 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlazeBVD: Make Scale-Time Equalization Great Again for Blind Video Deflickering
Mar 10, 2024



Developing blind video deflickering (BVD) algorithms to enhance video temporal consistency, is gaining importance amid the flourish of image processing and video generation. However, the intricate nature of video data complicates the training of deep learning methods, leading to high resource consumption and instability, notably under severe lighting flicker. This underscores the critical need for a compact representation beyond pixel values to advance BVD research and applications. Inspired by the classic scale-time equalization (STE), our work introduces the histogram-assisted solution, called BlazeBVD, for high-fidelity and rapid BVD. Compared with STE, which directly corrects pixel values by temporally smoothing color histograms, BlazeBVD leverages smoothed illumination histograms within STE filtering to ease the challenge of learning temporal data using neural networks. In technique, BlazeBVD begins by condensing pixel values into illumination histograms that precisely capture flickering and local exposure variations. These histograms are then smoothed to produce singular frames set, filtered illumination maps, and exposure maps. Resorting to these deflickering priors, BlazeBVD utilizes a 2D network to restore faithful and consistent texture impacted by lighting changes or localized exposure issues. BlazeBVD also incorporates a lightweight 3D network to amend slight temporal inconsistencies, avoiding the resource consumption issue. Comprehensive experiments on synthetic, real-world and generated videos, showcase the superior qualitative and quantitative results of BlazeBVD, achieving inference speeds up to 10x faster than state-of-the-arts.
Precise Box Score: Extract More Information from Datasets to Improve the Performance of Face Detection
Apr 28, 2018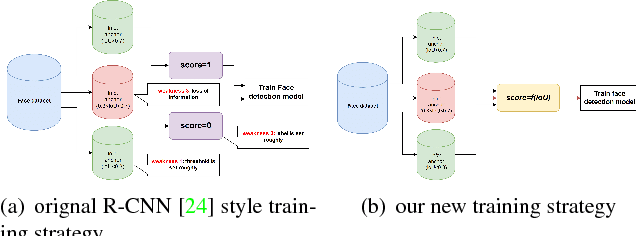
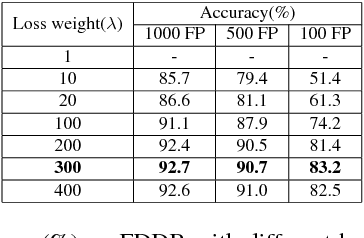
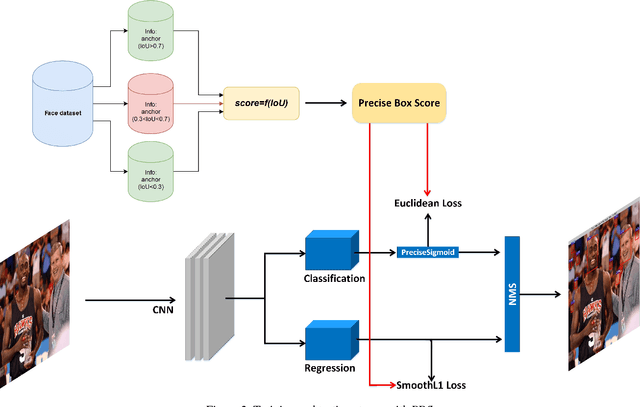
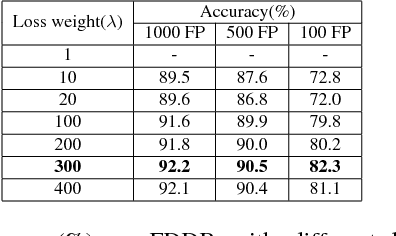
For the training of face detection network based on R-CNN framework, anchors are assigned to be positive samples if intersection-over-unions (IoUs) with ground-truth are higher than the first threshold(such as 0.7); and to be negative samples if their IoUs are lower than the second threshold(such as 0.3). And the face detection model is trained by the above labels. However, anchors with IoU between first threshold and second threshold are not used. We propose a novel training strategy, Precise Box Score(PBS), to train object detection models. The proposed training strategy uses the anchors with IoUs between the first and second threshold, which can consistently improve the performance of face detection. Our proposed training strategy extracts more information from datasets, making better utilization of existing datasets. What's more, we also introduce a simple but effective model compression method(SEMCM), which can boost the performance of face detectors further. Experimental results show that the performance of face detection network can consistently be improved based on our proposed scheme.