 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput-Based Ensemble-Learning Method for Dynamic Memory Configuration of Serverless Computing Functions
Nov 12, 2024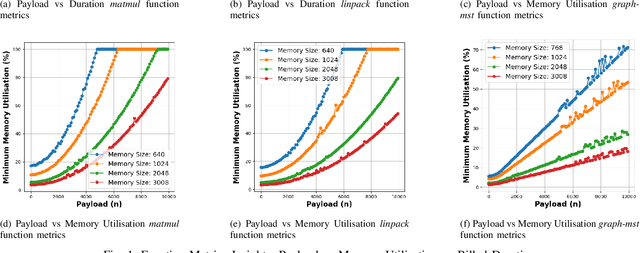
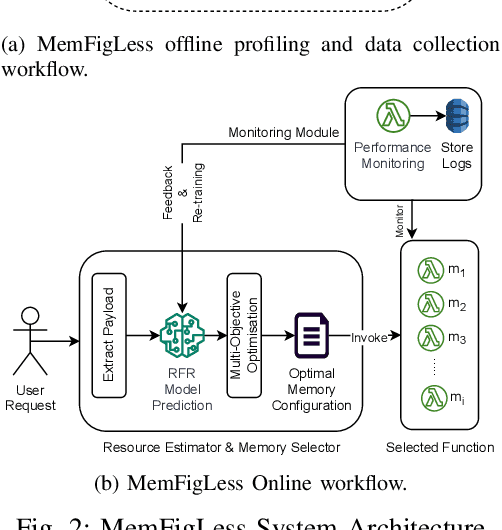
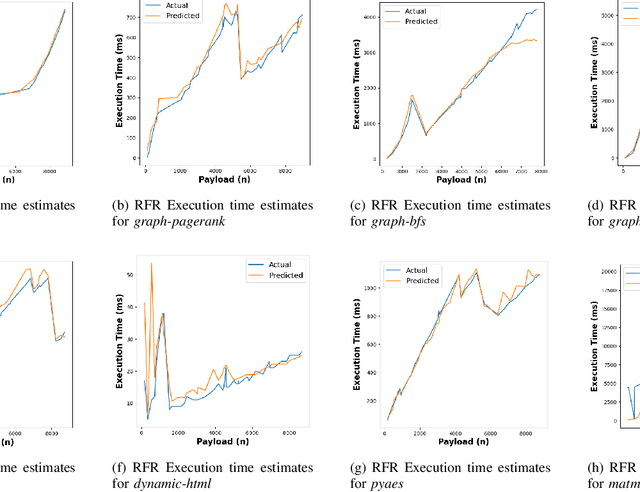
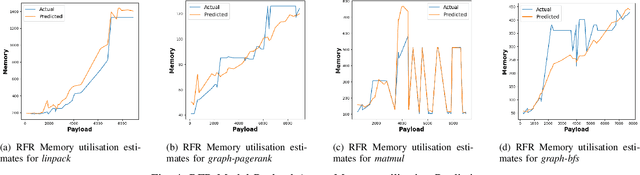
In today's Function-as-a-Service offerings, a programmer is usually responsible for configuring function memory for its successful execution, which allocates proportional function resources such as CPU and network. However, right-sizing the function memory force developers to speculate performance and make ad-hoc configuration decisions. Recent research has highlighted that a function's input characteristics, such as input size, type and number of inputs, significantly impact its resource demand, run-time performance and costs with fluctuating workloads. This correlation further makes memory configuration a non-trivial task. On that account, an input-aware function memory allocator not only improves developer productivity by completely hiding resource-related decisions but also drives an opportunity to reduce resource wastage and offer a finer-grained cost-optimised pricing scheme. Therefore, we present MemFigLess, a serverless solution that estimates the memory requirement of a serverless function with input-awareness. The framework executes function profiling in an offline stage and trains a multi-output Random Forest Regression model on the collected metrics to invoke input-aware optimal configurations. We evaluate our work with the state-of-the-art approaches on AWS Lambda service to find that MemFigLess is able to capture the input-aware resource relationships and allocate upto 82% less resources and save up to 87% run-time costs.
