 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQA4PRF: A Question Answering based Framework for Pseudo Relevance Feedback
Nov 16, 2021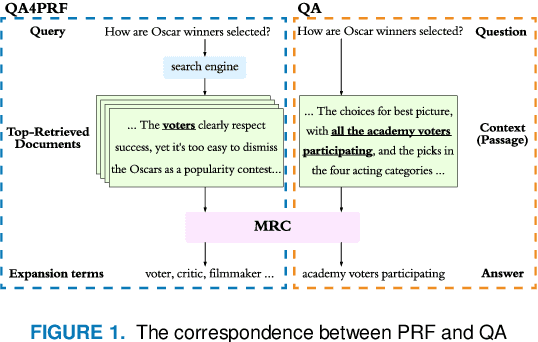

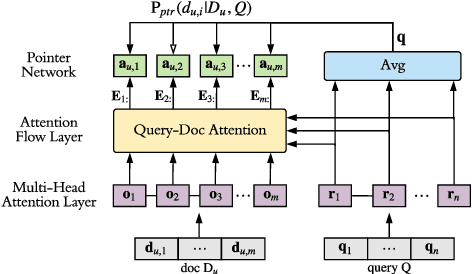

Pseudo relevance feedback (PRF) automatically performs query expansion based on top-retrieved documents to better represent the user's information need so as to improve the search results. Previous PRF methods mainly select expansion terms with high occurrence frequency in top-retrieved documents or with high semantic similarity with the original query. However, existing PRF methods hardly try to understand the content of documents, which is very important in performing effective query expansion to reveal the user's information need. In this paper, we propose a QA-based framework for PRF called QA4PRF to utilize contextual information in documents. In such a framework, we formulate PRF as a QA task, where the query and each top-retrieved document play the roles of question and context in the corresponding QA system, while the objective is to find some proper terms to expand the original query by utilizing contextual information, which are similar answers in QA task. Besides, an attention-based pointer network is built on understanding the content of top-retrieved documents and selecting the terms to represent the original query better. We also show that incorporating the traditional supervised learning methods, such as LambdaRank, to integrate PRF information will further improve the performance of QA4PRF. Extensive experiments on three real-world datasets demonstrate that QA4PRF significantly outperforms the state-of-the-art methods.
Deep Unsupervised Active Learning on Learnable Graphs
Nov 08, 2021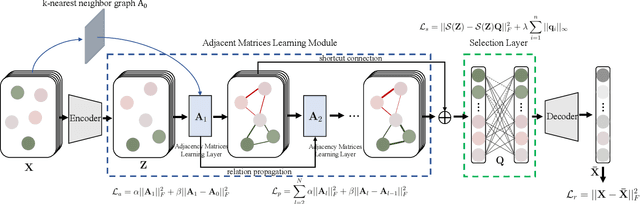
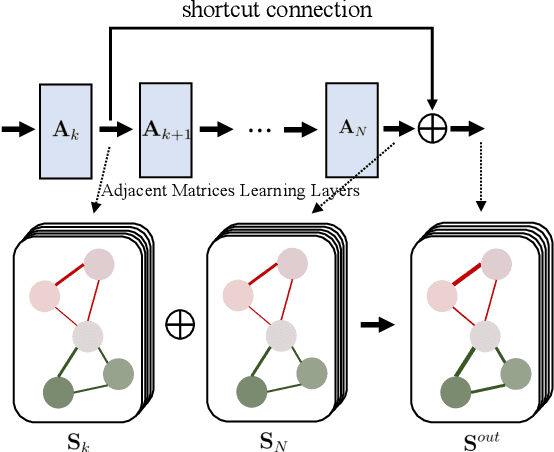
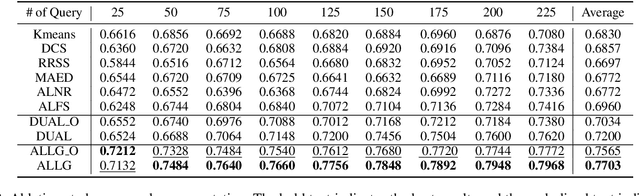
Recently deep learning has been successfully applied to unsupervised active learning. However, current method attempts to learn a nonlinear transformation via an auto-encoder while ignoring the sample relation, leaving huge room to design more effective representation learning mechanisms for unsupervised active learning. In this paper, we propose a novel deep unsupervised Active Learning model via Learnable Graphs, named ALLG. ALLG benefits from learning optimal graph structures to acquire better sample representation and select representative samples. To make the learnt graph structure more stable and effective, we take into account $k$-nearest neighbor graph as a priori, and learn a relation propagation graph structure. We also incorporate shortcut connections among different layers, which can alleviate the well-known over-smoothing problem to some extent. To the best of our knowledge, this is the first attempt to leverage graph structure learning for unsupervised active learning. Extensive experiments performed on six datasets demonstrate the efficacy of our method.
