 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplet4R: Geometric Complete 4D Reconstruction
Mar 28, 2026We introduce Complet4R, a novel end-to-end framework for Geometric Complete 4D Reconstruction, which aims to recover temporally coherent and geometrically complete reconstruction for dynamic scenes. Our method formalizes the task of Geometric Complete 4D Reconstruction as a unified framework of reconstruction and completion, by directly accumulating full contexts onto each frame. Unlike previous approaches that rely on pairwise reconstruction or local motion estimation, Complet4R utilizes a decoder-only transformer to operate all context globally directly from sequential video input, reconstructing a complete geometry for every single timestamp, including occluded regions visible in other frames. Our method demonstrates the state-of-the-art performance on our proposed benchmark for Geometric Complete 4D Reconstruction and the 3D Point Tracking task. Code will be released to support future research.
SceneFactory: A Workflow-centric and Unified Framework for Incremental Scene Modeling
May 13, 2024



We present SceneFactory, a workflow-centric and unified framework for incremental scene modeling, that supports conveniently a wide range of applications, such as (unposed and/or uncalibrated) multi-view depth estimation, LiDAR completion, (dense) RGB-D/RGB-L/Mono//Depth-only reconstruction and SLAM. The workflow-centric design uses multiple blocks as the basis for building different production lines. The supported applications, i.e., productions avoid redundancy in their designs. Thus, the focus is on each block itself for independent expansion. To support all input combinations, our implementation consists of four building blocks in SceneFactory: (1) Mono-SLAM, (2) depth estimation, (3) flexion and (4) scene reconstruction. Furthermore, we propose an unposed & uncalibrated multi-view depth estimation model (U2-MVD) to estimate dense geometry. U2-MVD exploits dense bundle adjustment for solving for poses, intrinsics, and inverse depth. Then a semantic-awared ScaleCov step is introduced to complete the multi-view depth. Relying on U2-MVD, SceneFactory both supports user-friendly 3D creation (with just images) and bridges the applications of Dense RGB-D and Dense Mono. For high quality surface and color reconstruction, we propose due-purpose Multi-resolutional Neural Points (DM-NPs) for the first surface accessible Surface Color Field design, where we introduce Improved Point Rasterization (IPR) for point cloud based surface query. We implement and experiment with SceneFactory to demonstrate its broad practicability and high flexibility. Its quality also competes or exceeds the tightly-coupled state of the art approaches in all tasks. We contribute the code to the community (https://jarrome.github.io/).
NSLF-OL: Online Learning of Neural Surface Light Fields alongside Real-time Incremental 3D Reconstruction
Apr 29, 2023



Immersive novel view generation is an important technology in the field of graphics and has recently also received attention for operator-based human-robot interaction. However, the involved training is time-consuming, and thus the current test scope is majorly on object capturing. This limits the usage of related models in the robotics community for 3D reconstruction since robots (1) usually only capture a very small range of view directions to surfaces that cause arbitrary predictions on unseen, novel direction, (2) requires real-time algorithms, and (3) work with growing scenes, e.g., in robotic exploration. The paper proposes a novel Neural Surface Light Fields model that copes with the small range of view directions while producing a good result in unseen directions. Exploiting recent encoding techniques, the training of our model is highly efficient. In addition, we design Multiple Asynchronous Neural Agents (MANA), a universal framework to learn each small region in parallel for large-scale growing scenes. Our model learns online the Neural Surface Light Fields (NSLF) aside from real-time 3D reconstruction with a sequential data stream as the shared input. In addition to online training, our model also provides real-time rendering after completing the data stream for visualization. We implement experiments using well-known RGBD indoor datasets, showing the high flexibility to embed our model into real-time 3D reconstruction and demonstrating high-fidelity view synthesis for these scenes. The code is available on github.
