 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELA-ZSON: Efficient Layout-Aware Zero-Shot Object Navigation Agent with Hierarchical Planning
May 09, 2025We introduce ELA-ZSON, an efficient layout-aware zero-shot object navigation (ZSON) approach designed for complex multi-room indoor environments. By planning hierarchically leveraging a global topologigal map with layout information and local imperative approach with detailed scene representation memory, ELA-ZSON achieves both efficient and effective navigation. The process is managed by an LLM-powered agent, ensuring seamless effective planning and navigation, without the need for human interaction, complex rewards, or costly training. Our experimental results on the MP3D benchmark achieves 85\% object navigation success rate (SR) and 79\% success rate weighted by path length (SPL) (over 40\% point improvement in SR and 60\% improvement in SPL compared to exsisting methods). Furthermore, we validate the robustness of our approach through virtual agent and real-world robotic deployment, showcasing its capability in practical scenarios. See https://anonymous.4open.science/r/ELA-ZSON-C67E/ for details.
LOP-Field: Brain-inspired Layout-Object-Position Fields for Robotic Scene Understanding
Jun 11, 2024Spatial cognition empowers animals with remarkably efficient navigation abilities, largely depending on the scene-level understanding of spatial environments. Recently, it has been found that a neural population in the postrhinal cortex of rat brains is more strongly tuned to the spatial layout rather than objects in a scene. Inspired by the representations of spatial layout in local scenes to encode different regions separately, we proposed LOP-Field that realizes the Layout-Object-Position(LOP) association to model the hierarchical representations for robotic scene understanding. Powered by foundation models and implicit scene representation, a neural field is implemented as a scene memory for robots, storing a queryable representation of scenes with position-wise, object-wise, and layout-wise information. To validate the built LOP association, the model is tested to infer region information from 3D positions with quantitative metrics, achieving an average accuracy of more than 88\%. It is also shown that the proposed method using region information can achieve improved object and view localization results with text and RGB input compared to state-of-the-art localization methods.
FastOcc: Accelerating 3D Occupancy Prediction by Fusing the 2D Bird's-Eye View and Perspective View
Mar 05, 2024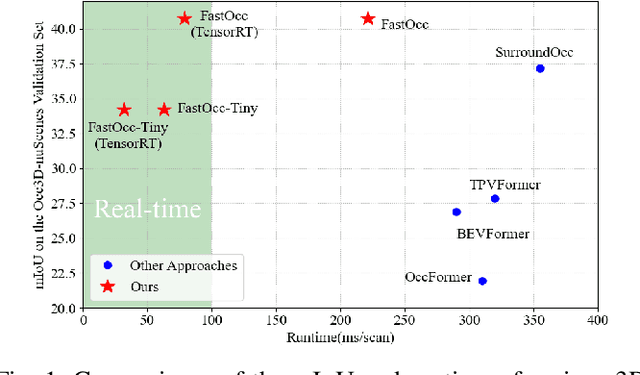
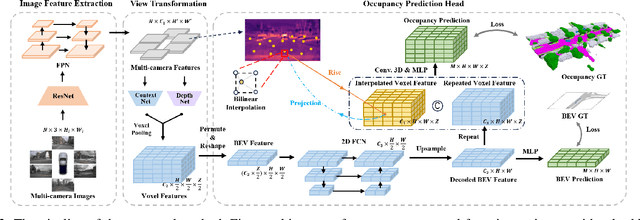
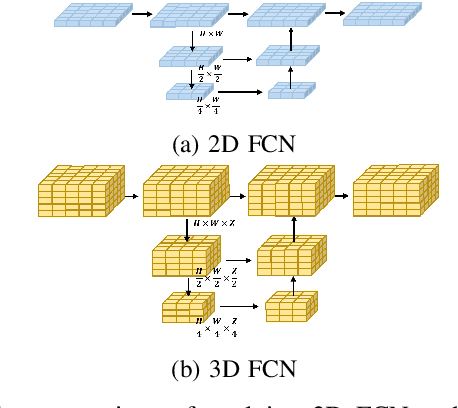
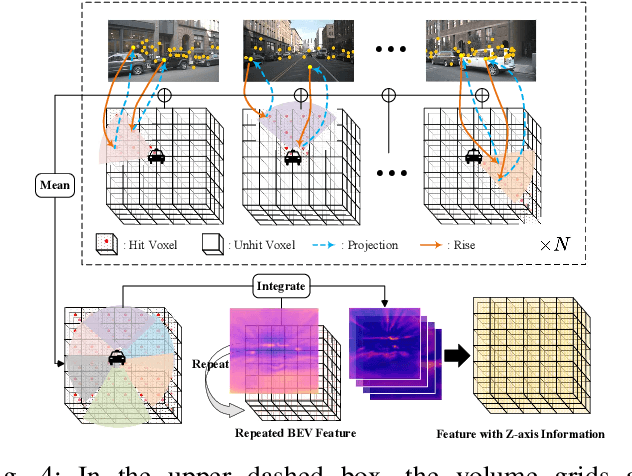