* 10 pages, 2 tables, 28 figures, accepted conference paper - UCC'24
Reinforcement Learning (RL) Augmented Cold Start Frequency Reduction in Serverless Computing
Aug 15, 2023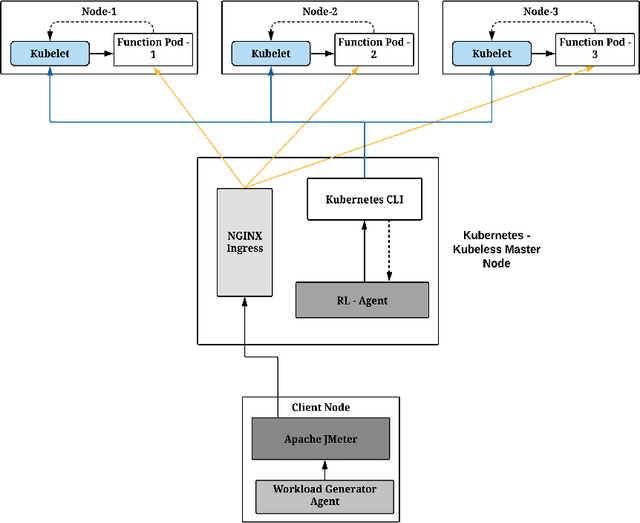
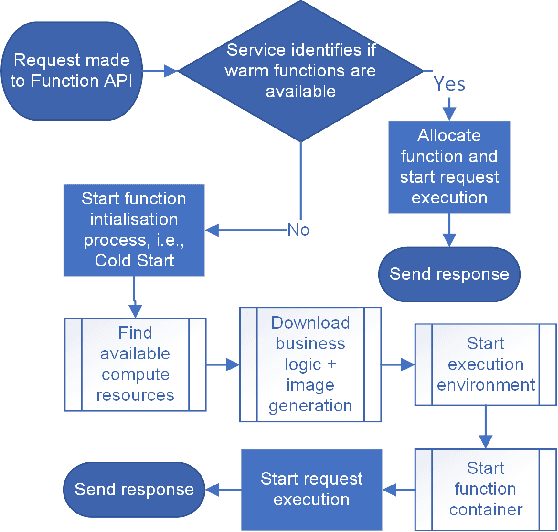
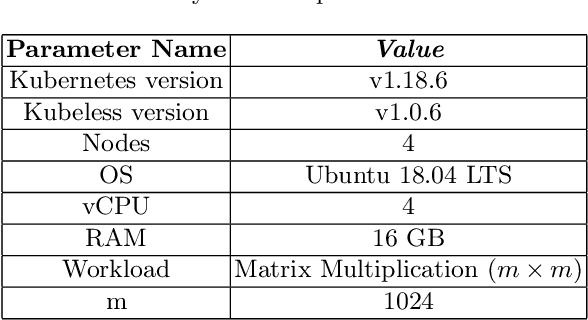
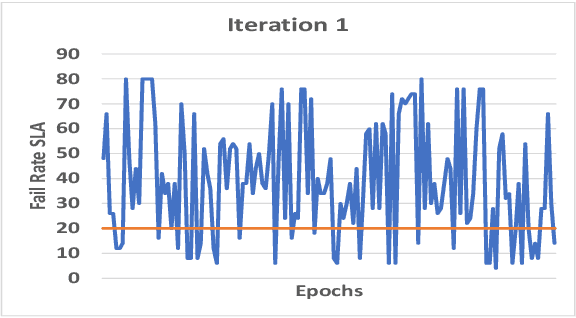
Function-as-a-Service is a cloud computing paradigm offering an event-driven execution model to applications. It features serverless attributes by eliminating resource management responsibilities from developers and offers transparent and on-demand scalability of applications. Typical serverless applications have stringent response time and scalability requirements and therefore rely on deployed services to provide quick and fault-tolerant feedback to clients. However, the FaaS paradigm suffers from cold starts as there is a non-negligible delay associated with on-demand function initialization. This work focuses on reducing the frequency of cold starts on the platform by using Reinforcement Learning. Our approach uses Q-learning and considers metrics such as function CPU utilization, existing function instances, and response failure rate to proactively initialize functions in advance based on the expected demand. The proposed solution was implemented on Kubeless and was evaluated using a normalised real-world function demand trace with matrix multiplication as the workload. The results demonstrate a favourable performance of the RL-based agent when compared to Kubeless' default policy and function keep-alive policy by improving throughput by up to 8.81% and reducing computation load and resource wastage by up to 55% and 37%, respectively, which is a direct outcome of reduced cold starts.
