 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generating Realistic 3D Semantic Training Data for Autonomous Driving
Mar 27, 2025Semantic scene understanding is crucial for robotics and computer vision applications. In autonomous driving, 3D semantic segmentation plays an important role for enabling safe navigation. Despite significant advances in the field, the complexity of collecting and annotating 3D data is a bottleneck in this developments. To overcome that data annotation limitation, synthetic simulated data has been used to generate annotated data on demand. There is still however a domain gap between real and simulated data. More recently, diffusion models have been in the spotlight, enabling close-to-real data synthesis. Those generative models have been recently applied to the 3D data domain for generating scene-scale data with semantic annotations. Still, those methods either rely on image projection or decoupled models trained with different resolutions in a coarse-to-fine manner. Such intermediary representations impact the generated data quality due to errors added in those transformations. In this work, we propose a novel approach able to generate 3D semantic scene-scale data without relying on any projection or decoupled trained multi-resolution models, achieving more realistic semantic scene data generation compared to previous state-of-the-art methods. Besides improving 3D semantic scene-scale data synthesis, we thoroughly evaluate the use of the synthetic scene samples as labeled data to train a semantic segmentation network. In our experiments, we show that using the synthetic annotated data generated by our method as training data together with the real semantic segmentation labels, leads to an improvement in the semantic segmentation model performance. Our results show the potential of generated scene-scale point clouds to generate more training data to extend existing datasets, reducing the data annotation effort. Our code is available at https://github.com/PRBonn/3DiSS.
Scaling Diffusion Models to Real-World 3D LiDAR Scene Completion
Mar 20, 2024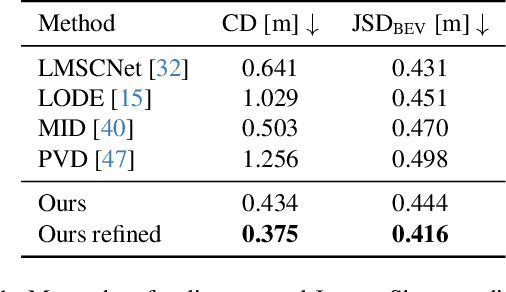
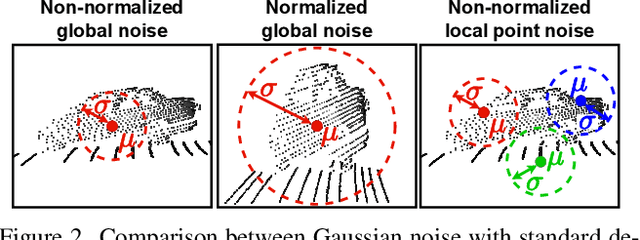
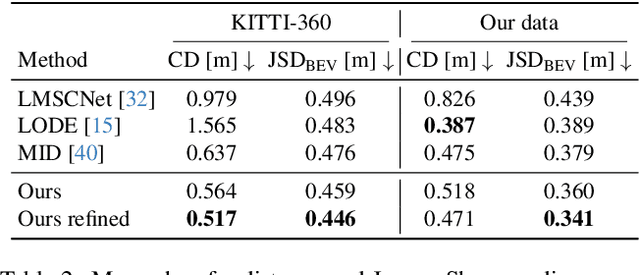
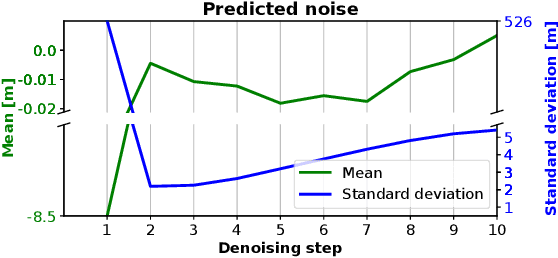
Computer vision techniques play a central role in the perception stack of autonomous vehicles. Such methods are employed to perceive the vehicle surroundings given sensor data. 3D LiDAR sensors are commonly used to collect sparse 3D point clouds from the scene. However, compared to human perception, such systems struggle to deduce the unseen parts of the scene given those sparse point clouds. In this matter, the scene completion task aims at predicting the gaps in the LiDAR measurements to achieve a more complete scene representation. Given the promising results of recent diffusion models as generative models for images, we propose extending them to achieve scene completion from a single 3D LiDAR scan. Previous works used diffusion models over range images extracted from LiDAR data, directly applying image-based diffusion methods. Distinctly, we propose to directly operate on the points, reformulating the noising and denoising diffusion process such that it can efficiently work at scene scale. Together with our approach, we propose a regularization loss to stabilize the noise predicted during the denoising process. Our experimental evaluation shows that our method can complete the scene given a single LiDAR scan as input, producing a scene with more details compared to state-of-the-art scene completion methods. We believe that our proposed diffusion process formulation can support further research in diffusion models applied to scene-scale point cloud data.