In autonomous driving, 3D occupancy prediction outputs voxel-wise status and semantic labels for more comprehensive understandings of 3D scenes compared with traditional perception tasks, such as 3D object detection and bird's-eye view (BEV) semantic segmentation. Recent researchers have extensively explored various aspects of this task, including view transformation techniques, ground-truth label generation, and elaborate network design, aiming to achieve superior performance. However, the inference speed, crucial for running on an autonomous vehicle, is neglected. To this end, a new method, dubbed FastOcc, is proposed. By carefully analyzing the network effect and latency from four parts, including the input image resolution, image backbone, view transformation, and occupancy prediction head, it is found that the occupancy prediction head holds considerable potential for accelerating the model while keeping its accuracy. Targeted at improving this component, the time-consuming 3D convolution network is replaced with a novel residual-like architecture, where features are mainly digested by a lightweight 2D BEV convolution network and compensated by integrating the 3D voxel features interpolated from the original image features. Experiments on the Occ3D-nuScenes benchmark demonstrate that our FastOcc achieves state-of-the-art results with a fast inference speed.
SUPS: A Simulated Underground Parking Scenario Dataset for Autonomous Driving
Feb 25, 2023
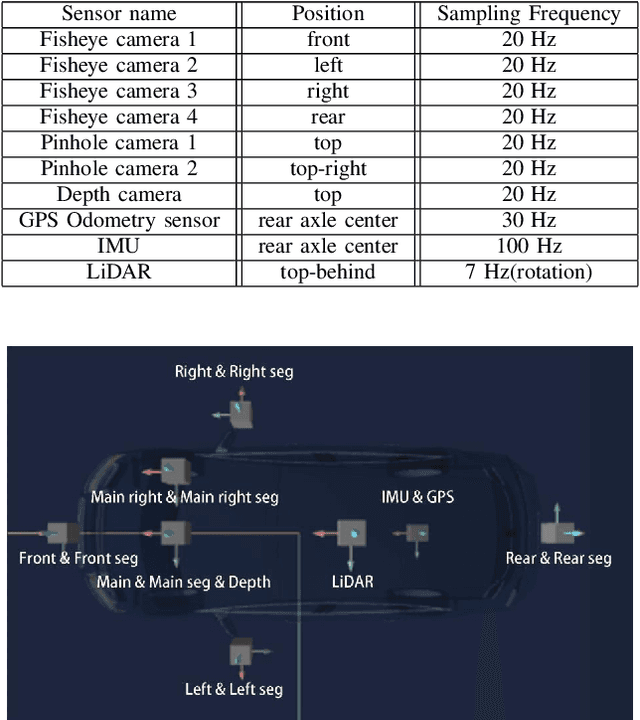

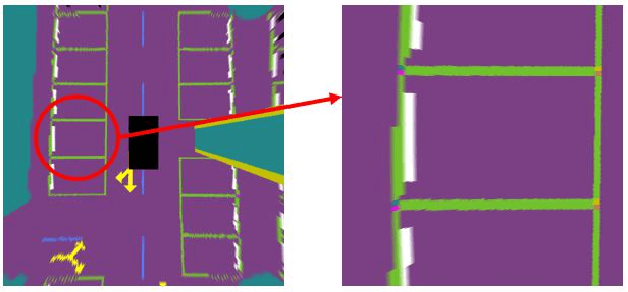
Automatic underground parking has attracted considerable attention as the scope of autonomous driving expands. The auto-vehicle is supposed to obtain the environmental information, track its location, and build a reliable map of the scenario. Mainstream solutions consist of well-trained neural networks and simultaneous localization and mapping (SLAM) methods, which need numerous carefully labeled images and multiple sensor estimations. However, there is a lack of underground parking scenario datasets with multiple sensors and well-labeled images that support both SLAM tasks and perception tasks, such as semantic segmentation and parking slot detection. In this paper, we present SUPS, a simulated dataset for underground automatic parking, which supports multiple tasks with multiple sensors and multiple semantic labels aligned with successive images according to timestamps. We intend to cover the defect of existing datasets with the variability of environments and the diversity and accessibility of sensors in the virtual scene. Specifically, the dataset records frames from four surrounding fisheye cameras, two forward pinhole cameras, a depth camera, and data from LiDAR, inertial measurement unit (IMU), GNSS. Pixel-level semantic labels are provided for objects, especially ground signs such as arrows, parking lines, lanes, and speed bumps. Perception, 3D reconstruction, depth estimation, and SLAM, and other relative tasks are supported by our dataset. We also evaluate the state-of-the-art SLAM algorithms and perception models on our dataset. Finally, we open source our virtual 3D scene built based on Unity Engine and release our dataset at https://github.com/jarvishou829/SUPS.
