 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQA4PRF: A Question Answering based Framework for Pseudo Relevance Feedback
Nov 16, 2021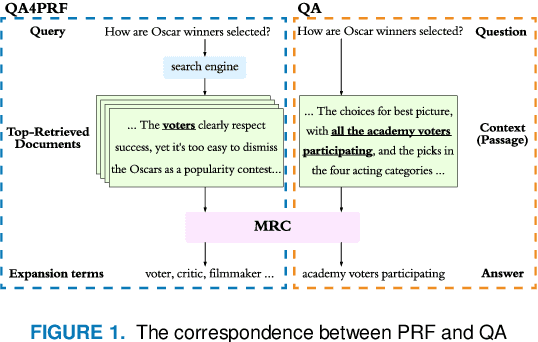

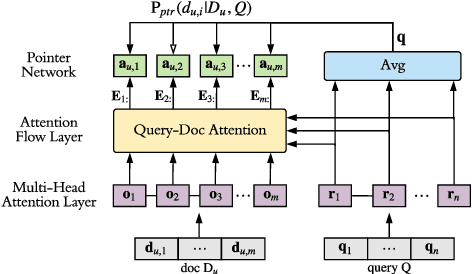

Pseudo relevance feedback (PRF) automatically performs query expansion based on top-retrieved documents to better represent the user's information need so as to improve the search results. Previous PRF methods mainly select expansion terms with high occurrence frequency in top-retrieved documents or with high semantic similarity with the original query. However, existing PRF methods hardly try to understand the content of documents, which is very important in performing effective query expansion to reveal the user's information need. In this paper, we propose a QA-based framework for PRF called QA4PRF to utilize contextual information in documents. In such a framework, we formulate PRF as a QA task, where the query and each top-retrieved document play the roles of question and context in the corresponding QA system, while the objective is to find some proper terms to expand the original query by utilizing contextual information, which are similar answers in QA task. Besides, an attention-based pointer network is built on understanding the content of top-retrieved documents and selecting the terms to represent the original query better. We also show that incorporating the traditional supervised learning methods, such as LambdaRank, to integrate PRF information will further improve the performance of QA4PRF. Extensive experiments on three real-world datasets demonstrate that QA4PRF significantly outperforms the state-of-the-art methods.
AIM: Automatic Interaction Machine for Click-Through Rate Prediction
Nov 05, 2021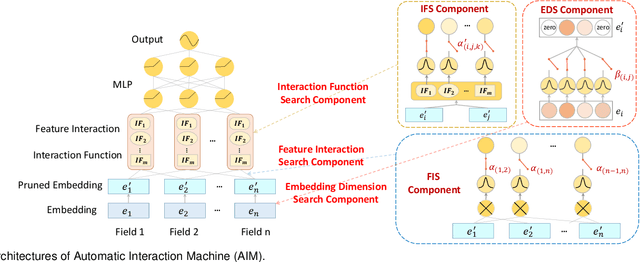
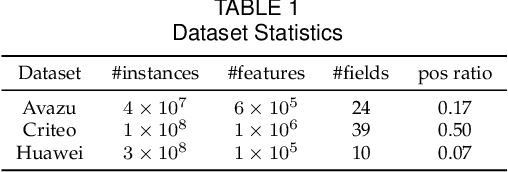
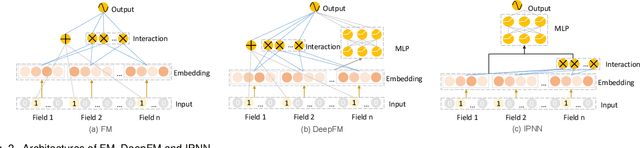
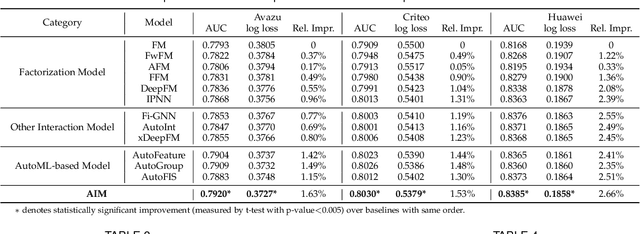
Feature embedding learning and feature interaction modeling are two crucial components of deep models for Click-Through Rate (CTR) prediction. Most existing deep CTR models suffer from the following three problems. First, feature interactions are either manually designed or simply enumerated. Second, all the feature interactions are modeled with an identical interaction function. Third, in most existing models, different features share the same embedding size which leads to memory inefficiency. To address these three issues mentioned above, we propose Automatic Interaction Machine (AIM) with three core components, namely, Feature Interaction Search (FIS), Interaction Function Search (IFS) and Embedding Dimension Search (EDS), to select significant feature interactions, appropriate interaction functions and necessary embedding dimensions automatically in a unified framework. Specifically, FIS component automatically identifies different orders of essential feature interactions with useless ones pruned; IFS component selects appropriate interaction functions for each individual feature interaction in a learnable way; EDS component automatically searches proper embedding size for each feature. Offline experiments on three large-scale datasets validate the superior performance of AIM. A three-week online A/B test in the recommendation service of a mainstream app market shows that AIM improves DeepFM model by 4.4% in terms of CTR.
Ensembled CTR Prediction via Knowledge Distillation
Nov 08, 2020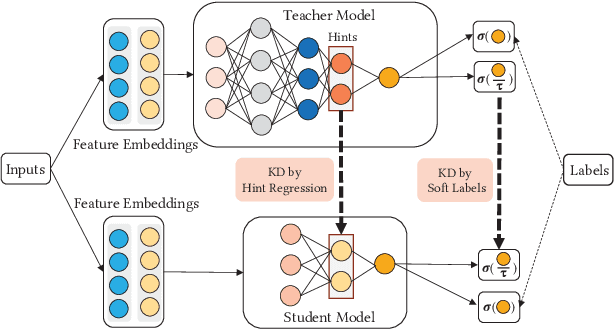
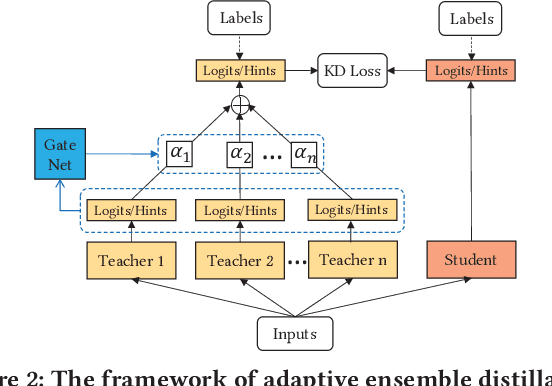
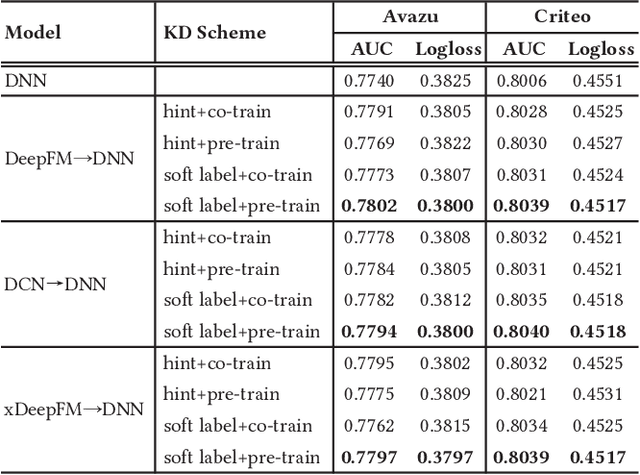
Recently, deep learning-based models have been widely studied for click-through rate (CTR) prediction and lead to improved prediction accuracy in many industrial applications. However, current research focuses primarily on building complex network architectures to better capture sophisticated feature interactions and dynamic user behaviors. The increased model complexity may slow down online inference and hinder its adoption in real-time applications. Instead, our work targets at a new model training strategy based on knowledge distillation (KD). KD is a teacher-student learning framework to transfer knowledge learned from a teacher model to a student model. The KD strategy not only allows us to simplify the student model as a vanilla DNN model but also achieves significant accuracy improvements over the state-of-the-art teacher models. The benefits thus motivate us to further explore the use of a powerful ensemble of teachers for more accurate student model training. We also propose some novel techniques to facilitate ensembled CTR prediction, including teacher gating and early stopping by distillation loss. We conduct comprehensive experiments against 12 existing models and across three industrial datasets. Both offline and online A/B testing results show the effectiveness of our KD-based training strategy.
AutoFIS: Automatic Feature Interaction Selection in Factorization Models for Click-Through Rate Prediction
Mar 26, 2020