Open-World Semantic Segmentation Including Class Similarity
Mar 12, 2024Interpreting camera data is key for autonomously acting systems, such as autonomous vehicles. Vision systems that operate in real-world environments must be able to understand their surroundings and need the ability to deal with novel situations. This paper tackles open-world semantic segmentation, i.e., the variant of interpreting image data in which objects occur that have not been seen during training. We propose a novel approach that performs accurate closed-world semantic segmentation and, at the same time, can identify new categories without requiring any additional training data. Our approach additionally provides a similarity measure for every newly discovered class in an image to a known category, which can be useful information in downstream tasks such as planning or mapping. Through extensive experiments, we show that our model achieves state-of-the-art results on classes known from training data as well as for anomaly segmentation and can distinguish between different unknown classes.
Receding Moving Object Segmentation in 3D LiDAR Data Using Sparse 4D Convolutions
Jun 08, 2022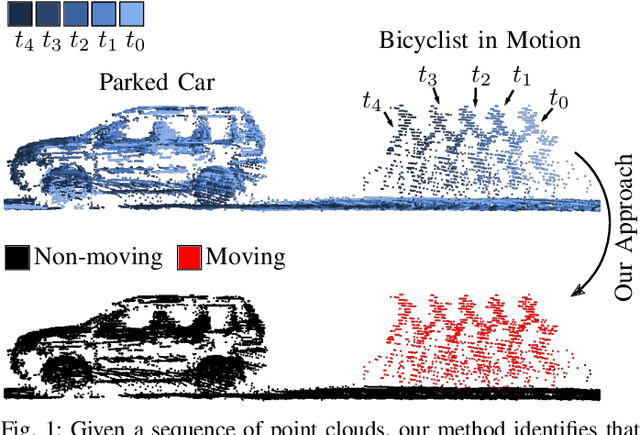
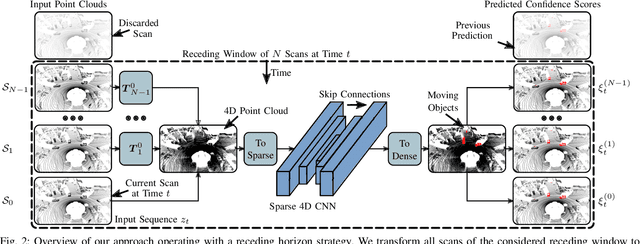


A key challenge for autonomous vehicles is to navigate in unseen dynamic environments. Separating moving objects from static ones is essential for navigation, pose estimation, and understanding how other traffic participants are likely to move in the near future. In this work, we tackle the problem of distinguishing 3D LiDAR points that belong to currently moving objects, like walking pedestrians or driving cars, from points that are obtained from non-moving objects, like walls but also parked cars. Our approach takes a sequence of observed LiDAR scans and turns them into a voxelized sparse 4D point cloud. We apply computationally efficient sparse 4D convolutions to jointly extract spatial and temporal features and predict moving object confidence scores for all points in the sequence. We develop a receding horizon strategy that allows us to predict moving objects online and to refine predictions on the go based on new observations. We use a binary Bayes filter to recursively integrate new predictions of a scan resulting in more robust estimation. We evaluate our approach on the SemanticKITTI moving object segmentation challenge and show more accurate predictions than existing methods. Since our approach only operates on the geometric information of point clouds over time, it generalizes well to new, unseen environments, which we evaluate on the Apollo dataset.
