 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardening Deep Neural Networks via Adversarial Model Cascades
Paper and Code
Nov 04, 2018
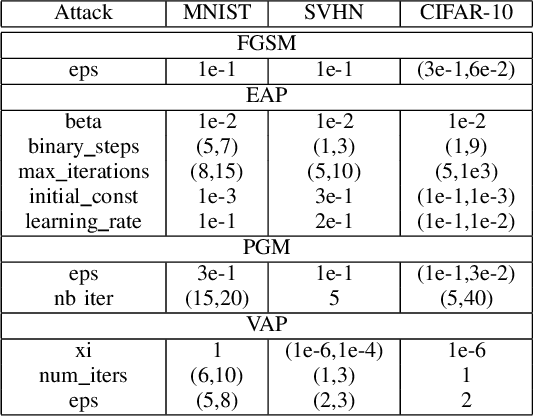
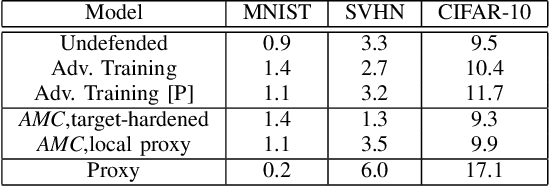
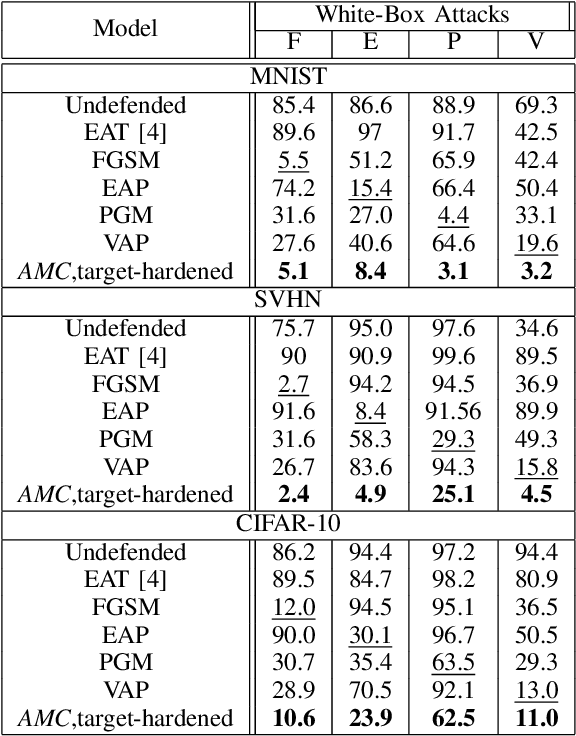
Deep neural networks (DNNs) are vulnerable to malicious inputs crafted by an adversary to produce erroneous outputs. Works on securing neural networks against adversarial examples achieve high empirical robustness on simple datasets such as MNIST. However, these techniques are inadequate when empirically tested on complex data sets such as CIFAR-10 and SVHN. Further, existing techniques are designed to target specific attacks and fail to generalize across attacks. We propose the Adversarial Model Cascades (AMC) as a way to tackle the above inadequacies. Our approach trains a cascade of models sequentially where each model is optimized to be robust towards a mixture of multiple attacks. Ultimately, it yields a single model which is secure against a wide range of attacks; namely FGSM, Elastic, Virtual Adversarial Perturbations and Madry. On an average, AMC increases the model's empirical robustness against various attacks simultaneously, by a significant margin (of 6.225% for MNIST, 5.075% for SVHN and 2.65% for CIFAR10). At the same time, the model's performance on non-adversarial inputs is comparable to the state-of-the-art models.