 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Beware of deception": Detecting Half-Truth and Debunking it through Controlled Claim Editing
Aug 15, 2023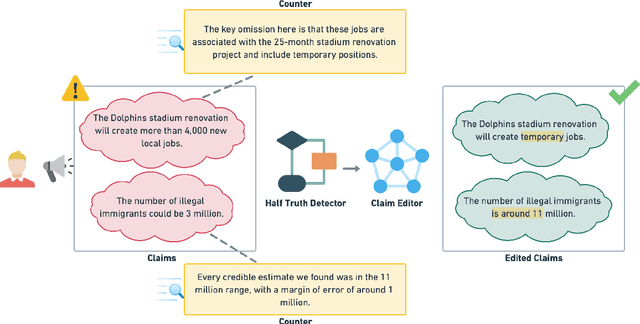
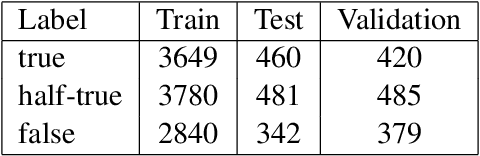


The prevalence of half-truths, which are statements containing some truth but that are ultimately deceptive, has risen with the increasing use of the internet. To help combat this problem, we have created a comprehensive pipeline consisting of a half-truth detection model and a claim editing model. Our approach utilizes the T5 model for controlled claim editing; "controlled" here means precise adjustments to select parts of a claim. Our methodology achieves an average BLEU score of 0.88 (on a scale of 0-1) and a disinfo-debunk score of 85% on edited claims. Significantly, our T5-based approach outperforms other Language Models such as GPT2, RoBERTa, PEGASUS, and Tailor, with average improvements of 82%, 57%, 42%, and 23% in disinfo-debunk scores, respectively. By extending the LIAR PLUS dataset, we achieve an F1 score of 82% for the half-truth detection model, setting a new benchmark in the field. While previous attempts have been made at half-truth detection, our approach is, to the best of our knowledge, the first to attempt to debunk half-truths.
Harnessing Abstractive Summarization for Fact-Checked Claim Detection
Sep 14, 2022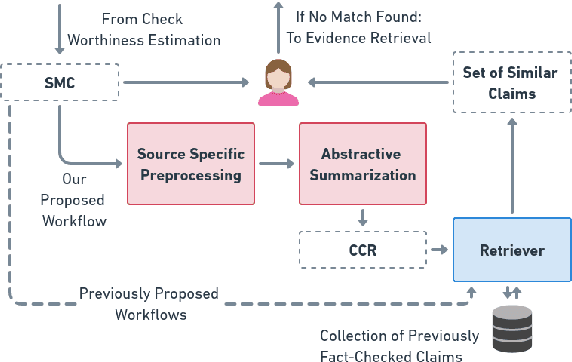
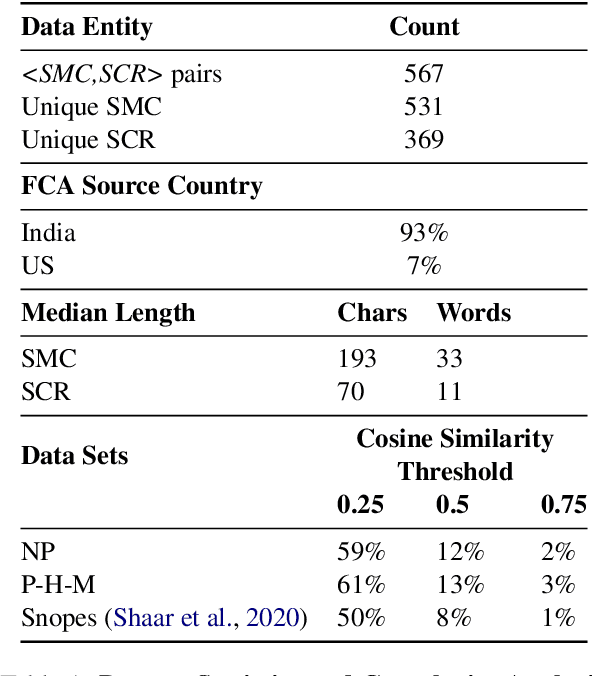
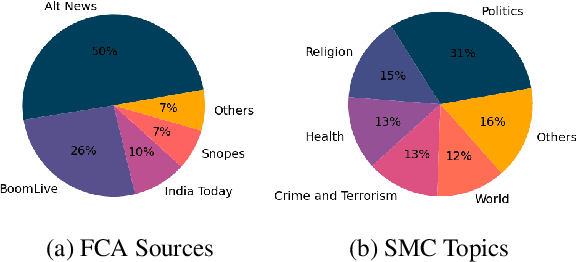
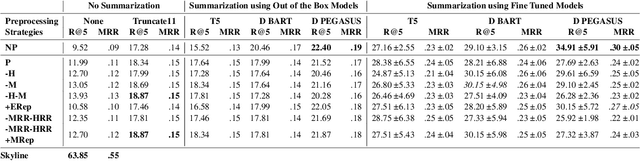
Social media platforms have become new battlegrounds for anti-social elements, with misinformation being the weapon of choice. Fact-checking organizations try to debunk as many claims as possible while staying true to their journalistic processes but cannot cope with its rapid dissemination. We believe that the solution lies in partial automation of the fact-checking life cycle, saving human time for tasks which require high cognition. We propose a new workflow for efficiently detecting previously fact-checked claims that uses abstractive summarization to generate crisp queries. These queries can then be executed on a general-purpose retrieval system associated with a collection of previously fact-checked claims. We curate an abstractive