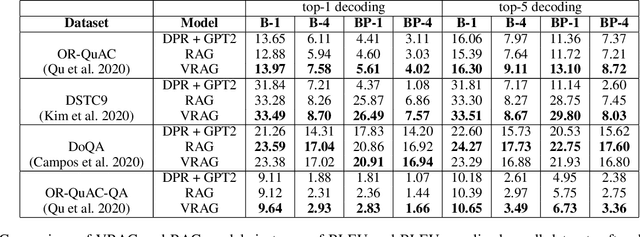
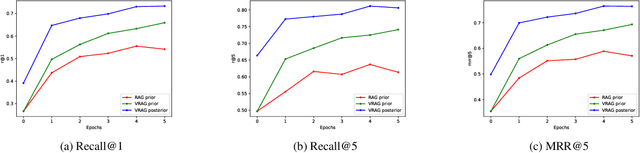
Recent methods for knowledge grounded dialogs generate responses by incorporating information from an external textual document. These methods do not require the exact document to be known during training and rely on the use of a retrieval system to fetch relevant documents from a large index. The documents used to generate the responses are modeled as latent variables whose prior probabilities need to be estimated. Models such as RAG , marginalize the document probabilities over the documents retrieved from the index to define the log likelihood loss function which is optimized end-to-end. In this paper, we develop a variational approach to the above technique wherein, we instead maximize the Evidence Lower bound (ELBO). Using a collection of three publicly available open-conversation datasets, we demonstrate how the posterior distribution, that has information from the ground-truth response, allows for a better approximation of the objective function during training. To overcome the challenges associated with sampling over a large knowledge collection, we develop an efficient approach to approximate the ELBO. To the best of our knowledge we are the first to apply variational training for open-scale unsupervised knowledge grounded dialog systems.
Unsupervised Learning of Interpretable Dialog Models
Nov 02, 2018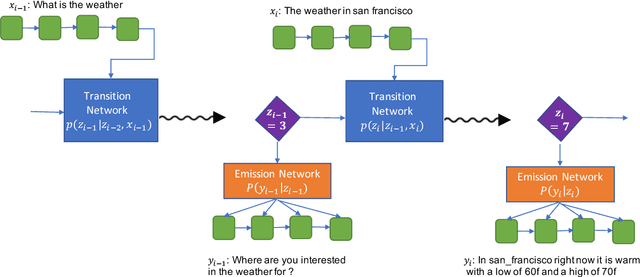
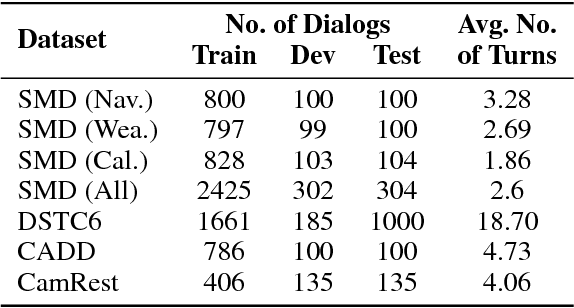
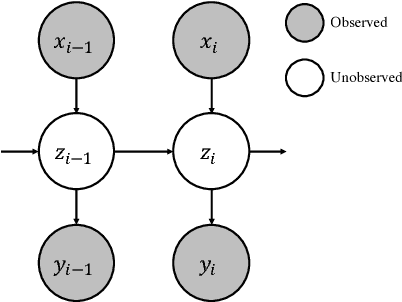
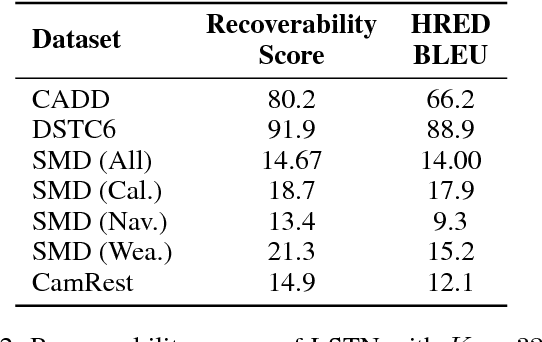
Recently several deep learning based models have been proposed for end-to-end learning of dialogs. While these models can be trained from data without the need for any additional annotations, it is hard to interpret them. On the other hand, there exist traditional state based dialog systems, where the states of the dialog are discrete and hence easy to interpret. However these states need to be handcrafted and annotated in the data. To achieve the best of both worlds, we propose Latent State Tracking Network (LSTN) using which we learn an interpretable model in unsupervised manner. The model defines a discrete latent variable at each turn of the conversation which can take a finite set of values. Since these discrete variables are not present in the training data, we use EM algorithm to train our model in unsupervised manner. In the experiments, we show that LSTN can help achieve interpretability in dialog models without much decrease in performance compared to end-to-end approaches.
