 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotorealistic Lip Sync with Adversarial Temporal Convolutional Networks
Paper and Code
Feb 20, 2020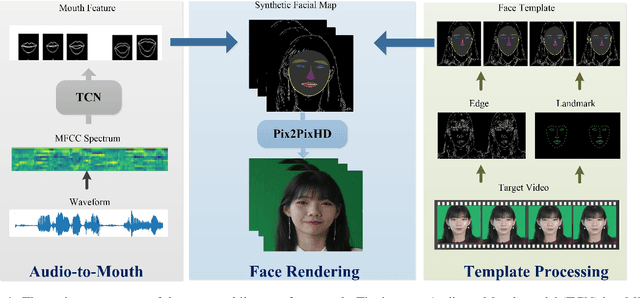

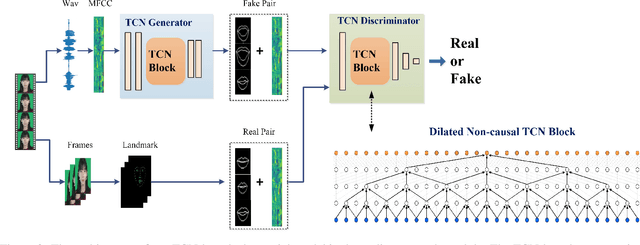

Lip sync has emerged as a promising technique to generate mouth movements on a talking head. However, synthesizing a clear, accurate and human-like performance is still challenging. In this paper, we present a novel lip-sync solution for producing a high-quality and photorealistic talking head from speech. We focus on capturing the specific lip movement and talking style of the target person. We model the seq-to-seq mapping from audio signals to mouth features by two adversarial temporal convolutional networks. Experiments show our model outperforms traditional RNN-based baselines in both accuracy and speed. We also propose an image-to-image translation-based approach for generating high-resolution photoreal face appearance from synthetic facial maps. This fully-trainable framework not only avoids the cumbersome steps like candidate-frame selection in graphics-based rendering methods but also solves some existing issues in recent neural network-based solutions. Our work will benefit related applications such as conversational agent, virtual anchor, tele-presence and gaming.