A Deep Recurrent-Reinforcement Learning Method for Intelligent AutoScaling of Serverless Functions
Aug 11, 2023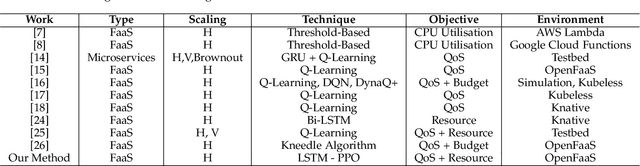
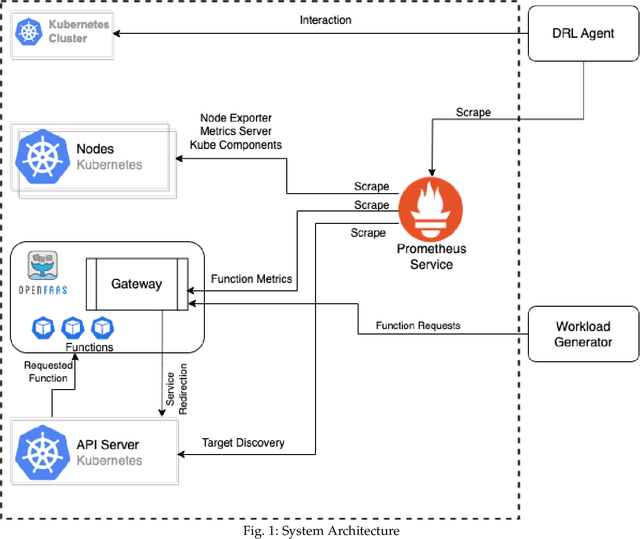

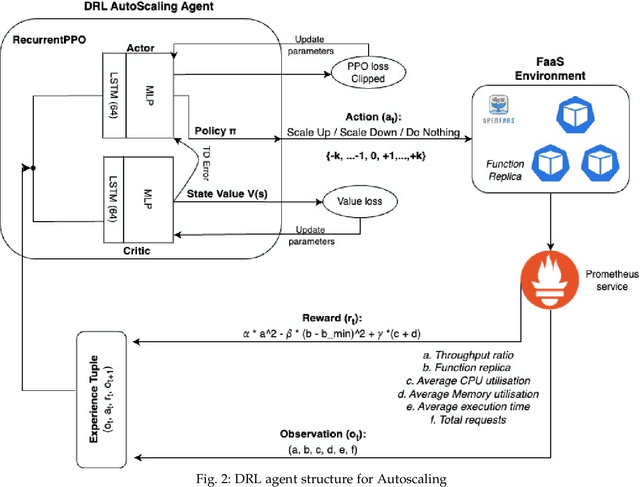
Function-as-a-Service (FaaS) introduces a lightweight, function-based cloud execution model that finds its relevance in applications like IoT-edge data processing and anomaly detection. While CSP offer a near-infinite function elasticity, these applications often experience fluctuating workloads and stricter performance constraints. A typical CSP strategy is to empirically determine and adjust desired function instances, "autoscaling", based on monitoring-based thresholds such as CPU or memory, to cope with demand and performance. However, threshold configuration either requires expert knowledge, historical data or a complete view of environment, making autoscaling a performance bottleneck lacking an adaptable solution.RL algorithms are proven to be beneficial in analysing complex cloud environments and result in an adaptable policy that maximizes the expected objectives. Most realistic cloud environments usually involve operational interference and have limited visibility, making them partially observable. A general solution to tackle observability in highly dynamic settings is to integrate Recurrent units with model-free RL algorithms and model a decision process as a POMDP. Therefore, in this paper, we investigate a model-free Recurrent RL agent for function autoscaling and compare it against the model-free Proximal Policy Optimisation (PPO) algorithm. We explore the integration of a LSTM network with the state-of-the-art PPO algorithm to find that under our experimental and evaluation settings, recurrent policies were able to capture the environment parameters and show promising results for function autoscaling. We further compare a PPO-based autoscaling agent with commercially used threshold-based function autoscaling and posit that a LSTM-based autoscaling agent is able to improve throughput by 18%, function execution by 13% and account for 8.4% more function instances.
