 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Discovery of Biophysical T Cell Receptor Co-specificity Rules
Dec 18, 2024



The biophysical interactions between the T cell receptor (TCR) and its ligands determine the specificity of the cellular immune response. However, the immense diversity of receptors and ligands has made it challenging to discover generalizable rules across the distinct binding affinity landscapes created by different ligands. Here, we present an optimization framework for discovering biophysical rules that predict whether TCRs share specificity to a ligand. Applying this framework to TCRs associated with a collection of SARS-CoV-2 peptides we establish how co-specificity depends on the type and position of amino-acid differences between receptors. We also demonstrate that the inferred rules generalize to ligands not seen during training. Our analysis reveals that matching of steric properties between substituted amino acids is important for receptor co-specificity, in contrast with the hydrophobic properties that more prominently determine evolutionary substitutability. We furthermore find that positions not in direct contact with the peptide still significantly impact specificity. These findings highlight the potential for data-driven approaches to uncover the molecular mechanisms underpinning the specificity of adaptive immune responses.
Contrastive learning of T cell receptor representations
Jun 10, 2024Computational prediction of the interaction of T cell receptors (TCRs) and their ligands is a grand challenge in immunology. Despite advances in high-throughput assays, specificity-labelled TCR data remains sparse. In other domains, the pre-training of language models on unlabelled data has been successfully used to address data bottlenecks. However, it is unclear how to best pre-train protein language models for TCR specificity prediction. Here we introduce a TCR language model called SCEPTR (Simple Contrastive Embedding of the Primary sequence of T cell Receptors), capable of data-efficient transfer learning. Through our model, we introduce a novel pre-training strategy combining autocontrastive learning and masked-language modelling, which enables SCEPTR to achieve its state-of-the-art performance. In contrast, existing protein language models and a variant of SCEPTR pre-trained without autocontrastive learning are outperformed by sequence alignment-based methods. We anticipate that contrastive learning will be a useful paradigm to decode the rules of TCR specificity.
Correlated Feature Selection with Extended Exclusive Group Lasso
Feb 27, 2020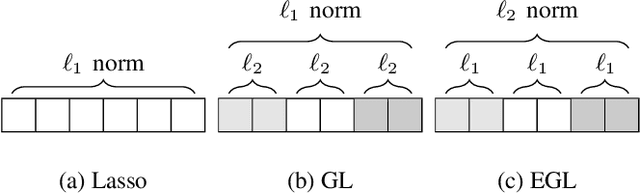

In many high dimensional classification or regression problems set in a biological context, the complete identification of the set of informative features is often as important as predictive accuracy, since this can provide mechanistic insight and conceptual understanding. Lasso and related algorithms have been widely used since their sparse solutions naturally identify a set of informative features. However, Lasso performs erratically when features are correlated. This limits the use of such algorithms in biological problems, where features such as genes often work together in pathways, leading to sets of highly correlated features. In this paper, we examine the performance of a Lasso derivative, the exclusive group Lasso, in this setting. We propose fast algorithms to solve the exclusive group Lasso, and introduce a solution to the case when the underlying group structure is unknown. The solution combines stability selection with random group allocation and introduction of artificial features. Experiments with both synthetic and real-world data highlight the advantages of this proposed methodology over Lasso in comprehensive selection of informative features.