 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
LanEvil: Benchmarking the Robustness of Lane Detection to Environmental Illusions
Jun 04, 2024



Lane detection (LD) is an essential component of autonomous driving systems, providing fundamental functionalities like adaptive cruise control and automated lane centering. Existing LD benchmarks primarily focus on evaluating common cases, neglecting the robustness of LD models against environmental illusions such as shadows and tire marks on the road. This research gap poses significant safety challenges since these illusions exist naturally in real-world traffic situations. For the first time, this paper studies the potential threats caused by these environmental illusions to LD and establishes the first comprehensive benchmark LanEvil for evaluating the robustness of LD against this natural corruption. We systematically design 14 prevalent yet critical types of environmental illusions (e.g., shadow, reflection) that cover a wide spectrum of real-world influencing factors in LD tasks. Based on real-world environments, we create 94 realistic and customizable 3D cases using the widely used CARLA simulator, resulting in a dataset comprising 90,292 sampled images. Through extensive experiments, we benchmark the robustness of popular LD methods using LanEvil, revealing substantial performance degradation (-5.37% Accuracy and -10.70% F1-Score on average), with shadow effects posing the greatest risk (-7.39% Accuracy). Additionally, we assess the performance of commercial auto-driving systems OpenPilot and Apollo through collaborative simulations, demonstrating that proposed environmental illusions can lead to incorrect decisions and potential traffic accidents. To defend against environmental illusions, we propose the Attention Area Mixing (AAM) approach using hard examples, which witness significant robustness improvement (+3.76%) under illumination effects. We hope our paper can contribute to advancing more robust auto-driving systems in the future. Website: https://lanevil.github.io/.
Towards Real-world X-ray Security Inspection: A High-Quality Benchmark and Lateral Inhibition Module for Prohibited Items Detection
Aug 23, 2021
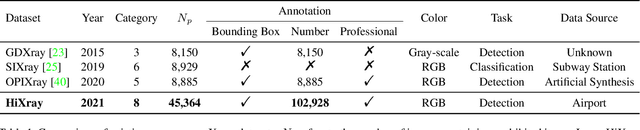
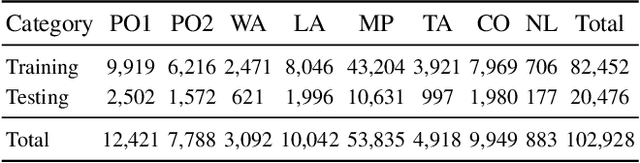

Prohibited items detection in X-ray images often plays an important role in protecting public safety, which often deals with color-monotonous and luster-insufficient objects, resulting in unsatisfactory performance. Till now, there have been rare studies touching this topic due to the lack of specialized high-quality datasets. In this work, we first present a High-quality X-ray (HiXray) security inspection image dataset, which contains 102,928 common prohibited items of 8 categories. It is the largest dataset of high quality for prohibited items detection, gathered from the real-world airport security inspection and annotated by professional security inspectors. Besides, for accurate prohibited item detection, we further propose the Lateral Inhibition Module (LIM) inspired by the fact that humans recognize these items by ignoring irrelevant information and focusing on identifiable characteristics, especially when objects are overlapped with each other. Specifically, LIM, the elaborately designed flexible additional module, suppresses the noisy information flowing maximumly by the Bidirectional Propagation (BP) module and activates the most identifiable charismatic, boundary, from four directions by Boundary Activation (BA) module. We evaluate our method extensively on HiXray and OPIXray and the results demonstrate that it outperforms SOTA detection methods.
Multi-Pretext Attention Network for Few-shot Learning with Self-supervision
Mar 10, 2021