Hierarchical Topometric Representation of 3D Robotic Maps
Nov 24, 2021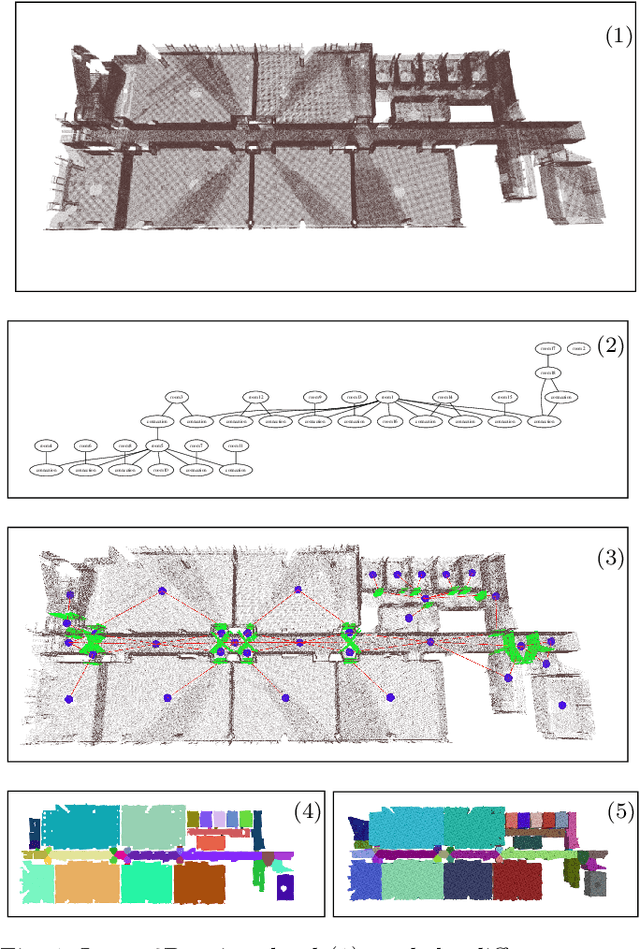

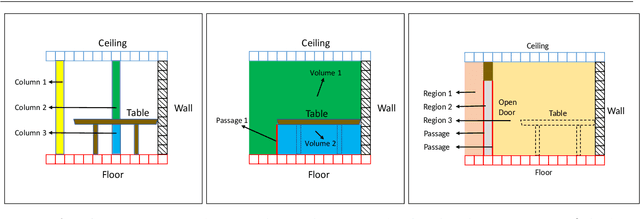
In this paper, we propose a method for generating a hierarchical, volumetric topological map from 3D point clouds. There are three basic hierarchical levels in our map: $storey - region - volume$. The advantages of our method are reflected in both input and output. In terms of input, we accept multi-storey point clouds and building structures with sloping roofs or ceilings. In terms of output, we can generate results with metric information of different dimensionality, that are suitable for different robotics applications. The algorithm generates the volumetric representation by generating $volumes$ from a 3D voxel occupancy map. We then add $passage$s (connections between $volumes$), combine small $volumes$ into a big $region$ and use a 2D segmentation method for better topological representation. We evaluate our method on several freely available datasets. The experiments highlight the advantages of our approach.
