 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFL: Causally Fair Language Models Through Token-level Attribute Controlled Generation
Paper and Code

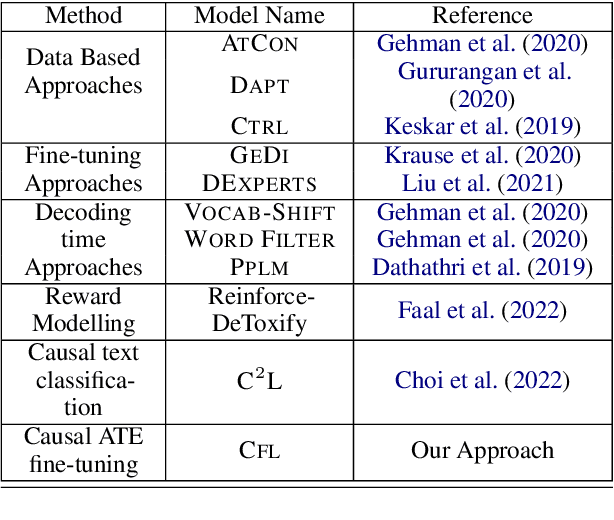
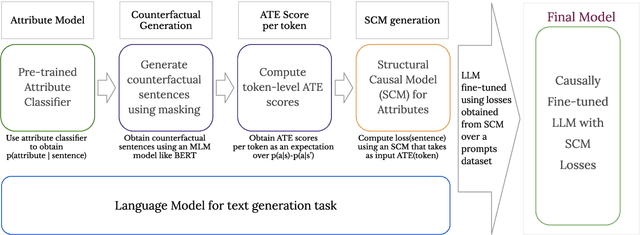
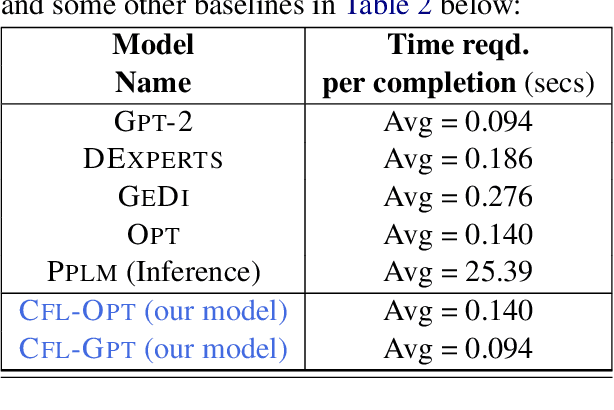
We propose a method to control the attributes of Language Models (LMs) for the text generation task using Causal Average Treatment Effect (ATE) scores and counterfactual augmentation. We explore this method, in the context of LM detoxification, and propose the Causally Fair Language (CFL) architecture for detoxifying pre-trained LMs in a plug-and-play manner. Our architecture is based on a Structural Causal Model (SCM) that is mathematically transparent and computationally efficient as compared with many existing detoxification techniques. We also propose several new metrics that aim to better understand the behaviour of LMs in the context of toxic text generation. Further, we achieve state of the art performance for toxic degeneration, which are computed using \RTP (RTP) benchmark. Our experiments show that CFL achieves such a detoxification without much impact on the model perplexity. We also show that CFL mitigates the unintended bias problem through experiments on the BOLD dataset.