 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Natural and Synthetic Structured Data: A Study of the Passive Verb Alternation in French and Italian
Mar 26, 2026This study compares the impact of natural and synthetic data on training and evaluating large language models (LLMs), using the case of passive verb alternation in French and Italian. We use Blackbird Language Matrices (BLMs), structured datasets designed to probe linguistic knowledge of underlying patterns across sentence sets. We compare structured templates instantiated with natural sentences extracted from Universal Dependencies to structured templates of synthetic sentences. Experiments show that while models achieve ceiling performance when trained and tested on synthetic datasets, they do not reliably generalize to natural sentences. In contrast, models trained on natural data exhibit robust performance across both natural and synthetic test suites, demonstrating their superior ability to capture abstract linguistic patterns. These results corroborate the value of natural data and of structured set ups in linguistic evaluation for probing LLMs' syntactic and semantic knowledge.
Datasets for Verb Alternations across Languages: BLM Templates and Data Augmentation Strategies
Mar 16, 2026Large language models (LLMs) have shown remarkable performance across various sentence-based linguistic phenomena, yet their ability to capture cross-sentence paradigmatic patterns, such as verb alternations, remains underexplored. In this work, we present curated paradigm-based datasets for four languages, designed to probe systematic cross-sentence knowledge of verb alternations (change-of-state and object-drop constructions in English, German and Italian, and Hebrew binyanim). The datasets comprise thousands of the Blackbird Language Matrices (BLMs) problems. The BLM task -- an RPM/ARC-like task devised specifically for language -- is a controlled linguistic puzzle where models must select the sentence that completes a pattern according to syntactic and semantic rules. We introduce three types of templates varying in complexity and apply linguistically-informed data augmentation strategies across synthetic and natural data. We provide simple baseline performance results across English, Italian, German, and Hebrew, that demonstrate the diagnostic usefulness of the datasets.
Blackbird Language Matrices: A Framework to Investigate the Linguistic Competence of Language Models
Feb 24, 2026This article describes a novel language task, the Blackbird Language Matrices (BLM) task, inspired by intelligence tests, and illustrates the BLM datasets, their construction and benchmarking, and targeted experiments on chunking and systematicity. BLMs are multiple-choice problems, structured at multiple levels: within each sentence, across the input sequence, within each candidate answer. Because of their rich structure, these curated, but naturalistic datasets are key to answer some core questions about current large language models abilities: do LLMs detect linguistic objects and their properties? Do they detect and use systematic patterns across sentences? Are they more prone to linguistic or reasoning errors, and how do these interact? We show that BLMs, while challenging, can be solved at good levels of performance, in more than one language, with simple baseline models or, at better performance levels, with more tailored models. We show that their representations contain the grammatical objects and attributes relevant to solve a linguistic task. We also show that these solutions are reached by detecting systematic patterns across sentences. The paper supports the point of view that curated, structured datasets support multi-faceted investigations of properties of language and large language models. Because they present a curated, articulated structure, because they comprise both learning contexts and expected answers, and because they are partly built by hand, BLMs fall in the category of datasets that can support explainability investigations, and be useful to ask why large language models behave the way they do.
Modelling the Morphology of Verbal Paradigms: A Case Study in the Tokenization of Turkish and Hebrew
Feb 05, 2026We investigate how transformer models represent complex verb paradigms in Turkish and Modern Hebrew, concentrating on how tokenization strategies shape this ability. Using the Blackbird Language Matrices task on natural data, we show that for Turkish -- with its transparent morphological markers -- both monolingual and multilingual models succeed, either when tokenization is atomic or when it breaks words into small subword units. For Hebrew, instead, monolingual and multilingual models diverge. A multilingual model using character-level tokenization fails to capture the language non-concatenative morphology, but a monolingual model with morpheme-aware segmentation performs well. Performance improves on more synthetic datasets, in all models.
Analogical Structure, Minimal Contextual Cues and Contrastive Distractors: Input Design for Sample-Efficient Linguistic Rule Induction
Nov 13, 2025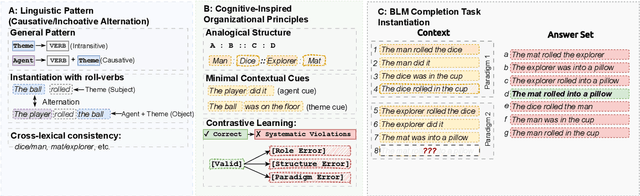
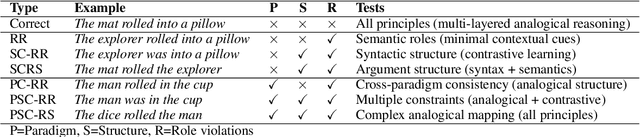

