 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Discovery Engine
Jul 01, 2025



The Discovery Engine is a general purpose automated system for scientific discovery, which combines machine learning with state-of-the-art ML interpretability to enable rapid and robust scientific insight across diverse datasets. In this paper, we benchmark the Discovery Engine against five recent peer-reviewed scientific publications applying machine learning across medicine, materials science, social science, and environmental science. In each case, the Discovery Engine matches or exceeds prior predictive performance while also generating deeper, more actionable insights through rich interpretability artefacts. These results demonstrate its potential as a new standard for automated, interpretable scientific modelling that enables complex knowledge discovery from data.
Avoiding Leakage Poisoning: Concept Interventions Under Distribution Shifts
Apr 24, 2025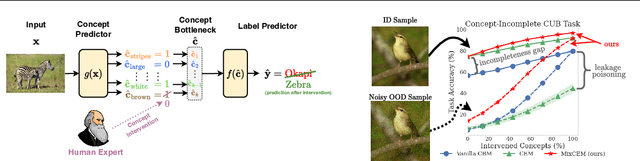
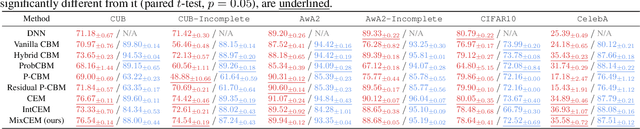
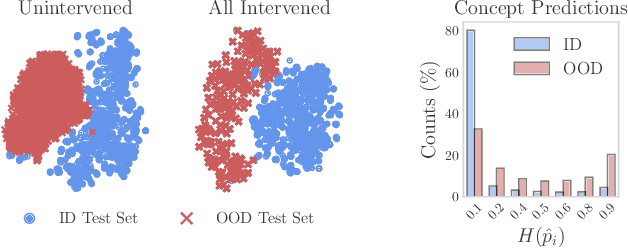

In this paper, we investigate how concept-based models (CMs) respond to out-of-distribution (OOD) inputs. CMs are interpretable neural architectures that first predict a set of high-level concepts (e.g., stripes, black) and then predict a task label from those concepts. In particular, we study the impact of concept interventions (i.e., operations where a human expert corrects a CM's mispredicted concepts at test time) on CMs' task predictions when inputs are OOD. Our analysis reveals a weakness in current state-of-the-art CMs, which we term leakage poisoning, that prevents them from properly improving their accuracy when intervened on for OOD inputs. To address this, we introduce MixCEM, a new CM that learns to dynamically exploit leaked information missing from its concepts only when this information is in-distribution. Our results across tasks with and without complete sets of concept annotations demonstrate that MixCEMs outperform strong baselines by significantly improving their accuracy for both in-distribution and OOD samples in the presence and absence of concept interventions.
Efficient Bias Mitigation Without Privileged Information
Sep 26, 2024Deep neural networks trained via empirical risk minimisation often exhibit significant performance disparities across groups, particularly when group and task labels are spuriously correlated (e.g., "grassy background" and "cows"). Existing bias mitigation methods that aim to address this issue often either rely on group labels for training or validation, or require an extensive hyperparameter search. Such data and computational requirements hinder the practical deployment of these methods, especially when datasets are too large to be group-annotated, computational resources are limited, and models are trained through already complex pipelines. In this paper, we propose Targeted Augmentations for Bias Mitigation (TAB), a simple hyperparameter-free framework that leverages the entire training history of a helper model to identify spurious samples, and generate a group-balanced training set from which a robust model can be trained. We show that TAB improves worst-group performance without any group information or model selection, outperforming existing methods while maintaining overall accuracy.
Learning to Receive Help: Intervention-Aware Concept Embedding Models
Sep 29, 2023



