 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Indoor Localization Accuracy by Using an Efficient Implicit Neural Map Representation
Mar 30, 2025Globally localizing a mobile robot in a known map is often a foundation for enabling robots to navigate and operate autonomously. In indoor environments, traditional Monte Carlo localization based on occupancy grid maps is considered the gold standard, but its accuracy is limited by the representation capabilities of the occupancy grid map. In this paper, we address the problem of building an effective map representation that allows to accurately perform probabilistic global localization. To this end, we propose an implicit neural map representation that is able to capture positional and directional geometric features from 2D LiDAR scans to efficiently represent the environment and learn a neural network that is able to predict both, the non-projective signed distance and a direction-aware projective distance for an arbitrary point in the mapped environment. This combination of neural map representation with a light-weight neural network allows us to design an efficient observation model within a conventional Monte Carlo localization framework for pose estimation of a robot in real time. We evaluated our approach to indoor localization on a publicly available dataset for global localization and the experimental results indicate that our approach is able to more accurately localize a mobile robot than other localization approaches employing occupancy or existing neural map representations. In contrast to other approaches employing an implicit neural map representation for 2D LiDAR localization, our approach allows to perform real-time pose tracking after convergence and near real-time global localization. The code of our approach is available at: https://github.com/PRBonn/enm-mcl.
STAIR: Semantic-Targeted Active Implicit Reconstruction
Mar 17, 2024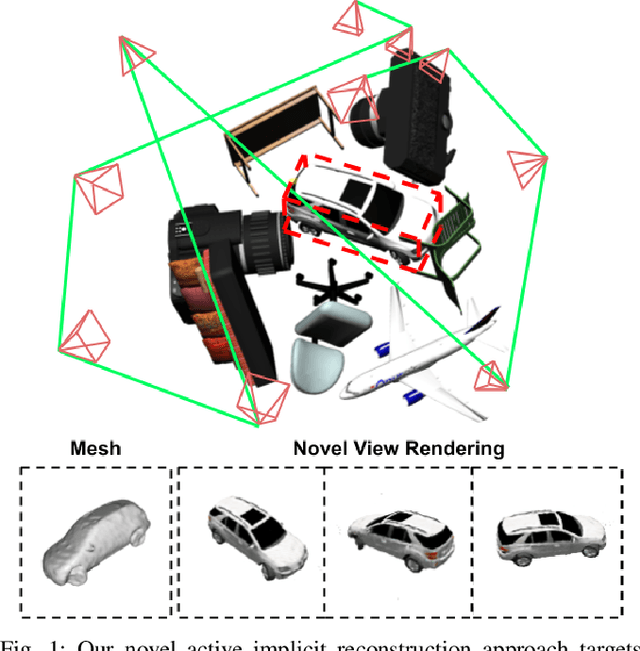
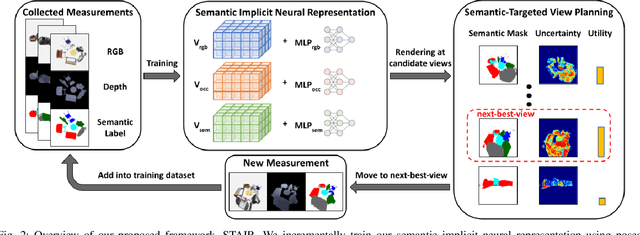

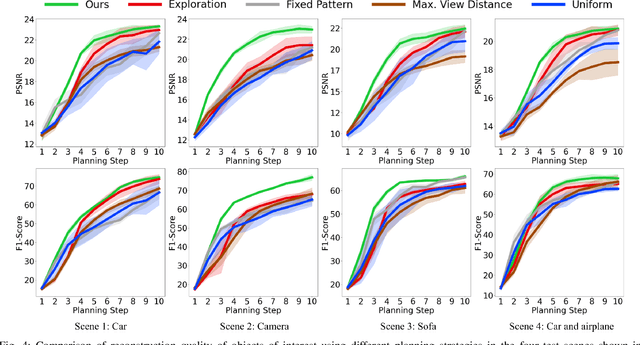
Many autonomous robotic applications require object-level understanding when deployed. Actively reconstructing objects of interest, i.e. objects with specific semantic meanings, is therefore relevant for a robot to perform downstream tasks in an initially unknown environment. In this work, we propose a novel framework for semantic-targeted active reconstruction using posed RGB-D measurements and 2D semantic labels as input. The key components of our framework are a semantic implicit neural representation and a compatible planning utility function based on semantic rendering and uncertainty estimation, enabling adaptive view planning to target objects of interest. Our planning approach achieves better reconstruction performance in terms of mesh and novel view rendering quality compared to implicit reconstruction baselines that do not consider semantics for view planning. Our framework further outperforms a state-of-the-art semantic-targeted active reconstruction pipeline based on explicit maps, justifying our choice of utilising implicit neural representations to tackle semantic-targeted active reconstruction problems.