* Temporarily
QA4PRF: A Question Answering based Framework for Pseudo Relevance Feedback
Nov 16, 2021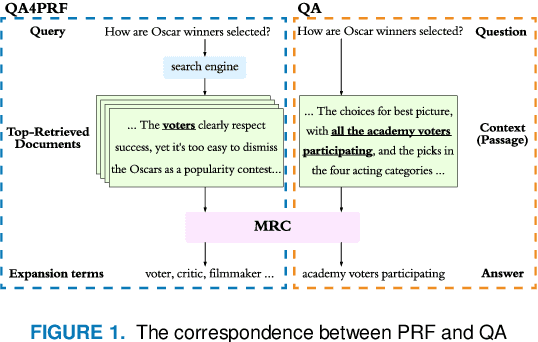

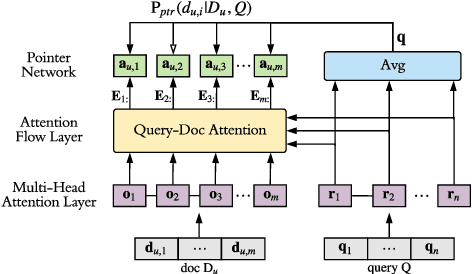

Pseudo relevance feedback (PRF) automatically performs query expansion based on top-retrieved documents to better represent the user's information need so as to improve the search results. Previous PRF methods mainly select expansion terms with high occurrence frequency in top-retrieved documents or with high semantic similarity with the original query. However, existing PRF methods hardly try to understand the content of documents, which is very important in performing effective query expansion to reveal the user's information need. In this paper, we propose a QA-based framework for PRF called QA4PRF to utilize contextual information in documents. In such a framework, we formulate PRF as a QA task, where the query and each top-retrieved document play the roles of question and context in the corresponding QA system, while the objective is to find some proper terms to expand the original query by utilizing contextual information, which are similar answers in QA task. Besides, an attention-based pointer network is built on understanding the content of top-retrieved documents and selecting the terms to represent the original query better. We also show that incorporating the traditional supervised learning methods, such as LambdaRank, to integrate PRF information will further improve the performance of QA4PRF. Extensive experiments on three real-world datasets demonstrate that QA4PRF significantly outperforms the state-of-the-art methods.
Self-supervised Point Set Local Descriptors for Point Cloud Registration
Mar 11, 2020
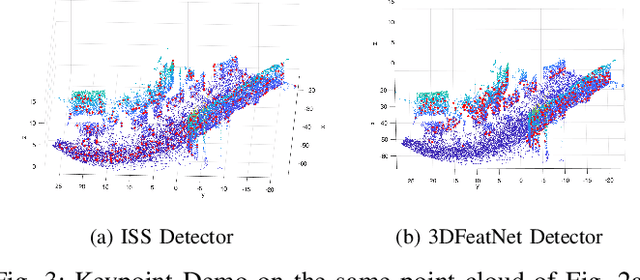
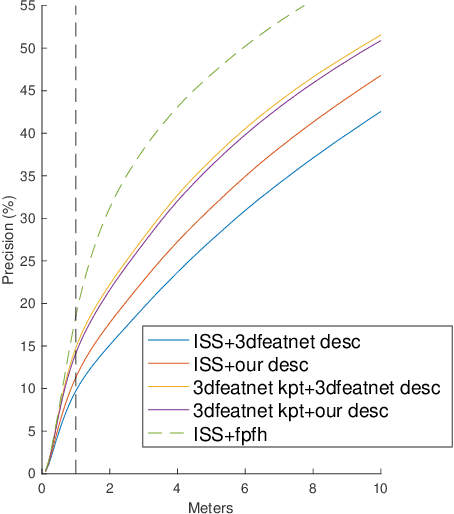
In this work, we propose to learn local descriptors for point clouds in a self-supervised manner. In each iteration of the training, the input of the network is merely one unlabeled point cloud. On top of our previous work, that directly solves the transformation between two point sets in one step without correspondences, the proposed method is able to train from one point cloud, by supervising its self-rotation, that we randomly generate. The whole training requires no manual annotation. In several experiments we evaluate the performance of our method on various datasets and compare to other state of the art algorithms. The results show, that our self-supervised learned descriptor achieves equivalent or even better performance than the supervised learned model, while being easier to train and not requiring labeled data.
