 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTradingAgents: Multi-Agents LLM Financial Trading Framework
Dec 28, 2024



Significant progress has been made in automated problem-solving using societies of agents powered by large language models (LLMs). In finance, efforts have largely focused on single-agent systems handling specific tasks or multi-agent frameworks independently gathering data. However, multi-agent systems' potential to replicate real-world trading firms' collaborative dynamics remains underexplored. TradingAgents proposes a novel stock trading framework inspired by trading firms, featuring LLM-powered agents in specialized roles such as fundamental analysts, sentiment analysts, technical analysts, and traders with varied risk profiles. The framework includes Bull and Bear researcher agents assessing market conditions, a risk management team monitoring exposure, and traders synthesizing insights from debates and historical data to make informed decisions. By simulating a dynamic, collaborative trading environment, this framework aims to improve trading performance. Detailed architecture and extensive experiments reveal its superiority over baseline models, with notable improvements in cumulative returns, Sharpe ratio, and maximum drawdown, highlighting the potential of multi-agent LLM frameworks in financial trading.
ProteinGPT: Multimodal LLM for Protein Property Prediction and Structure Understanding
Aug 21, 2024Understanding biological processes, drug development, and biotechnological advancements requires detailed analysis of protein structures and sequences, a task in protein research that is inherently complex and time-consuming when performed manually. To streamline this process, we introduce ProteinGPT, a state-of-the-art multi-modal protein chat system, that allows users to upload protein sequences and/or structures for comprehensive protein analysis and responsive inquiries. ProteinGPT seamlessly integrates protein sequence and structure encoders with linear projection layers for precise representation adaptation, coupled with a large language model (LLM) to generate accurate and contextually relevant responses. To train ProteinGPT, we construct a large-scale dataset of 132,092 proteins with annotations, and optimize the instruction-tuning process using GPT-4o. This innovative system ensures accurate alignment between the user-uploaded data and prompts, simplifying protein analysis. Experiments show that ProteinGPT can produce promising responses to proteins and their corresponding questions.
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
Jul 06, 2024We propose LogicVista, an evaluation benchmark that assesses the integrated logical reasoning capabilities of multimodal large language models (MLLMs) in Visual contexts. Recent advancements in MLLMs have demonstrated various fascinating abilities, from crafting poetry based on an image to performing mathematical reasoning. However, there is still a lack of systematic evaluation of MLLMs' proficiency in logical reasoning tasks, which are essential for activities like navigation and puzzle-solving. Thus we evaluate general logical cognition abilities across 5 logical reasoning tasks encompassing 9 different capabilities, using a sample of 448 multiple-choice questions. Each question is annotated with the correct answer and the human-written reasoning behind the selection, enabling both open-ended and multiple-choice evaluation. A total of 8 MLLMs are comprehensively evaluated using LogicVista. Code and Data Available at https://github.com/Yijia-Xiao/LogicVista.
Towards Improving Learning from Demonstration Algorithms via MCMC Methods
May 03, 2024Behavioral cloning, or more broadly, learning from demonstrations (LfD) is a priomising direction for robot policy learning in complex scenarios. Albeit being straightforward to implement and data-efficient, behavioral cloning has its own drawbacks, limiting its efficacy in real robot setups. In this work, we take one step towards improving learning from demonstration algorithms by leveraging implicit energy-based policy models. Results suggest that in selected complex robot policy learning scenarios, treating supervised policy learning with an implicit model generally performs better, on average, than commonly used neural network-based explicit models, especially in the cases of approximating potentially discontinuous and multimodal functions.
Data Cross-Segmentation for Improved Generalization in Reinforcement Learning Based Algorithmic Trading
Jul 18, 2023