Concept Bottleneck Models (CBMs) tackle the opacity of neural architectures by constructing and explaining their predictions using a set of high-level concepts. A special property of these models is that they permit concept interventions, wherein users can correct mispredicted concepts and thus improve the model's performance. Recent work, however, has shown that intervention efficacy can be highly dependent on the order in which concepts are intervened on and on the model's architecture and training hyperparameters. We argue that this is rooted in a CBM's lack of train-time incentives for the model to be appropriately receptive to concept interventions. To address this, we propose Intervention-aware Concept Embedding models (IntCEMs), a novel CBM-based architecture and training paradigm that improves a model's receptiveness to test-time interventions. Our model learns a concept intervention policy in an end-to-end fashion from where it can sample meaningful intervention trajectories at train-time. This conditions IntCEMs to effectively select and receive concept interventions when deployed at test-time. Our experiments show that IntCEMs significantly outperform state-of-the-art concept-interpretable models when provided with test-time concept interventions, demonstrating the effectiveness of our approach.
CGXplain: Rule-Based Deep Neural Network Explanations Using Dual Linear Programs
Apr 11, 2023


Rule-based surrogate models are an effective and interpretable way to approximate a Deep Neural Network's (DNN) decision boundaries, allowing humans to easily understand deep learning models. Current state-of-the-art decompositional methods, which are those that consider the DNN's latent space to extract more exact rule sets, manage to derive rule sets at high accuracy. However, they a) do not guarantee that the surrogate model has learned from the same variables as the DNN (alignment), b) only allow to optimise for a single objective, such as accuracy, which can result in excessively large rule sets (complexity), and c) use decision tree algorithms as intermediate models, which can result in different explanations for the same DNN (stability). This paper introduces the CGX (Column Generation eXplainer) to address these limitations - a decompositional method using dual linear programming to extract rules from the hidden representations of the DNN. This approach allows to optimise for any number of objectives and empowers users to tweak the explanation model to their needs. We evaluate our results on a wide variety of tasks and show that CGX meets all three criteria, by having exact reproducibility of the explanation model that guarantees stability and reduces the rule set size by >80% (complexity) at equivalent or improved accuracy and fidelity across tasks (alignment).
Towards Robust Metrics for Concept Representation Evaluation
Jan 25, 2023



Recent work on interpretability has focused on concept-based explanations, where deep learning models are explained in terms of high-level units of information, referred to as concepts. Concept learning models, however, have been shown to be prone to encoding impurities in their representations, failing to fully capture meaningful features of their inputs. While concept learning lacks metrics to measure such phenomena, the field of disentanglement learning has explored the related notion of underlying factors of variation in the data, with plenty of metrics to measure the purity of such factors. In this paper, we show that such metrics are not appropriate for concept learning and propose novel metrics for evaluating the purity of concept representations in both approaches. We show the advantage of these metrics over existing ones and demonstrate their utility in evaluating the robustness of concept representations and interventions performed on them. In addition, we show their utility for benchmarking state-of-the-art methods from both families and find that, contrary to common assumptions, supervision alone may not be sufficient for pure concept representations.
Concept Embedding Models
Sep 19, 2022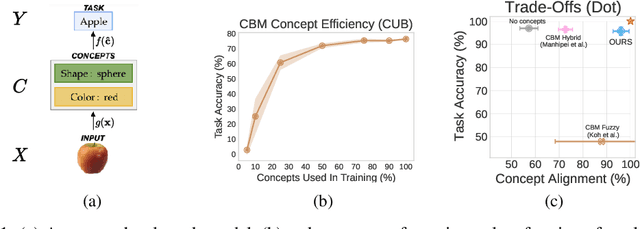