Finding Dominant User Utterances And System Responses in Conversations
Oct 29, 2017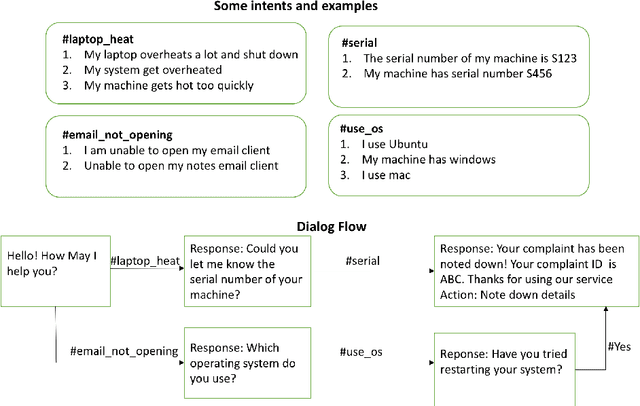
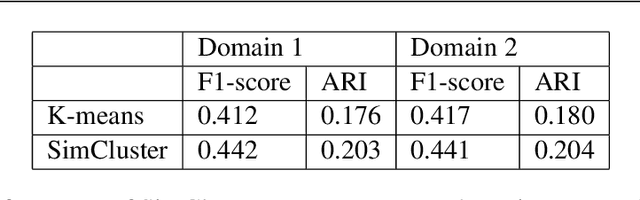
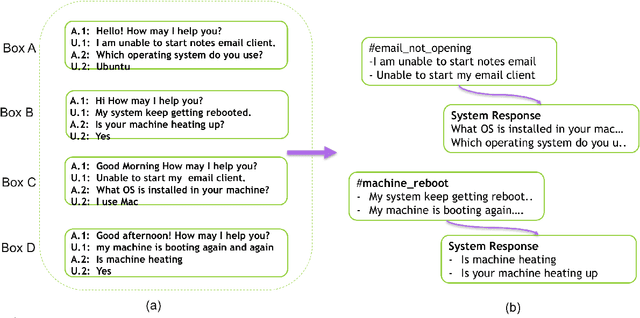
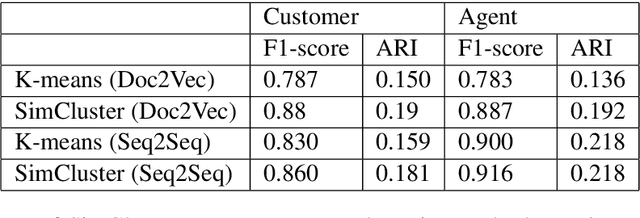
There are several dialog frameworks which allow manual specification of intents and rule based dialog flow. The rule based framework provides good control to dialog designers at the expense of being more time consuming and laborious. The job of a dialog designer can be reduced if we could identify pairs of user intents and corresponding responses automatically from prior conversations between users and agents. In this paper we propose an approach to find these frequent user utterances (which serve as examples for intents) and corresponding agent responses. We propose a novel SimCluster algorithm that extends standard K-means algorithm to simultaneously cluster user utterances and agent utterances by taking their adjacency information into account. The method also aligns these clusters to provide pairs of intents and response groups. We compare our results with those produced by using simple Kmeans clustering on a real dataset and observe upto 10% absolute improvement in F1-scores. Through our experiments on synthetic dataset, we show that our algorithm gains more advantage over K-means algorithm when the data has large variance.