 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Concept-based Adversarial Learning for Cross-lingual Word Embeddings
Paper and Code

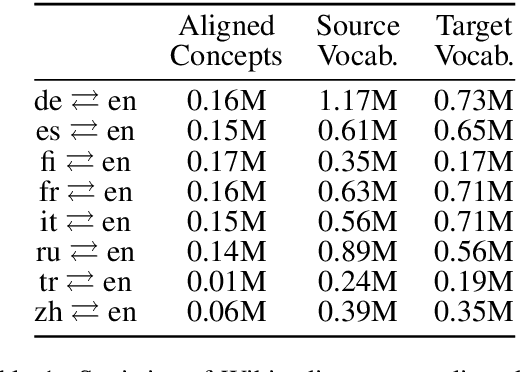
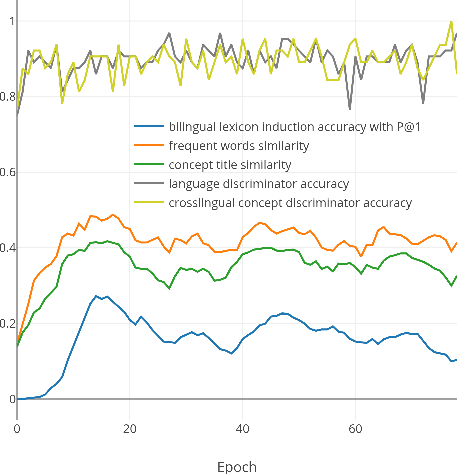
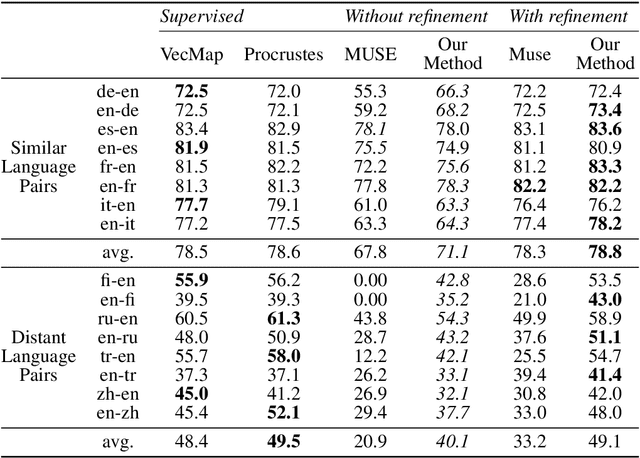
Distributed representations of words which map each word to a continuous vector have proven useful in capturing important linguistic information not only in a single language but also across different languages. Current unsupervised adversarial approaches show that it is possible to build a mapping matrix that align two sets of monolingual word embeddings together without high quality parallel data such as a dictionary or a sentence-aligned corpus. However, without post refinement, the performance of these methods' preliminary mapping is not good, leading to poor performance for typologically distant languages. In this paper, we propose a weakly-supervised adversarial training method to overcome this limitation, based on the intuition that mapping across languages is better done at the concept level than at the word level. We propose a concept-based adversarial training method which for most languages improves the performance of previous unsupervised adversarial methods, especially for typologically distant language pairs.