 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning of Robot Vision Using Adaptive Path Planning
Paper and Code
Oct 14, 2024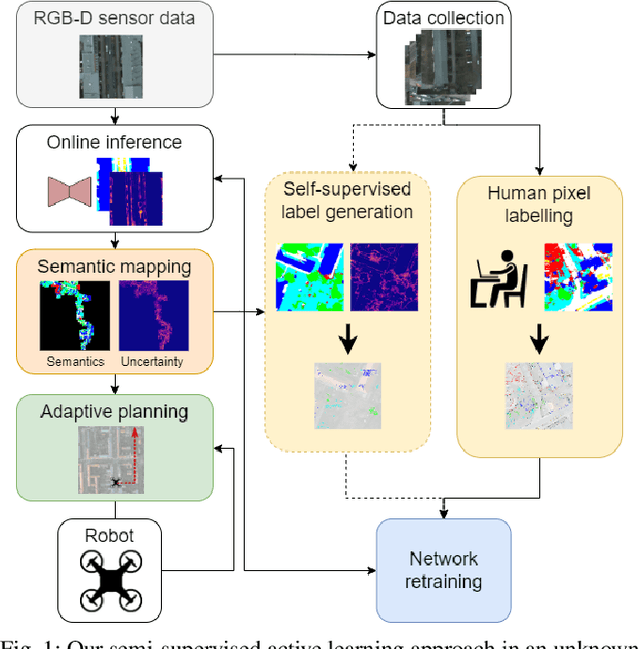
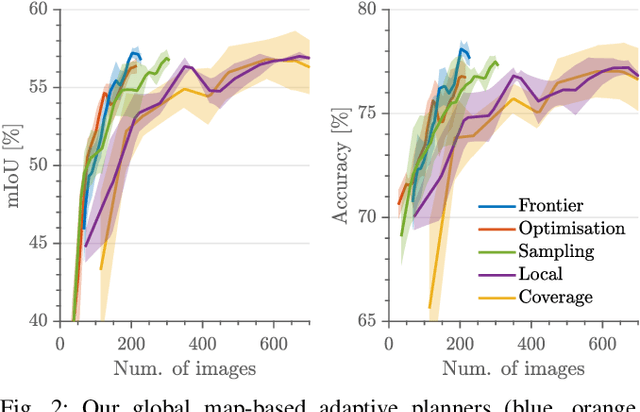
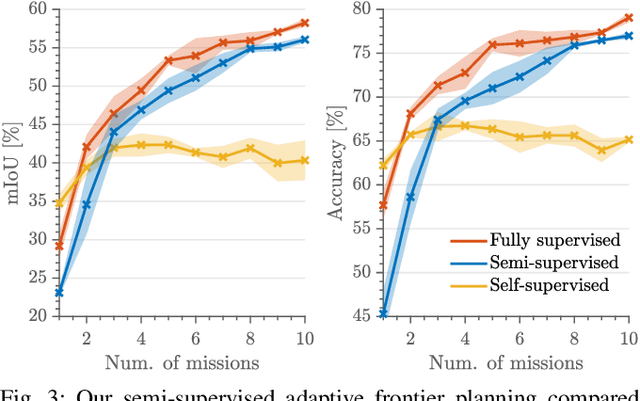
Robots need robust and flexible vision systems to perceive and reason about their environments beyond geometry. Most of such systems build upon deep learning approaches. As autonomous robots are commonly deployed in initially unknown environments, pre-training on static datasets cannot always capture the variety of domains and limits the robot's vision performance during missions. Recently, self-supervised as well as fully supervised active learning methods emerged to improve robotic vision. These approaches rely on large in-domain pre-training datasets or require substantial human labelling effort. To address these issues, we present a recent adaptive planning framework for efficient training data collection to substantially reduce human labelling requirements in semantic terrain monitoring missions. To this end, we combine high-quality human labels with automatically generated pseudo labels. Experimental results show that the framework reaches segmentation performance close to fully supervised approaches with drastically reduced human labelling effort while outperforming purely self-supervised approaches. We discuss the advantages and limitations of current methods and outline valuable future research avenues towards more robust and flexible robotic vision systems in unknown environments.