IR-MCL: Implicit Representation-Based Online Global Localization
Oct 06, 2022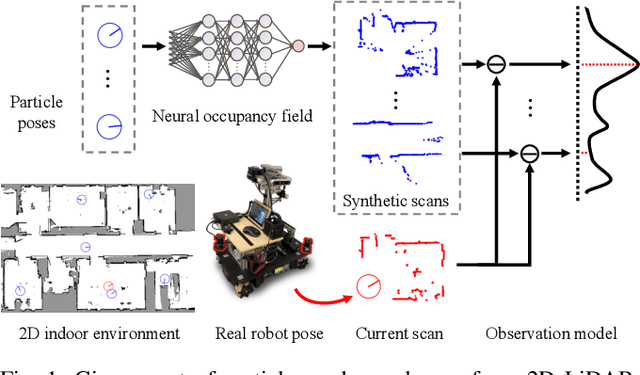
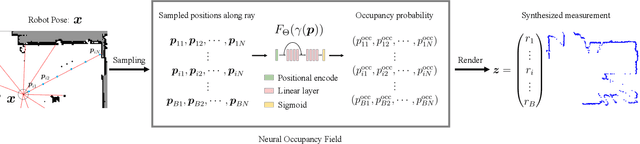
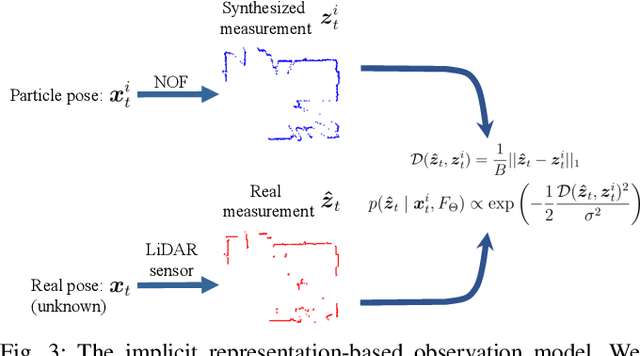
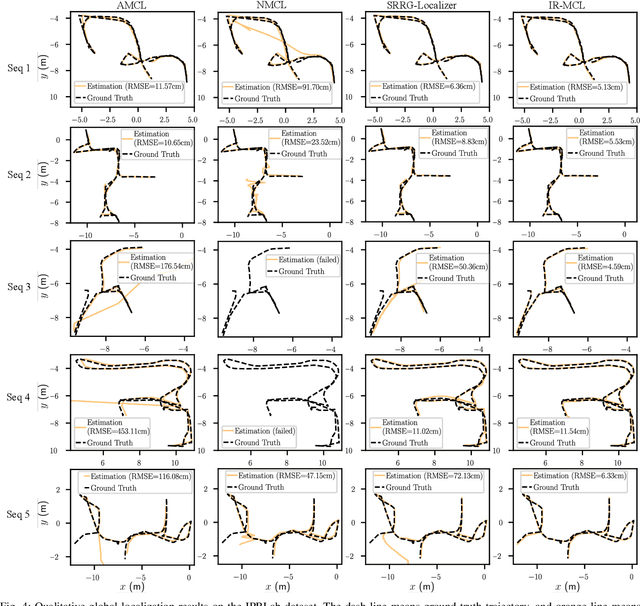
Determining the state of a mobile robot is an essential building block of robot navigation systems. In this paper, we address the problem of estimating the robots pose in an indoor environment using 2D LiDAR data and investigate how modern environment models can improve gold standard Monte-Carlo localization (MCL) systems. We propose a neural occupancy field (NOF) to implicitly represent the scene using a neural network. With the pretrained network, we can synthesize 2D LiDAR scans for an arbitrary robot pose through volume rendering. Based on the implicit representation, we can obtain the similarity between a synthesized and actual scan as an observation model and integrate it into an MCL system to perform accurate localization. We evaluate our approach on five sequences of a self-recorded dataset and three publicly available datasets. We show that we can accurately and efficiently localize a robot using our approach surpassing the localization performance of state-of-the-art methods. The experiments suggest that the presented implicit representation is able to predict more accurate 2D LiDAR scans leading to an improved observation model for our particle filter-based localization. The code of our approach is released at: https://github.com/PRBonn/ir-mcl.