Uni-Fusion: Universal Continuous Mapping
Mar 22, 2023We introduce Uni-Fusion, an universal continuous mapping framework for surfaces, surface properties (color, infrared, etc.) and more (latent features in CLIP embedding space, etc.). We propose the first Universal Implicit Encoding model that supports encoding of both geometry and various types of properties (RGB, infrared, feature and etc.) without the need for any training. Based on that, our framework divides the point cloud into regular grid voxels and produces a latent feature in each voxel to form a Latent Implicit Map (LIM) for geometries and arbitrary properties. Then, by fusing a Local LIM of new frame to Global LIM, an incremental reconstruction is approached. Encoded with corresponding types of data, our Latent Implicit Map is capable to generate continuous surfaces, surface properties fields, surface feature fields and any other possible options. To demonstrate the capabilities of our model, we implement three applications: (1) incremental reconstruction for surfaces and color (2) 2D-to-3D fabricated properties transfers (3) open-vocabulary scene understanding by producing a text CLIP feature field on surfaces. We evaluate Uni-Fusion by comparing in corresponding applications, from which, Uni-Fusion shows high flexibility to various of application while performing best or competitive. The project page of Uni-Fusion is available at https://jarrome.github.io/Uni-Fusion/
An Algorithm for the SE-Transformation on Neural Implicit Maps for Remapping Functions
Jun 17, 2022

Implicit representations are widely used for object reconstruction due to their efficiency and flexibility. In 2021, a novel structure named neural implicit map has been invented for incremental reconstruction. A neural implicit map alleviates the problem of inefficient memory cost of previous online 3D dense reconstruction while producing better quality. % However, the neural