On Deep Unsupervised Active Learning
Jul 28, 2020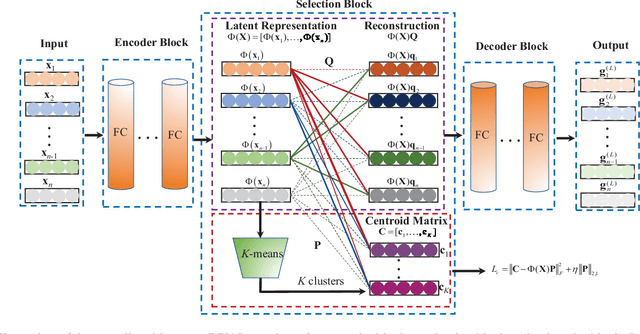
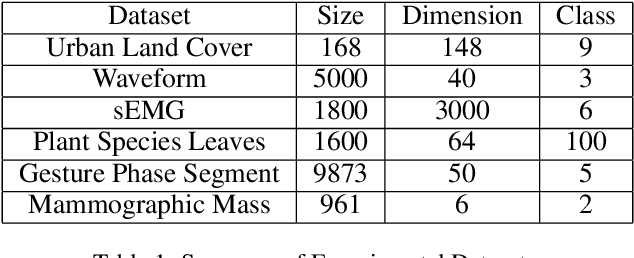
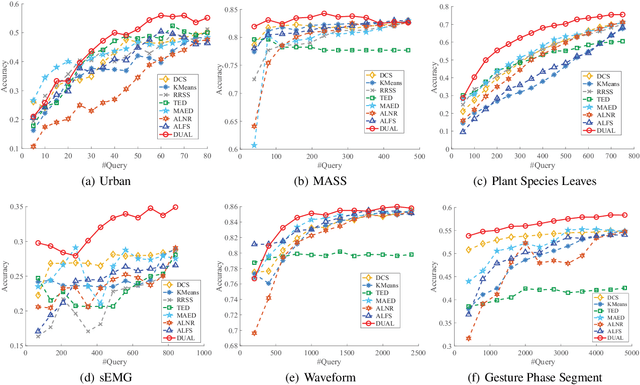
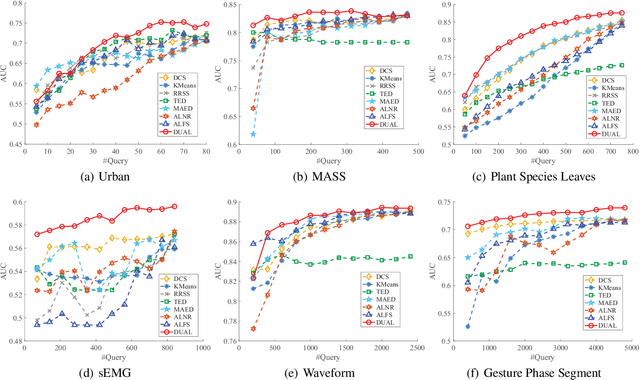
Unsupervised active learning has attracted increasing attention in recent years, where its goal is to select representative samples in an unsupervised setting for human annotating. Most existing works are based on shallow linear models by assuming that each sample can be well approximated by the span (i.e., the set of all linear combinations) of certain selected samples, and then take these selected samples as representative ones to label. However, in practice, the data do not necessarily conform to linear models, and how to model nonlinearity of data often becomes the key point to success. In this paper, we present a novel Deep neural network framework for Unsupervised Active Learning, called DUAL. DUAL can explicitly learn a nonlinear embedding to map each input into a latent space through an encoder-decoder architecture, and introduce a selection block to select representative samples in the the learnt latent space. In the selection block, DUAL considers to simultaneously preserve the whole input patterns as well as the cluster structure of data. Extensive experiments are performed on six publicly available datasets, and experimental results clearly demonstrate the efficacy of our method, compared with state-of-the-arts.