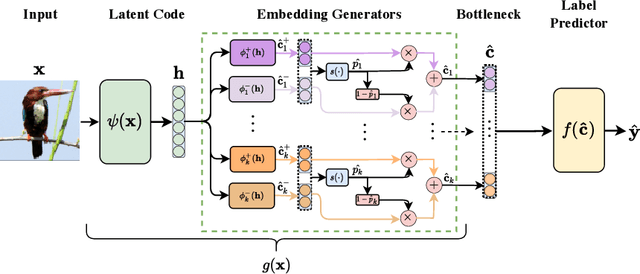

Deploying AI-powered systems requires trustworthy models supporting effective human interactions, going beyond raw prediction accuracy. Concept bottleneck models promote trustworthiness by conditioning classification tasks on an intermediate level of human-like concepts. This enables human interventions which can correct mispredicted concepts to improve the model's performance. However, existing concept bottleneck models are unable to find optimal compromises between high task accuracy, robust concept-based explanations, and effective interventions on concepts -- particularly in real-world conditions where complete and accurate concept supervisions are scarce. To address this, we propose Concept Embedding Models, a novel family of concept bottleneck models which goes beyond the current accuracy-vs-interpretability trade-off by learning interpretable high-dimensional concept representations. Our experiments demonstrate that Concept Embedding Models (1) attain better or competitive task accuracy w.r.t. standard neural models without concepts, (2) provide concept representations capturing meaningful semantics including and beyond their ground truth labels, (3) support test-time concept interventions whose effect in test accuracy surpasses that in standard concept bottleneck models, and (4) scale to real-world conditions where complete concept supervisions are scarce.
Efficient Decompositional Rule Extraction for Deep Neural Networks
Nov 24, 2021

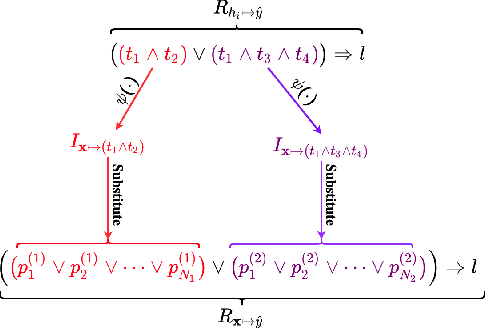
In recent years, there has been significant work on increasing both interpretability and debuggability of a Deep Neural Network (DNN) by extracting a rule-based model that approximates its decision boundary. Nevertheless, current DNN rule extraction methods that consider a DNN's latent space when extracting rules, known as decompositional algorithms, are either restricted to single-layer DNNs or intractable as the size of the DNN or data grows. In this paper, we address these limitations by introducing ECLAIRE, a novel polynomial-time rule extraction algorithm capable of scaling to both large DNN architectures and large training datasets. We evaluate ECLAIRE on a wide variety of tasks, ranging from breast cancer prognosis to particle detection, and show that it consistently extracts more accurate and comprehensible rule sets than the current state-of-the-art methods while using orders of magnitude less computational resources. We make all of our methods available, including a rule set visualisation interface, through the open-source REMIX library (https://github.com/mateoespinosa/remix).
Using ontology embeddings for structural inductive bias in gene expression data analysis
Nov 22, 2020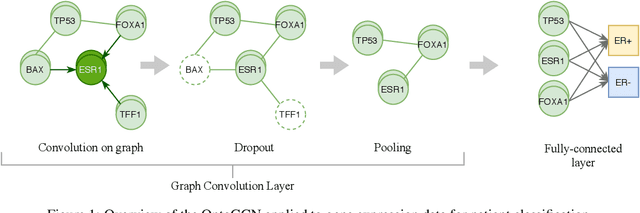