implicit map suffers the limitation that it does not support remapping as the frames of scans are encoded into a deep prior after generating the neural implicit map. This means, that neither this generation process is invertible, nor a deep prior is transformable. The non-remappable property makes it not possible to apply loop-closure techniques. % We present a neural implicit map based transformation algorithm to fill this gap. As our neural implicit map is transformable, our model supports remapping for this special map of latent features. % Experiments show that our remapping module is capable to well-transform neural implicit maps to new poses. Embedded into a SLAM framework, our mapping model is able to tackle the remapping of loop closures and demonstrates high-quality surface reconstruction. % Our implementation is available at github\footnote{\url{https://github.com/Jarrome/IMT_Mapping}} for the research community.
Indirect Point Cloud Registration: Aligning Distance Fields using a Pseudo Third Point Ses
May 31, 2022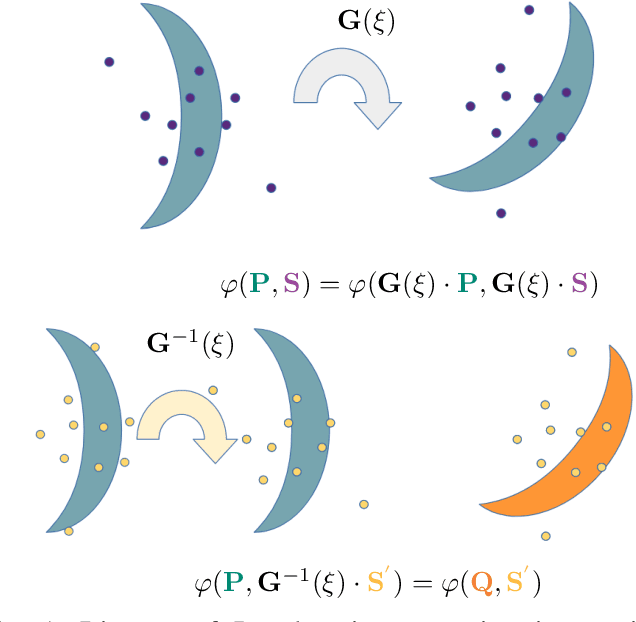
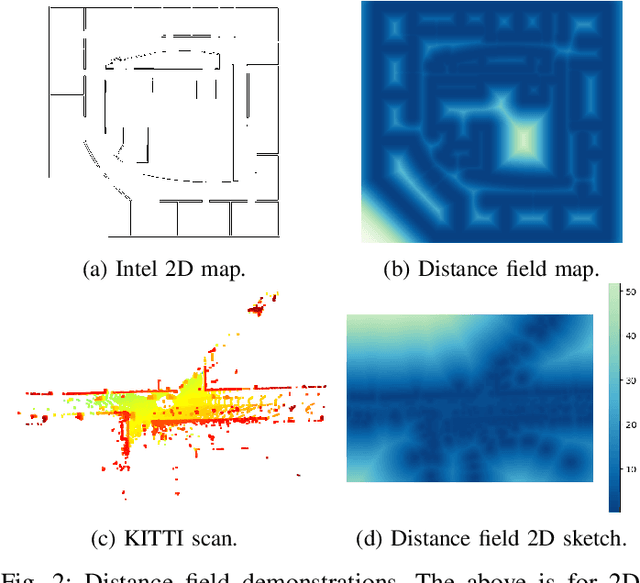
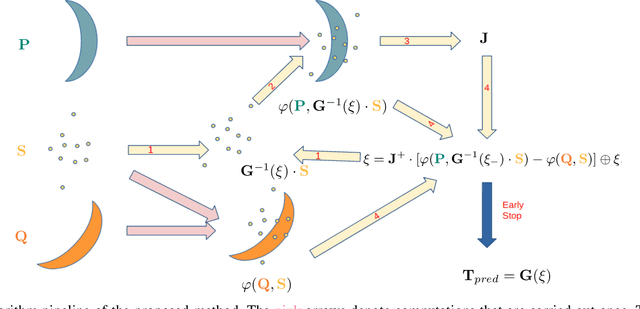
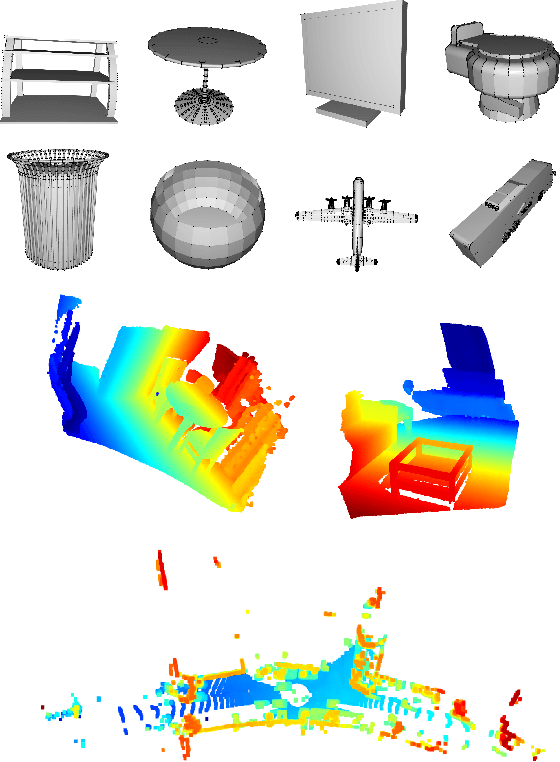
In recent years, implicit functions have drawn attention in the field of 3D reconstruction and have successfully been applied with Deep Learning. However, for incremental reconstruction, implicit function-based registrations have been rarely explored. Inspired by the high precision of deep learning global feature registration, we propose to combine this with distance fields. We generalize the algorithm to a non-Deep Learning setting while retaining the accuracy. Our algorithm is more accurate than conventional models while, without any training, it achieves a competitive performance and faster speed, compared to Deep Learning-based registration models. The implementation is available on github for the research community.