Large language models achieve strong performance through training on vast datasets. Can analogical paradigm organization enable lightweight models to match this performance with minimal data? We develop a computational approach implementing three cognitive-inspired principles: analogical structure, contrastive learning, and minimal contextual cues. We test this approach with structured completion tasks where models identify correct sentence completions from analogical patterns with contrastive alternatives. Training lightweight models (BERT+CNN, $0.5M$ parameters) on only one hundred structured examples of English causative/inchoative alternations achieves $F1=0.95$, outperforming zero-shot \texttt{GPT-o3} ($F1=0.87$). Ablation studies confirm that analogical organization and contrastive structure improve performance, consistently surpassing randomly shuffled baselines across architectures. Cross-phenomenon validation using unspecified object alternations replicates these efficiency gains, confirming approach robustness. Our results show that analogical paradigm organization enables competitive linguistic rule learning with orders of magnitude less data than conventional approaches require.
Exploring syntactic information in sentence embeddings through multilingual subject-verb agreement
Sep 10, 2024In this paper, our goal is to investigate to what degree multilingual pretrained language models capture cross-linguistically valid abstract linguistic representations. We take the approach of developing curated synthetic data on a large scale, with specific properties, and using them to study sentence representations built using pretrained language models. We use a new multiple-choice task and datasets, Blackbird Language Matrices (BLMs), to focus on a specific grammatical structural phenomenon -- subject-verb agreement across a variety of sentence structures -- in several languages. Finding a solution to this task requires a system detecting complex linguistic patterns and paradigms in text representations. Using a two-level architecture that solves the problem in two steps -- detect syntactic objects and their properties in individual sentences, and find patterns across an input sequence of sentences -- we show that despite having been trained on multilingual texts in a consistent manner, multilingual pretrained language models have language-specific differences, and syntactic structure is not shared, even across closely related languages.
Exploring Italian sentence embeddings properties through multi-tasking
Sep 10, 2024We investigate to what degree existing LLMs encode abstract linguistic information in Italian in a multi-task setting. We exploit curated synthetic data on a large scale -- several Blackbird Language Matrices (BLMs) problems in Italian -- and use them to study how sentence representations built using pre-trained language models encode specific syntactic and semantic information. We use a two-level architecture to model separately a compression of the sentence embeddings into a representation that contains relevant information for a task, and a BLM task. We then investigate whether we can obtain compressed sentence representations that encode syntactic and semantic information relevant to several BLM tasks. While we expected that the sentence structure -- in terms of sequence of phrases/chunks -- and chunk properties could be shared across tasks, performance and error analysis show that the clues for the different tasks are encoded in different manners in the sentence embeddings, suggesting that abstract linguistic notions such as constituents or thematic roles does not seem to be present in the pretrained sentence embeddings.
Tracking linguistic information in transformer-based sentence embeddings through targeted sparsification
Jul 25, 2024Analyses of transformer-based models have shown that they encode a variety of linguistic information from their textual input. While these analyses have shed a light on the relation between linguistic information on one side, and internal architecture and parameters on the other, a question remains unanswered: how is this linguistic information reflected in sentence embeddings? Using datasets consisting of sentences with known structure, we test to what degree information about chunks (in particular noun, verb or prepositional phrases), such as grammatical number, or semantic role, can be localized in sentence embeddings. Our results show that such information is not distributed over the entire sentence embedding, but rather it is encoded in specific regions. Understanding how the information from an input text is compressed into sentence embeddings helps understand current transformer models and help build future explainable neural models.
Are there identifiable structural parts in the sentence embedding whole?
Jun 24, 2024

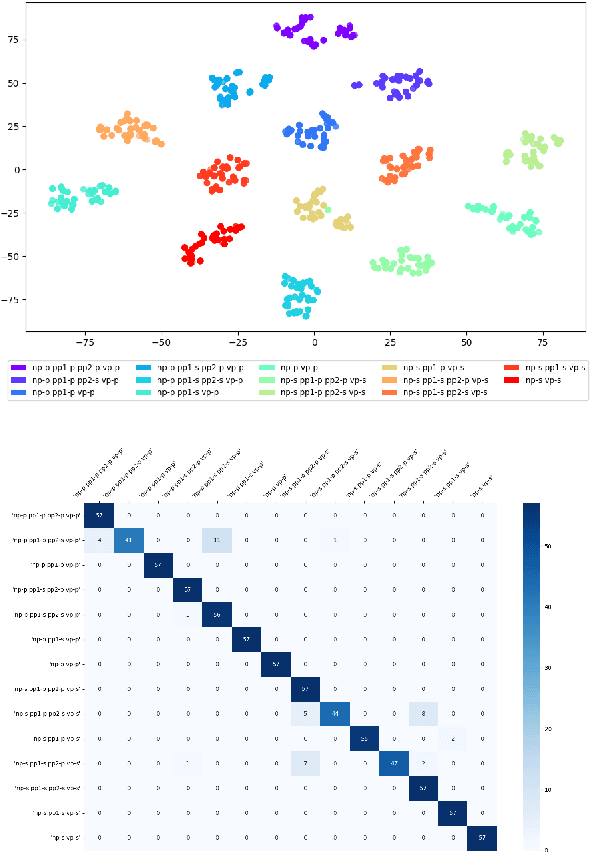

Sentence embeddings from transformer models encode in a fixed length vector much linguistic information. We explore the hypothesis that these embeddings consist of overlapping layers of information that can be separated, and on which specific types of information -- such as information about chunks and their structural and semantic properties -- can be detected. We show that this is the case using a dataset consisting of sentences with known chunk structure, and two linguistic intelligence datasets, solving which relies on detecting chunks and their grammatical number, and respectively, their semantic roles, and through analyses of the performance on the tasks and of the internal representations built during learning.
Disentangling continuous and discrete linguistic signals in transformer-based sentence embeddings
Dec 18, 2023Sentence and word embeddings encode structural and semantic information in a distributed manner. Part of the information encoded -- particularly lexical information -- can be seen as continuous, whereas other -- like structural information -- is most often discrete. We explore whether we can compress transformer-based sentence embeddings into a representation that separates different linguistic signals -- in particular, information relevant to subject-verb agreement and verb alternations. We show that by compressing an input sequence that shares a targeted phenomenon into the latent layer of a variational autoencoder-like system, the targeted linguistic information becomes more explicit. A latent layer with both discrete and continuous components captures better the targeted phenomena than a latent layer with only discrete or only continuous components. These experiments are a step towards separating linguistic signals from distributed text embeddings and linking them to more symbolic representations.