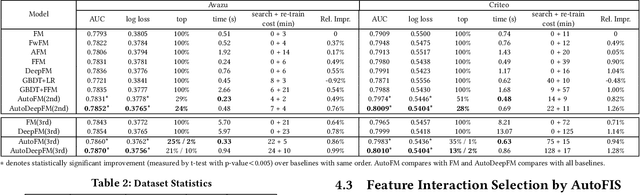
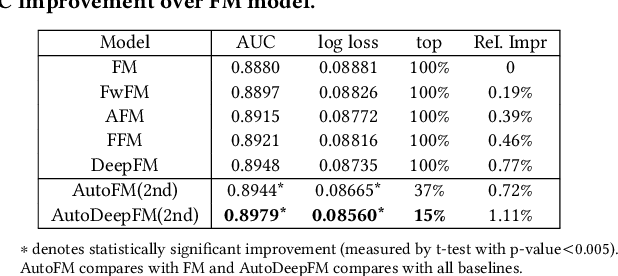
Learning effective feature interactions is crucial for click-through rate (CTR) prediction tasks in recommender systems. In most of the existing deep learning models, feature interactions are either manually designed or simply enumerated. However, enumerating all feature interactions brings large memory and computation cost. Even worse, useless interactions may introduce unnecessary noise and complicate the training process. In this work, we propose a two-stage algorithm called Automatic Feature Interaction Selection (AutoFIS). AutoFIS can automatically identify all the important feature interactions for factorization models with just the computational cost equivalent to training the target model to convergence. In the \emph{search stage}, instead of searching over a discrete set of candidate feature interactions, we relax the choices to be continuous by introducing the architecture parameters. By implementing a regularized optimizer over the architecture parameters, the model can automatically identify and remove the redundant feature interactions during the training process of the model. In the \emph{re-train stage}, we keep the architecture parameters serving as an attention unit to further boost the performance. Offline experiments on three large-scale datasets (two public benchmarks, one private) demonstrate that the proposed AutoFIS can significantly improve various FM based models. AutoFIS has been deployed onto the training platform of Huawei App Store recommendation service, where a 10-day online A/B test demonstrated that AutoFIS improved the DeepFM model by 20.3\% and 20.1\% in terms of CTR and CVR respectively.