Improved Visual-Inertial Localization for Low-cost Rescue Robots
Nov 17, 2020
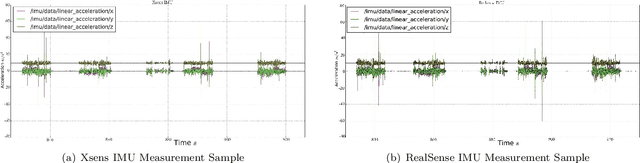
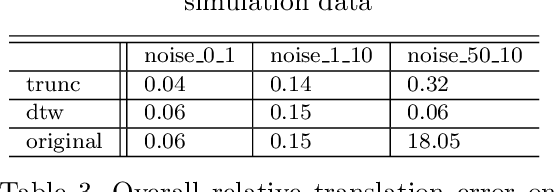
This paper improves visual-inertial systems to boost the localization accuracy for low-cost rescue robots. When robots traverse on rugged terrain, the performance of pose estimation suffers from big noise on the measurements of the inertial sensors due to ground contact forces, especially for low-cost sensors. Therefore, we propose \textit{Threshold}-based and \textit{Dynamic Time Warping}-based methods to detect abnormal measurements and mitigate such faults. The two methods are embedded into the popular VINS-Mono system to evaluate their performance. Experiments are performed on simulation and real robot data, which show that both methods increase the pose estimation accuracy. Moreover, the \textit{Threshold}-based method performs better when the noise is small and the \textit{Dynamic Time Warping}-based one shows greater potential on large noise.
Self-supervised Point Set Local Descriptors for Point Cloud Registration
Mar 11, 2020
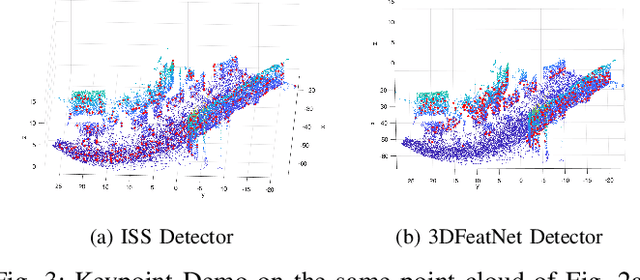
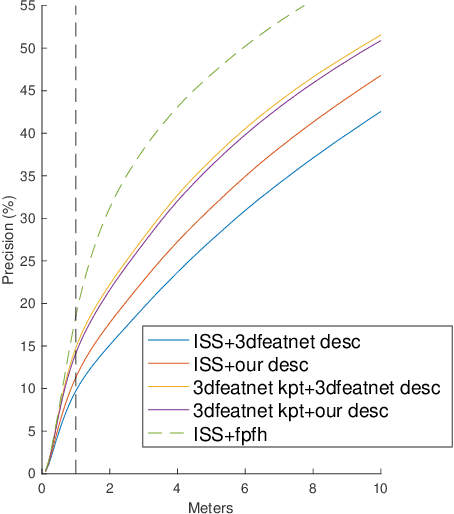
In this work, we propose to learn local descriptors for point clouds in a self-supervised manner. In each iteration of the training, the input of the network is merely one unlabeled point cloud. On top of our previous work, that directly solves the transformation between two point sets in one step without correspondences, the proposed method is able to train from one point cloud, by supervising its self-rotation, that we randomly generate. The whole training requires no manual annotation. In several experiments we evaluate the performance of our method on various datasets and compare to other state of the art algorithms. The results show, that our self-supervised learned descriptor achieves equivalent or even better performance than the supervised learned model, while being easier to train and not requiring labeled data.