Video Contrastive Learning with Global Context
Aug 05, 2021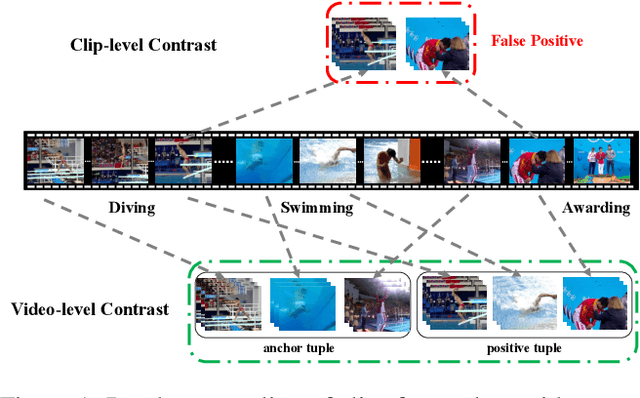



Contrastive learning has revolutionized self-supervised image representation learning field, and recently been adapted to video domain. One of the greatest advantages of contrastive learning is that it allows us to flexibly define powerful loss objectives as long as we can find a reasonable way to formulate positive and negative samples to contrast. However, existing approaches rely heavily on the short-range spatiotemporal salience to form clip-level contrastive signals, thus limit themselves from using global context. In this paper, we propose a new video-level contrastive learning method based on segments to formulate positive pairs. Our formulation is able to capture global context in a video, thus robust to temporal content change. We also incorporate a temporal order regularization term to enforce the inherent sequential structure of videos. Extensive experiments show that our video-level contrastive learning framework (VCLR) is able to outperform previous state-of-the-arts on five video datasets for downstream action classification, action localization and video retrieval. Code is available at https://github.com/amazon-research/video-contrastive-learning.
Fast 2D Map Matching Based on Area Graphs
Nov 18, 2019
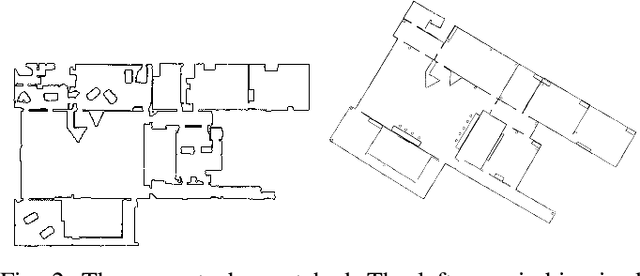
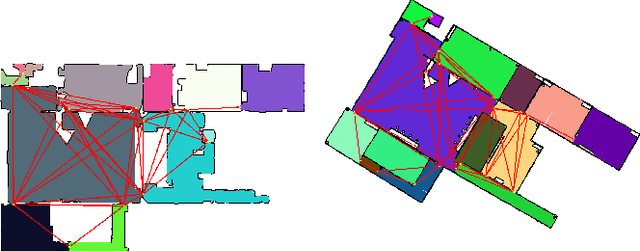

We present a novel area matching algorithm for merging two different 2D grid maps. There are many approaches to address this problem, nevertheless, most previous work is built on some assumptions, such as rigid transformation, or similar scale and modalities of two maps. In this work we propose a 2D map matching algorithm based on area segmentation. We transfer general 2D occupancy grid maps to an area graph representation, then compute the correct results by voting in that space. In the experiments, we compare with a state-of-the-art method applied to the matching of sensor maps with ground truth layout maps. The experiment shows that our algorithm has a better performance on large-scale maps and a faster computation speed.
