 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDraw Like an Artist: Complex Scene Generation with Diffusion Model via Composition, Painting, and Retouching
Paper and Code
Aug 25, 2024
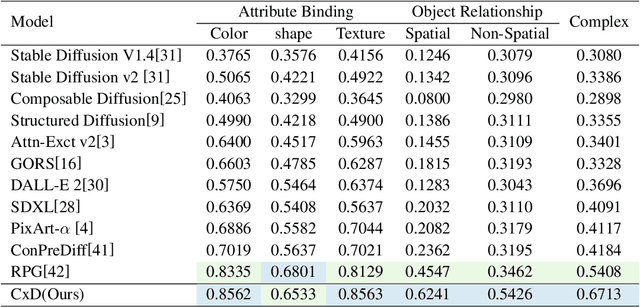
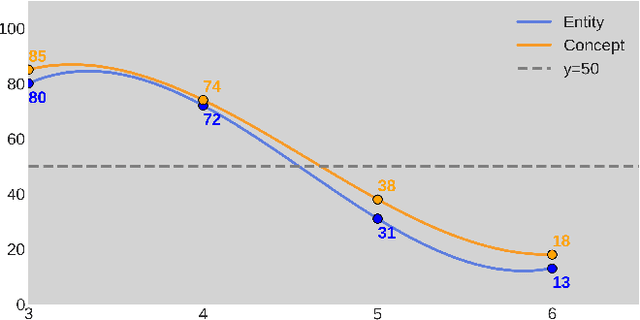
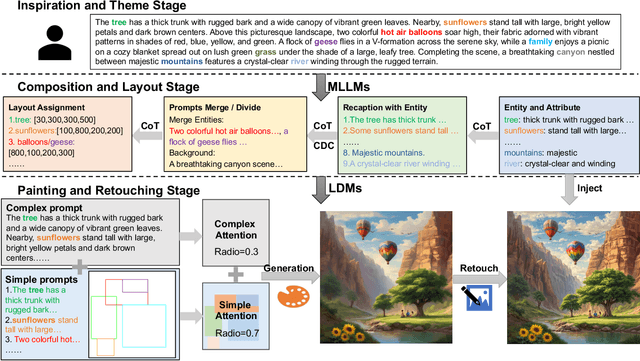
Recent advances in text-to-image diffusion models have demonstrated impressive capabilities in image quality. However, complex scene generation remains relatively unexplored, and even the definition of `complex scene' itself remains unclear. In this paper, we address this gap by providing a precise definition of complex scenes and introducing a set of Complex Decomposition Criteria (CDC) based on this definition. Inspired by the artists painting process, we propose a training-free diffusion framework called Complex Diffusion (CxD), which divides the process into three stages: composition, painting, and retouching. Our method leverages the powerful chain-of-thought capabilities of large language models (LLMs) to decompose complex prompts based on CDC and to manage composition and layout. We then develop an attention modulation method that guides simple prompts to specific regions to complete the complex scene painting. Finally, we inject the detailed output of the LLM into a retouching model to enhance the image details, thus implementing the retouching stage. Extensive experiments demonstrate that our method outperforms previous SOTA approaches, significantly improving the generation of high-quality, semantically consistent, and visually diverse images for complex scenes, even with intricate prompts.