 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Representation Learning using Interpolation Enabled Disentanglement
Paper and Code
Jul 31, 2021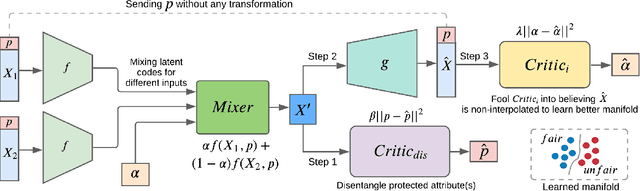

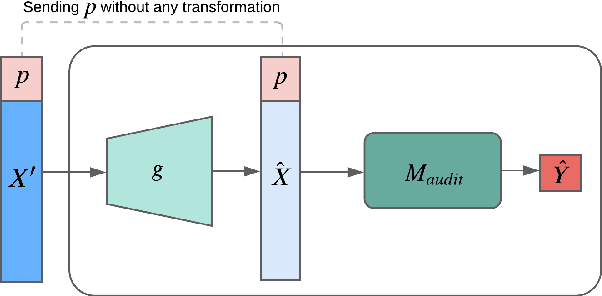
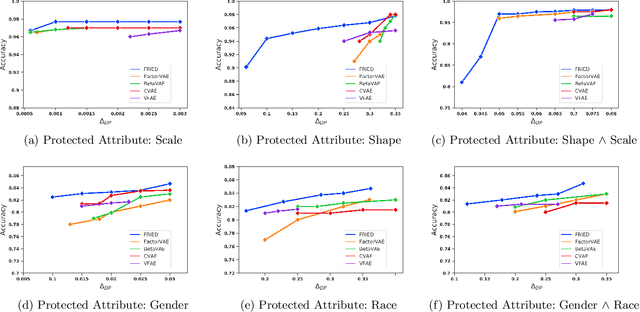
With the growing interest in the machine learning community to solve real-world problems, it has become crucial to uncover the hidden reasoning behind their decisions by focusing on the fairness and auditing the predictions made by these black-box models. In this paper, we propose a novel method to address two key issues: (a) Can we simultaneously learn fair disentangled representations while ensuring the utility of the learned representation for downstream tasks, and (b)Can we provide theoretical insights into when the proposed approach will be both fair and accurate. To address the former, we propose the method FRIED, Fair Representation learning using Interpolation Enabled Disentanglement. In our architecture, by imposing a critic-based adversarial framework, we enforce the interpolated points in the latent space to be more realistic. This helps in capturing the data manifold effectively and enhances the utility of the learned representation for downstream prediction tasks. We address the latter question by developing a theory on fairness-accuracy trade-offs using classifier-based conditional mutual information estimation. We demonstrate the effectiveness of FRIED on datasets of different modalities - tabular, text, and image datasets. We observe that the representations learned by FRIED are overall fairer in comparison to existing baselines and also accurate for downstream prediction tasks. Additionally, we evaluate FRIED on a real-world healthcare claims dataset where we conduct an expert aided model auditing study providing useful insights into opioid ad-diction patterns.