Multi-Agent Patrolling with Battery Constraints through Deep Reinforcement Learning
Dec 16, 2022



Autonomous vehicles are suited for continuous area patrolling problems. However, finding an optimal patrolling strategy can be challenging for many reasons. Firstly, patrolling environments are often complex and can include unknown and evolving environmental factors. Secondly, autonomous vehicles can have failures or hardware constraints such as limited battery lives. Importantly, patrolling large areas often requires multiple agents that need to collectively coordinate their actions. In this work, we consider these limitations and propose an approach based on a distributed, model-free deep reinforcement learning based multi-agent patrolling strategy. In this approach, agents make decisions locally based on their own environmental observations and on shared information. In addition, agents are trained to automatically recharge themselves when required to support continuous collective patrolling. A homogeneous multi-agent architecture is proposed, where all patrolling agents have an identical policy. This architecture provides a robust patrolling system that can tolerate agent failures and allow supplementary agents to be added to replace failed agents or to increase the overall patrol performance. This performance is validated through experiments from multiple perspectives, including the overall patrol performance, the efficiency of the battery recharging strategy, the overall robustness of the system, and the agents' ability to adapt to environment dynamics.
Blackbird's language matrices : a new benchmark to investigate disentangled generalisation in neural networks
May 22, 2022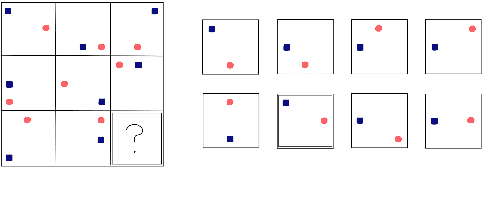
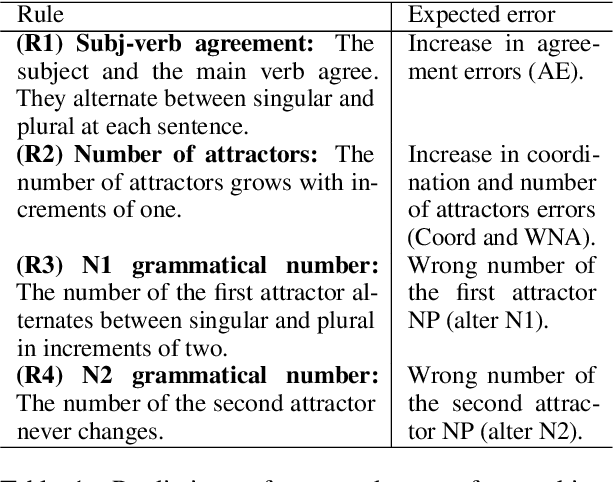

Current successes of machine learning architectures are based on computationally expensive algorithms and prohibitively large amounts of data. We need to develop tasks and data to train networks to reach more complex and more compositional skills. In this paper, we illustrate Blackbird's language matrices (BLMs), a novel grammatical dataset developed to test a linguistic variant of Raven's progressive matrices, an intelligence test usually based on visual stimuli. The dataset consists of 44800 sentences, generatively constructed to support investigations of current models' linguistic mastery of grammatical agreement rules and their ability to generalise them. We present the logic of the dataset, the method to automatically construct data on a large scale and the architecture to learn them. Through error analysis and several experiments on variations of the dataset, we demonstrate that this language task and the data that instantiate it provide a new challenging testbed to understand generalisation and abstraction.