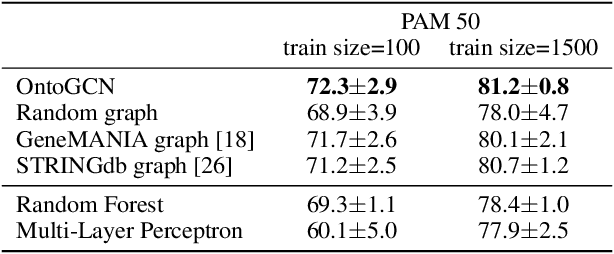
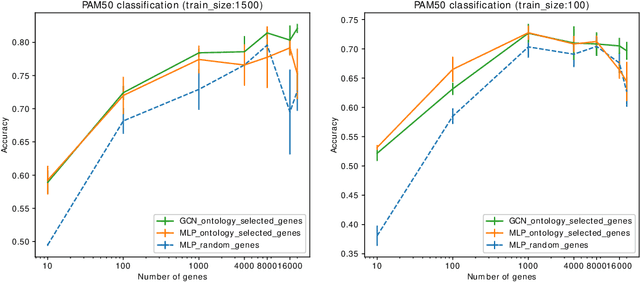
Stratifying cancer patients based on their gene expression levels allows improving diagnosis, survival analysis and treatment planning. However, such data is extremely highly dimensional as it contains expression values for over 20000 genes per patient, and the number of samples in the datasets is low. To deal with such settings, we propose to incorporate prior biological knowledge about genes from ontologies into the machine learning system for the task of patient classification given their gene expression data. We use ontology embeddings that capture the semantic similarities between the genes to direct a Graph Convolutional Network, and therefore sparsify the network connections. We show this approach provides an advantage for predicting clinical targets from high-dimensional low-sample data.
Incorporating network based protein complex discovery into automated model construction
Sep 29, 2020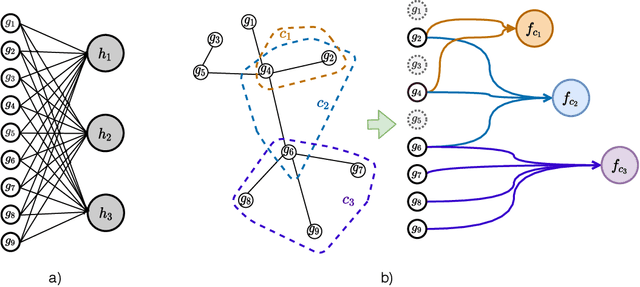
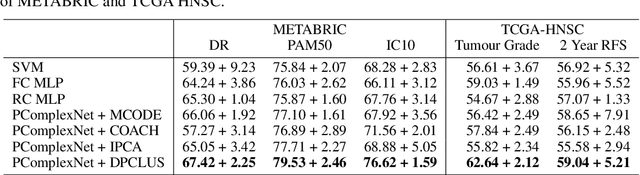
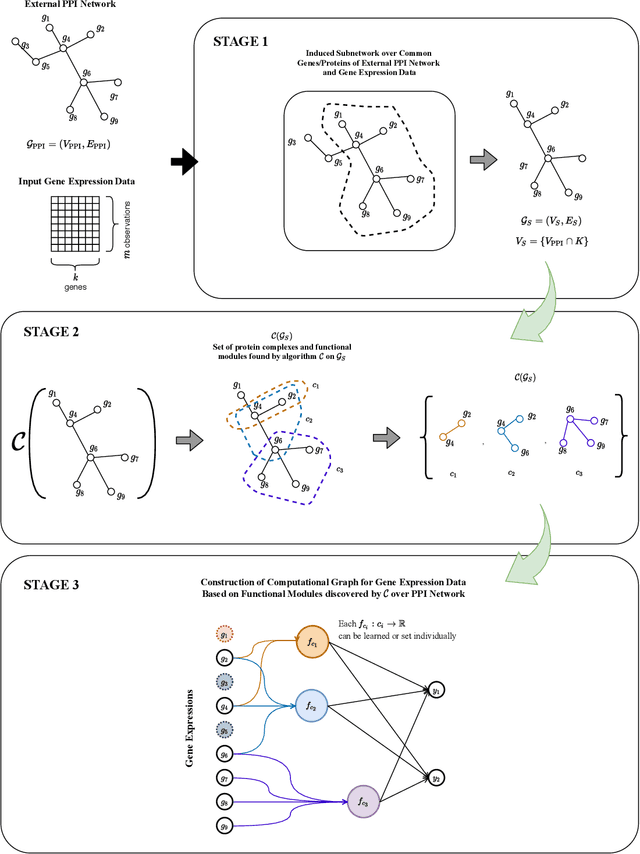
We propose a method for gene expression based analysis of cancer phenotypes incorporating network biology knowledge through unsupervised construction of computational graphs. The structural construction of the computational graphs is driven by the use of topological clustering algorithms on protein-protein networks which incorporate inductive biases stemming from network biology research in protein complex discovery. This structurally constrains the hypothesis space over the possible computational graph factorisation whose parameters can then be learned through supervised or unsupervised task settings. The sparse construction of the computational graph enables the differential protein complex activity analysis whilst also interpreting the individual contributions of genes/proteins involved in each individual protein complex. In our experiments analysing a variety of cancer phenotypes, we show that the proposed methods outperform SVM, Fully-Connected MLP, and Randomly-Connected MLPs in all tasks. Our work introduces a scalable method for incorporating large interaction networks as prior knowledge to drive the construction of powerful computational models amenable to introspective study.