Automatic Labeling to Generate Training Data for Online LiDAR-based Moving Object Segmentation
Jan 12, 2022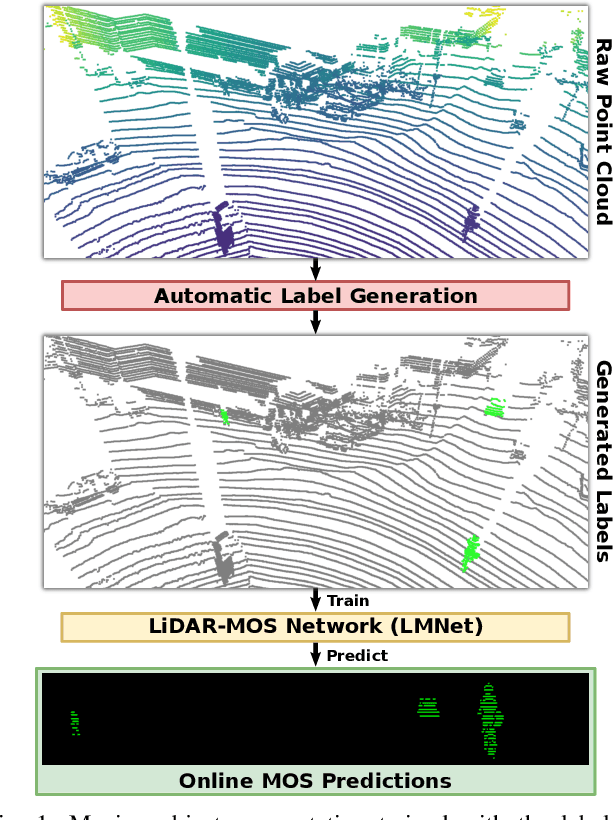
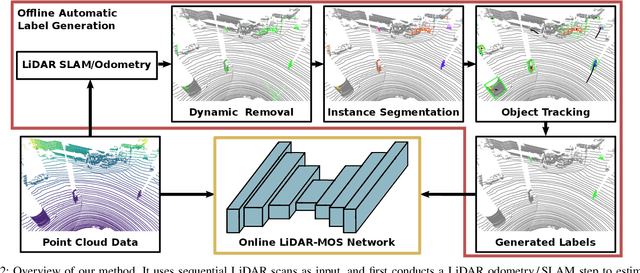
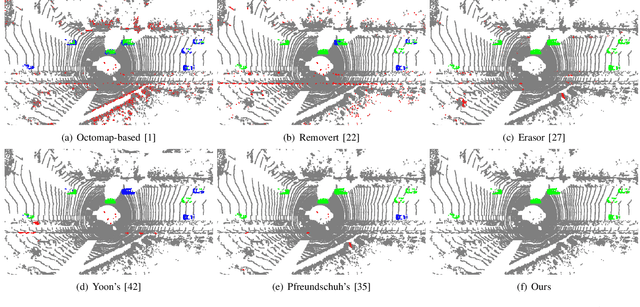
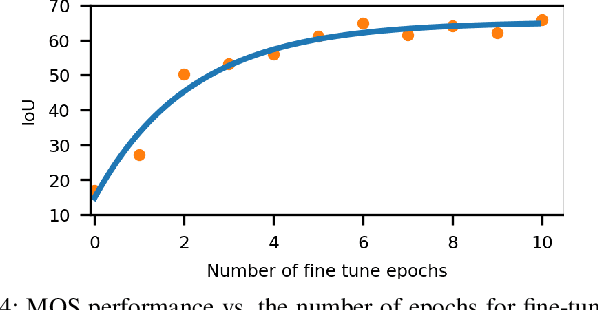
Understanding the scene is key for autonomously navigating vehicles and the ability to segment the surroundings online into moving and non-moving objects is a central ingredient for this task. Often, deep learning-based methods are used to perform moving object segmentation (MOS). The performance of these networks, however, strongly depends on the diversity and amount of labeled training data, information that may be costly to obtain. In this paper, we propose an automatic data labeling pipeline for 3D LiDAR data to save the extensive manual labeling effort and to improve the performance of existing learning-based MOS systems by automatically generating labeled training data. Our proposed approach achieves this by processing the data offline in batches. It first exploits an occupancy-based dynamic object removal to detect possible dynamic objects coarsely. Second, it extracts segments among the proposals and tracks them using a Kalman filter. Based on the tracked trajectories, it labels the actually moving objects such as driving cars and pedestrians as moving. In contrast, the non-moving objects, e.g., parked cars, lamps, roads, or buildings, are labeled as static. We show that this approach allows us to label LiDAR data highly effectively and compare our results to those of other label generation methods. We also train a deep neural network with our auto-generated labels and achieve similar performance compared to the one trained with manual labels on the same data, and an even better performance when using additional datasets with labels generated by our approach. Furthermore, we evaluate our method on multiple datasets using different sensors and our experiments indicate that our method can generate labels in diverse environments.