Task Runtime Prediction in Scientific Workflows Using an Online Incremental Learning Approach
Oct 10, 2018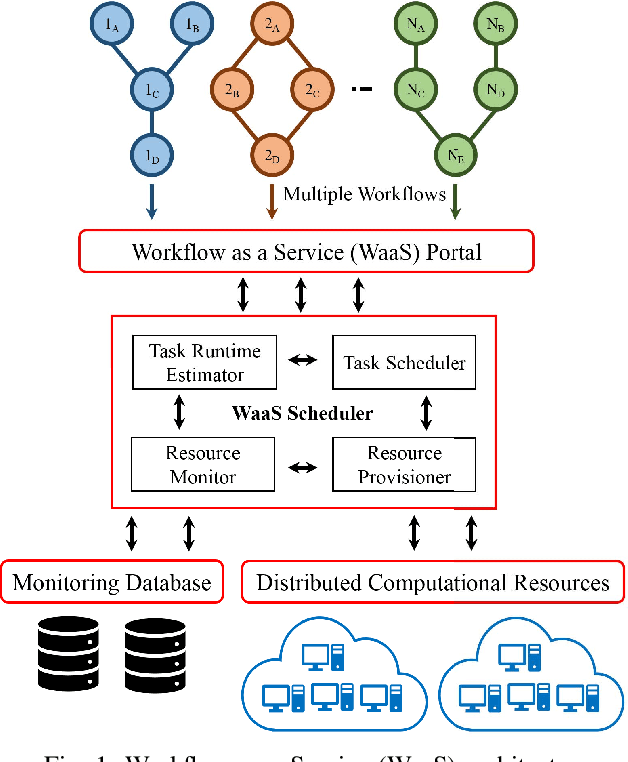
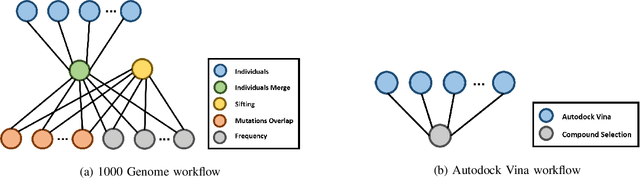
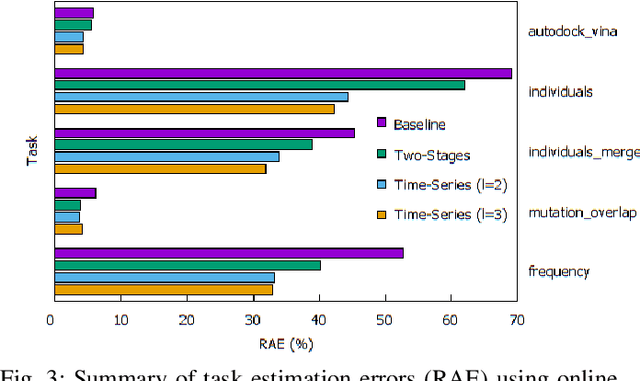
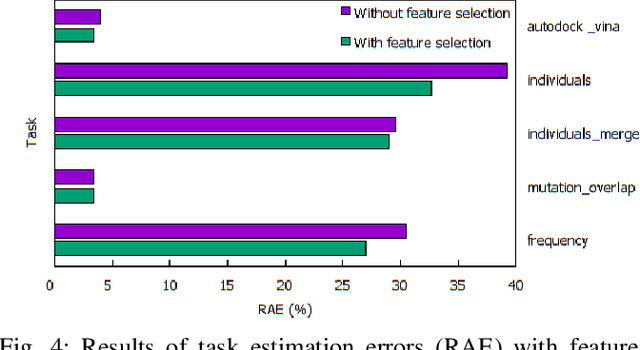
Many algorithms in workflow scheduling and resource provisioning rely on the performance estimation of tasks to produce a scheduling plan. A profiler that is capable of modeling the execution of tasks and predicting their runtime accurately, therefore, becomes an essential part of any Workflow Management System (WMS). With the emergence of multi-tenant Workflow as a Service (WaaS) platforms that use clouds for deploying scientific workflows, task runtime prediction becomes more challenging because it requires the processing of a significant amount of data in a near real-time scenario while dealing with the performance variability of cloud resources. Hence, relying on methods such as profiling tasks' execution data using basic statistical description (e.g., mean, standard deviation) or batch offline regression techniques to estimate the runtime may not be suitable for such environments. In this paper, we propose an online incremental learning approach to predict the runtime of tasks in scientific workflows in clouds. To improve the performance of the predictions, we harness fine-grained resources monitoring data in the form of time-series records of CPU utilization, memory usage, and I/O activities that are reflecting the unique characteristics of a task's execution. We compare our solution to a state-of-the-art approach that exploits the resources monitoring data based on regression machine learning technique. From our experiments, the proposed strategy improves the performance, in terms of the error, up to 29.89%, compared to the state-of-the-art solutions.