text summarization dataset comprising noisy claims from Twitter and their gold summaries. It is shown that retrieval performance improves 2x by using popular out-of-the-box summarization models and 3x by fine-tuning them on the accompanying dataset compared to verbatim querying. Our approach achieves Recall@5 and MRR of 35% and 0.3, compared to baseline values of 10% and 0.1, respectively. Our dataset, code, and models are available publicly: https://github.com/varadhbhatnagar/FC-Claim-Det/
Video Summarization: Study of various techniques
Jan 21, 2021A comparative study of various techniques which can be used for summarization of Videos i.e. Video to Video conversion is presented along with respective architecture, results, strengths and shortcomings. In all approaches, a lengthy video is converted into a shorter video which aims to capture all important events that are present in the original video. The definition of 'important event' may vary according to the context, such as a sports video and a documentary may have different events which are classified as important.
Divide and Conquer: An Ensemble Approach for Hostile Post Detection in Hindi
Jan 20, 2021
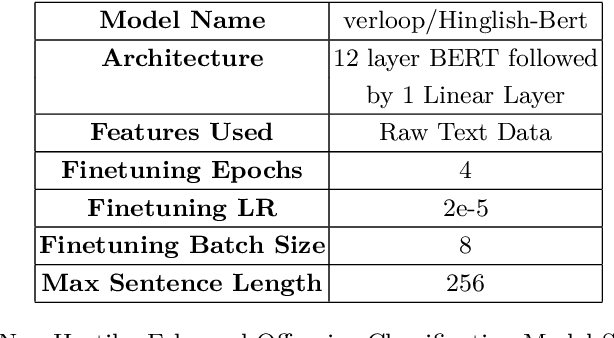


Recently the NLP community has started showing interest towards the challenging task of Hostile Post Detection. This paper present our system for Shared Task at Constraint2021 on "Hostile Post Detection in Hindi". The data for this shared task is provided in Hindi Devanagari script which was collected from Twitter and Facebook. It is a multi-label multi-class classification problem where each data instance is annotated into one or more of the five classes: fake, hate, offensive, defamation, and non-hostile. We propose a two level architecture which is made up of BERT based classifiers and statistical classifiers to solve this problem. Our team 'Albatross', scored 0.9709 Coarse grained hostility F1 score measure on Hostile Post Detection in Hindi subtask and secured 2nd rank out of 45 teams for the task. Our submission is ranked 2nd and 3rd out of a total of 156 submissions with Coarse grained hostility F1 score of 0.9709 and 0.9703 respectively. Our fine grained scores are also very encouraging and can be improved with further finetuning. The code is publicly available.