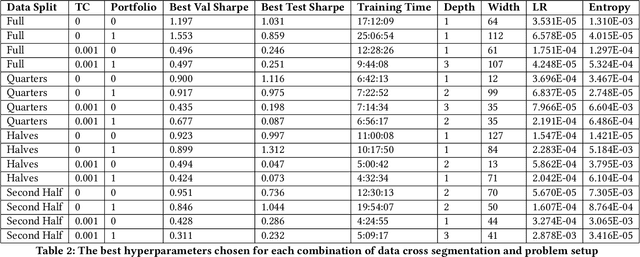
The use of machine learning in algorithmic trading systems is increasingly common. In a typical set-up, supervised learning is used to predict the future prices of assets, and those predictions drive a simple trading and execution strategy. This is quite effective when the predictions have sufficient signal, markets are liquid, and transaction costs are low. However, those conditions often do not hold in thinly traded financial markets and markets for differentiated assets such as real estate or vehicles. In these markets, the trading strategy must consider the long-term effects of taking positions that are relatively more difficult to change. In this work, we propose a Reinforcement Learning (RL) algorithm that trades based on signals from a learned predictive model and addresses these challenges. We test our algorithm on 20+ years of equity data from Bursa Malaysia.
D2S: Document-to-Slide Generation Via Query-Based Text Summarization
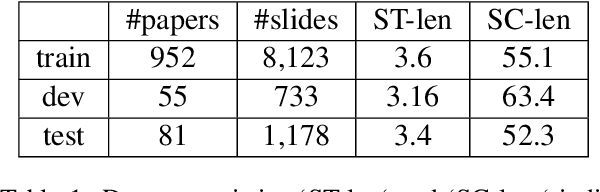
May 08, 2021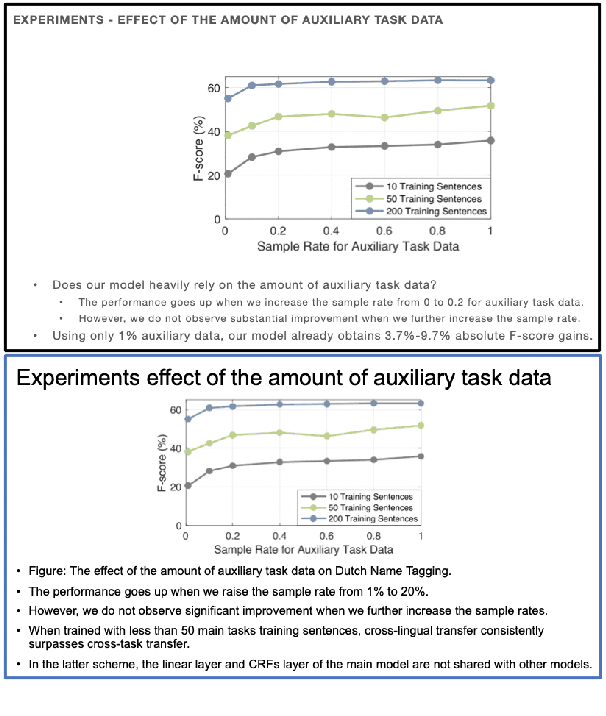

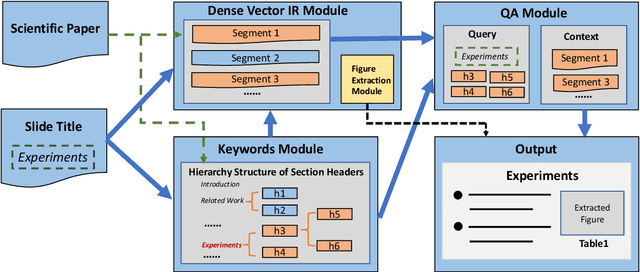
Presentations are critical for communication in all areas of our lives, yet the creation of slide decks is often tedious and time-consuming. There has been limited research aiming to automate the document-to-slides generation process and all face a critical challenge: no publicly available dataset for training and benchmarking. In this work, we first contribute a new dataset, SciDuet, consisting of pairs of papers and their corresponding slides decks from recent years' NLP and ML conferences (e.g., ACL). Secondly, we present D2S, a novel system that tackles the document-to-slides task with a two-step approach: 1) Use slide titles to retrieve relevant and engaging text, figures, and tables; 2) Summarize the retrieved context into bullet points with long-form question answering. Our evaluation suggests that long-form QA outperforms state-of-the-art summarization baselines on both automated ROUGE metrics and qualitative human evaluation.