 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlackbird's language matrices : a new benchmark to investigate disentangled generalisation in neural networks
May 22, 2022
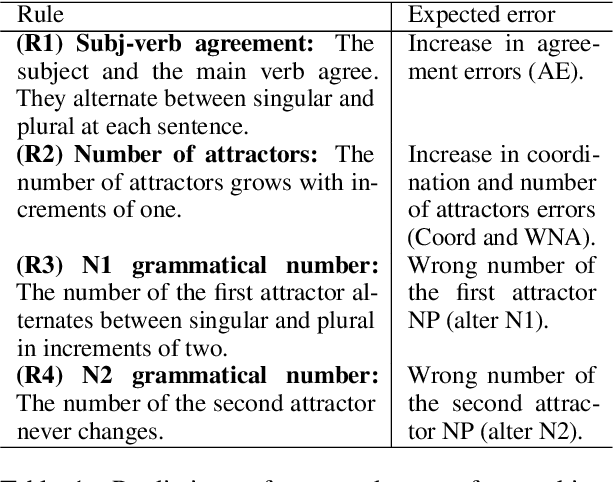

Current successes of machine learning architectures are based on computationally expensive algorithms and prohibitively large amounts of data. We need to develop tasks and data to train networks to reach more complex and more compositional skills. In this paper, we illustrate Blackbird's language matrices (BLMs), a novel grammatical dataset developed to test a linguistic variant of Raven's progressive matrices, an intelligence test usually based on visual stimuli. The dataset consists of 44800 sentences, generatively constructed to support investigations of current models' linguistic mastery of grammatical agreement rules and their ability to generalise them. We present the logic of the dataset, the method to automatically construct data on a large scale and the architecture to learn them. Through error analysis and several experiments on variations of the dataset, we demonstrate that this language task and the data that instantiate it provide a new challenging testbed to understand generalisation and abstraction.
Representation of Constituents in Neural Language Models: Coordination Phrase as a Case Study
Sep 10, 2019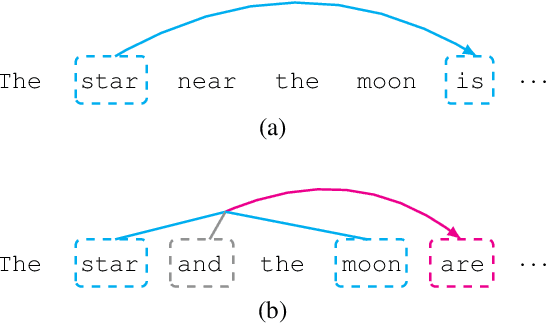
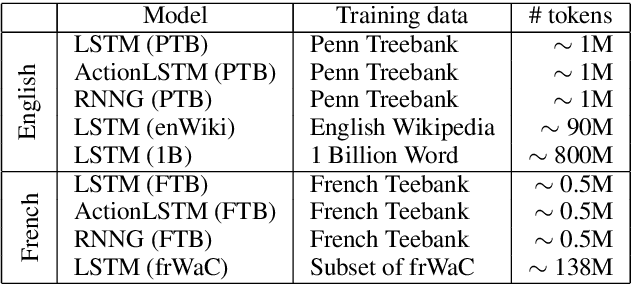
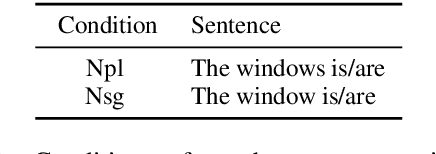

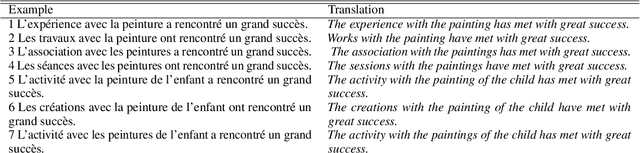
Neural language models have achieved state-of-the-art performances on many NLP tasks, and recently have been shown to learn a number of hierarchically-sensitive syntactic dependencies between individual words. However, equally important for language processing is the ability to combine words into phrasal constituents, and use constituent-level features to drive downstream expectations. Here we investigate neural models' ability to represent constituent-level features, using coordinated noun phrases as a case study. We assess whether different neural language models trained on English and French represent phrase-level number and gender features, and use those features to drive downstream expectations. Our results suggest that models use a linear combination of NP constituent number to drive CoordNP/verb number agreement. This behavior is highly regular and even sensitive to local syntactic context, however it differs crucially from observed human behavior. Models have less success with gender agreement. Models trained on large corpora perform best, and there is no obvious advantage for models trained using explicit syntactic supervision.