Pose Estimation for Omni-directional Cameras using Sinusoid Fitting
Oct 03, 2019
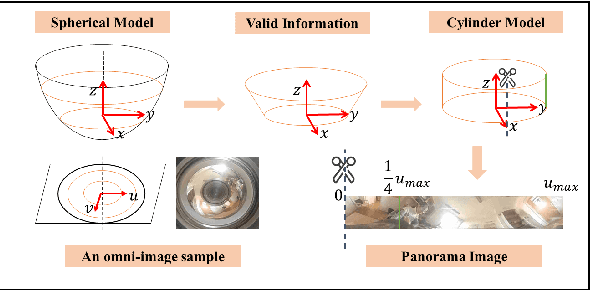
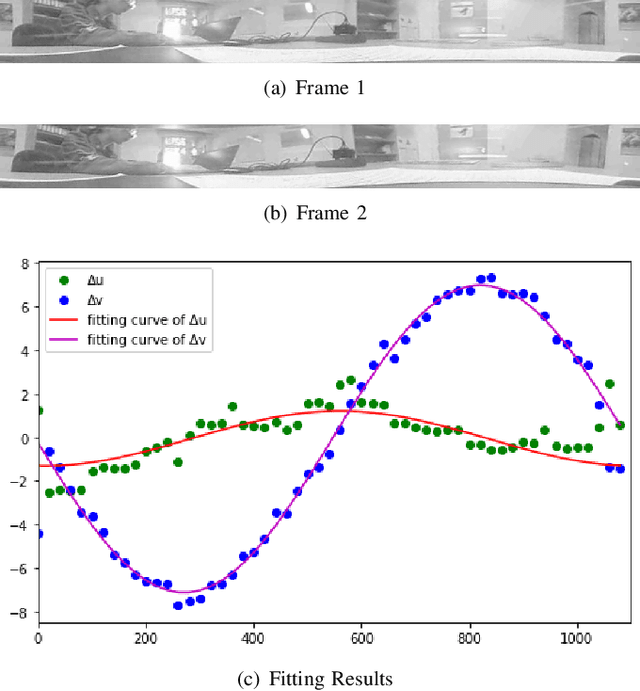

We propose a novel pose estimation method for geometric vision of omni-directional cameras. On the basis of the regularity of the pixel movement after camera pose changes, we formulate and prove the sinusoidal relationship between pixels movement and camera motion. We use the improved Fourier-Mellin invariant (iFMI) algorithm to find the motion of pixels, which was shown to be more accurate and robust than the feature-based methods. While iFMI works only on pin-hole model images and estimates 4 parameters (x, y, yaw, scaling), our method works on panoramic images and estimates the full 6 DoF 3D transform, up to an unknown scale factor. For that we fit the motion of the pixels in the panoramic images, as determined by iFMI, to two sinusoidal functions. The offsets, amplitudes and phase-shifts of the two functions then represent the 3D rotation and translation of the camera between the two images. We perform experiments for 3D rotation, which show that our algorithm outperforms the feature-based methods in accuracy and robustness. We leave the more complex 3D translation experiments for future work.