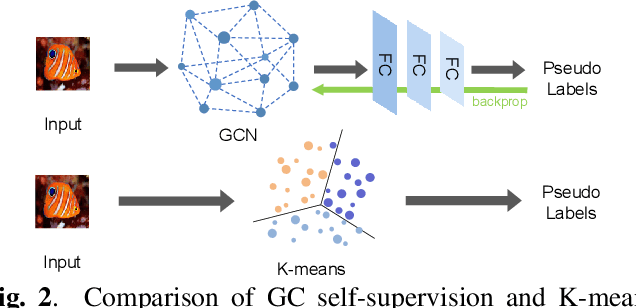

Few-shot learning is an interesting and challenging study, which enables machines to learn from few samples like humans. Existing studies rarely exploit auxiliary information from large amount of unlabeled data. Self-supervised learning is emerged as an efficient method to utilize unlabeled data. Existing self-supervised learning methods always rely on the combination of geometric transformations for the single sample by augmentation, while seriously neglect the endogenous correlation information among different samples that is the same important for the task. In this work, we propose a Graph-driven Clustering (GC), a novel augmentation-free method for self-supervised learning, which does not rely on any auxiliary sample and utilizes the endogenous correlation information among input samples. Besides, we propose Multi-pretext Attention Network (MAN), which exploits a specific attention mechanism to combine the traditional augmentation-relied methods and our GC, adaptively learning their optimized weights to improve the performance and enabling the feature extractor to obtain more universal representations. We evaluate our MAN extensively on miniImageNet and tieredImageNet datasets and the results demonstrate that the proposed method outperforms the state-of-the-art (SOTA) relevant methods.
Over-sampling De-occlusion Attention Network for Prohibited Items Detection in Noisy X-ray Images
Mar 01, 2021
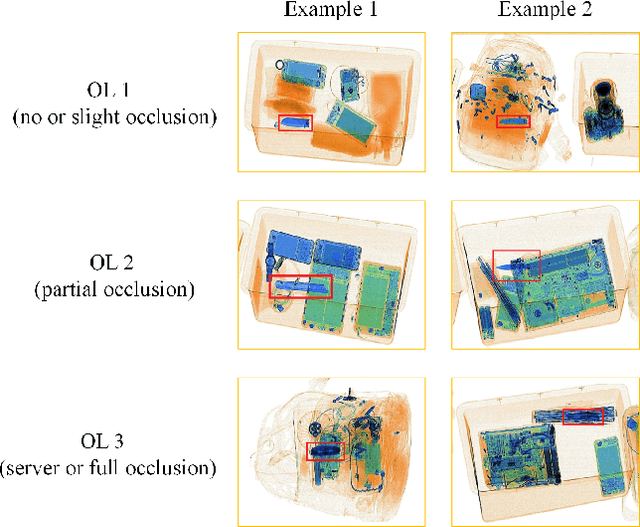
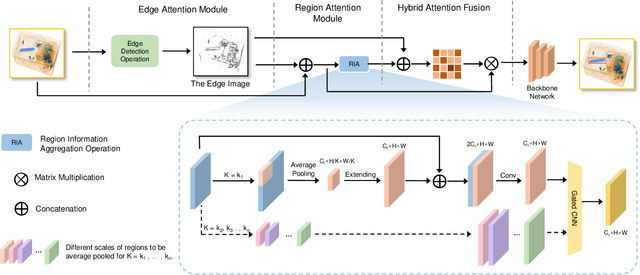
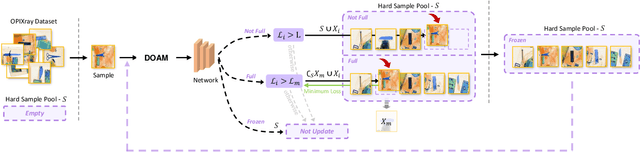
Security inspection is X-ray scanning for personal belongings in suitcases, which is significantly important for the public security but highly time-consuming for human inspectors. Fortunately, deep learning has greatly promoted the development of computer vision, offering a possible way of automatic security inspection. However, items within a luggage are randomly overlapped resulting in noisy X-ray images with heavy occlusions. Thus, traditional CNN-based models trained through common image recognition datasets fail to achieve satisfactory performance in this scenario. To address these problems, we contribute the first high-quality prohibited X-ray object detection dataset named OPIXray, which contains 8885 X-ray images from 5 categories of the widely-occurred prohibited item ``cutters''. The images are gathered from an airport and these prohibited items are annotated manually by professional inspectors, which can be used as a benchmark for model training and further facilitate future research. To better improve occluded X-ray object detection, we further propose an over-sampling de-occlusion attention network (DOAM-O), which consists of a novel de-occlusion attention module and a new over-sampling training strategy. Specifically, our de-occlusion module, namely DOAM, simultaneously leverages the different appearance information of the prohibited items; the over-sampling training strategy forces the model to put more emphasis on these hard samples consisting these items of high occlusion levels, which is more suitable for this scenario. We comprehensively evaluated DOAM-O on the OPIXray dataset, which proves that our model can stably improve the performance of the famous detection models such as SSD, YOLOv3, and FCOS, and outperform many extensively-used attention mechanisms.