Fast 2D Map Matching Based on Area Graphs
Nov 18, 2019
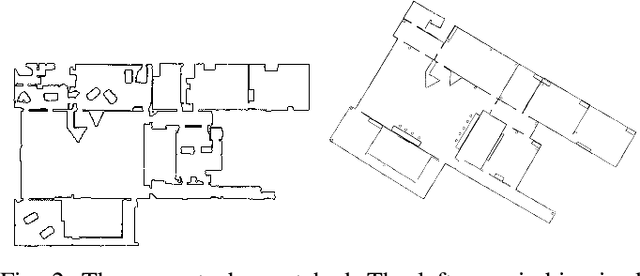
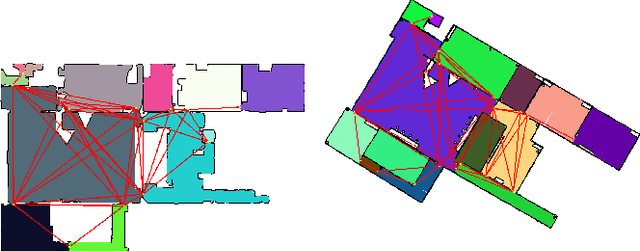

We present a novel area matching algorithm for merging two different 2D grid maps. There are many approaches to address this problem, nevertheless, most previous work is built on some assumptions, such as rigid transformation, or similar scale and modalities of two maps. In this work we propose a 2D map matching algorithm based on area segmentation. We transfer general 2D occupancy grid maps to an area graph representation, then compute the correct results by voting in that space. In the experiments, we compare with a state-of-the-art method applied to the matching of sensor maps with ground truth layout maps. The experiment shows that our algorithm has a better performance on large-scale maps and a faster computation speed.
Furniture Free Mapping using 3D Lidars
Nov 15, 2019

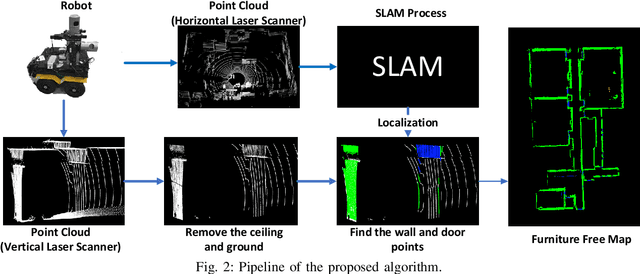

Mobile robots depend on maps for localization, planning, and other applications. In indoor scenarios, there is often lots of clutter present, such as chairs, tables, other furniture, or plants. While mapping this clutter is important for certain applications, for example navigation, maps that represent just the immobile parts of the environment, i.e. walls, are needed for other applications, like room segmentation or long-term localization. In literature, approaches can be found that use a complete point cloud to remove the furniture in the room and generate a furniture free map. In contrast, we propose a Simultaneous Localization And Mapping (SLAM)-based mobile laser scanning solution. The robot uses an orthogonal pair of Lidars. The horizontal scanner aims to estimate the robot position, whereas the vertical scanner generates the furniture free map. There are three steps in our method: point cloud rearrangement, wall plane detection and semantic labeling. In the experiment, we evaluate the efficiency of removing furniture in a typical indoor environment. We get $99.60\%$ precision in keeping the wall in the 3D result, which shows that our algorithm can remove most of the furniture in the environment. Furthermore, we introduce the application of 2D furniture free mapping for room segmentation.
Area Graph: Generation of Topological Maps using the Voronoi Diagram
Oct 01, 2019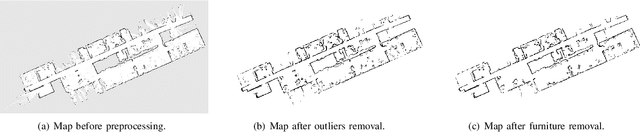
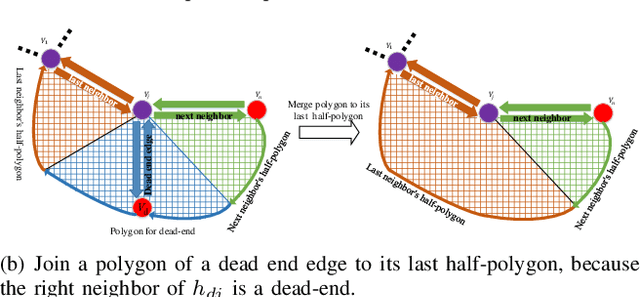
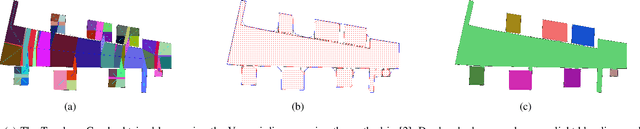
Representing a scanned map of the real environment as a topological structure is an important research topic in robotics. Since topological representations of maps save a huge amount of map storage space and online computing time, they are widely used in fields such as path planning, map matching, and semantic mapping. We use a topological map representation, the Area Graph, in which the vertices represent areas and edges represent passages. The Area Graph is developed from a pruned Voronoi Graph, the Topology Graph. We also employ a simple room detection algorithm to compensate the fact that the Voronoi Graph gets unstable in open areas. We claim that our area segmentation method is superior to state-of-the-art approaches in complex indoor environments and support this claim with a number of experiments.