Depth Estimation on Underwater Omni-directional Images Using a Deep Neural Network
May 23, 2019
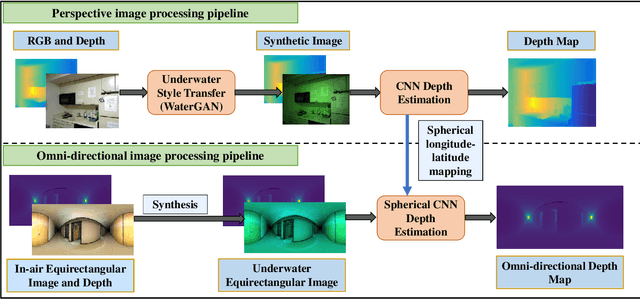
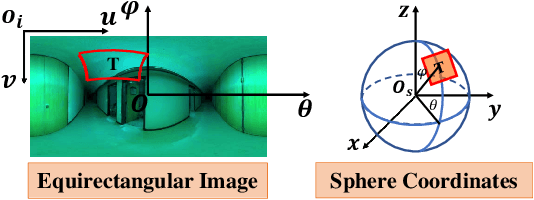

In this work, we exploit a depth estimation Fully Convolutional Residual Neural Network (FCRN) for in-air perspective images to estimate the depth of underwater perspective and omni-directional images. We train one conventional and one spherical FCRN for underwater perspective and omni-directional images, respectively. The spherical FCRN is derived from the perspective FCRN via a spherical longitude-latitude mapping. For that, the omni-directional camera is modeled as a sphere, while images captured by it are displayed in the longitude-latitude form. Due to the lack of underwater datasets, we synthesize images in both data-driven and theoretical ways, which are used in training and testing. Finally, experiments are conducted on these synthetic images and results are displayed in both qualitative and quantitative way. The comparison between ground truth and the estimated depth map indicates the effectiveness of our method.
Fast Gaussian Process Occupancy Maps
Nov 26, 2018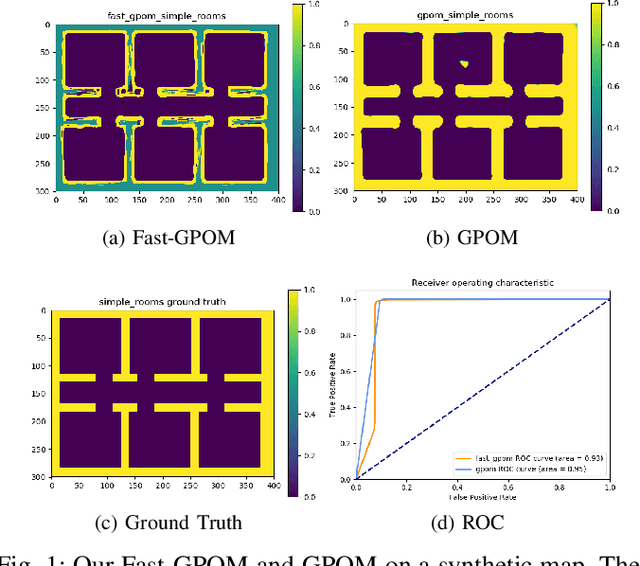

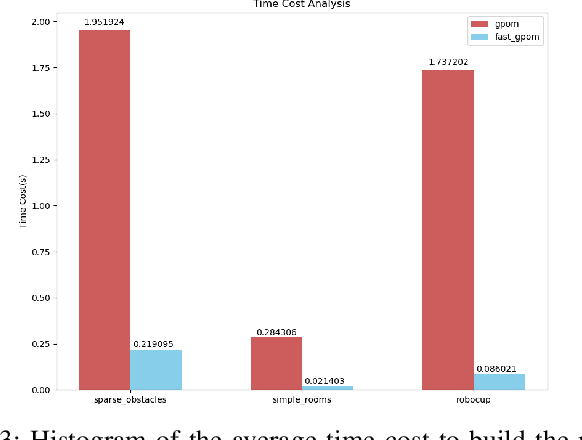

In this paper, we demonstrate our work on Gaussian Process Occupancy Mapping (GPOM). We concentrate on the inefficiency of the frame computation of the classical GPOM approaches. In robotics, most of the algorithms are required to run in real time. However, the high cost of computation makes the classical GPOM less useful. In this paper we dont try to optimize the Gaussian Process itself, instead, we focus on the application. By analyzing the time cost of each step of the algorithm, we find a way that to reduce the cost while maintaining a good performance compared to the general GPOM framework. From our experiments, we can find that our model enables GPOM to run online and achieve a relatively better quality than the classical GPOM.