Non-iterative One-step Solution for Point Set Registration Problem on Pose Estimation without Correspondence
Mar 01, 2020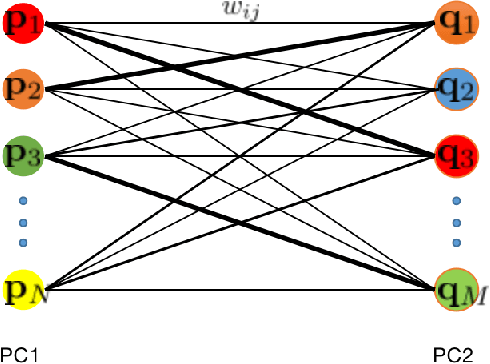
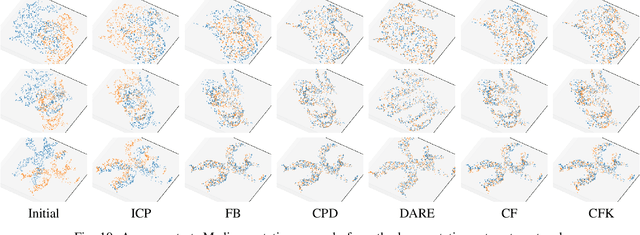
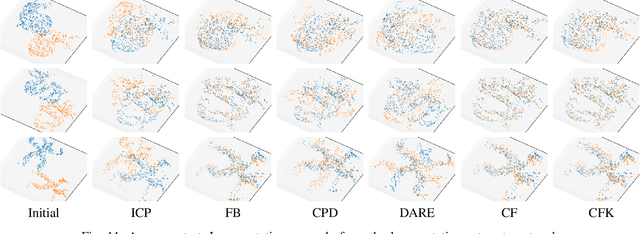
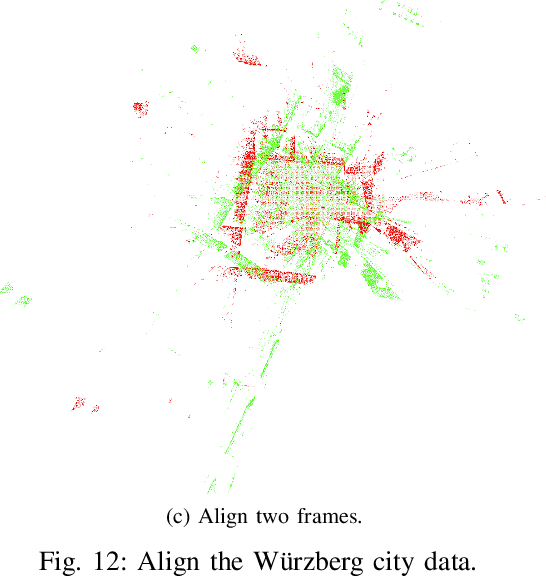
In this work, we propose to directly find the one-step solution for the point set registration problem without correspondences. Inspired by the Kernel Correlation method, we consider the full connected objective function between two point sets, thus avoiding the computation of correspondences. By utilizing least square minimization the transformed objective function is directly solved with existing well-known closed-form solutions, e.g., singular value decomposition, that is usually used for given correspondences. However, using equal weights of costs for each connection will degenerate the solution due to the large influence of distant pairs. Thus, we additionally set a scale on each term to avoid the high cost on non-important pairs. As in feature-based registration methods, the similarity between descriptors of points determines the scaling weight. Given the weights we yield a one step solution. As the runtime is in $\mathcal O (n^2)$, we also propose a variant with keypoints that strongly reduce the cost. The experiments show, that our proposed method gives a one-step solution without an initial guess. Our method exhibits competitive outliers robustness, accuracy compared with various methods. And it is more stable to large rotation. In addition, though feature based algorithms are more sensitive to noise, Our method still provide better result compared with the feature match initialized ICP.
Area Graph: Generation of Topological Maps using the Voronoi Diagram
Oct 01, 2019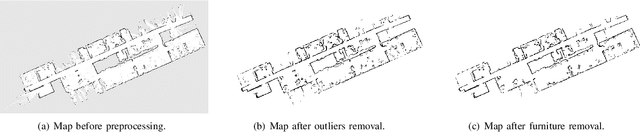
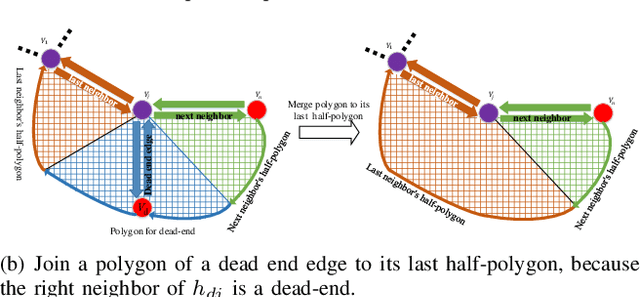
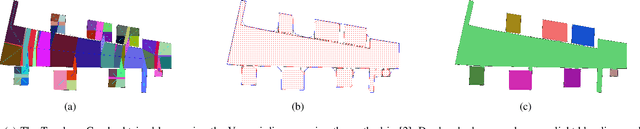
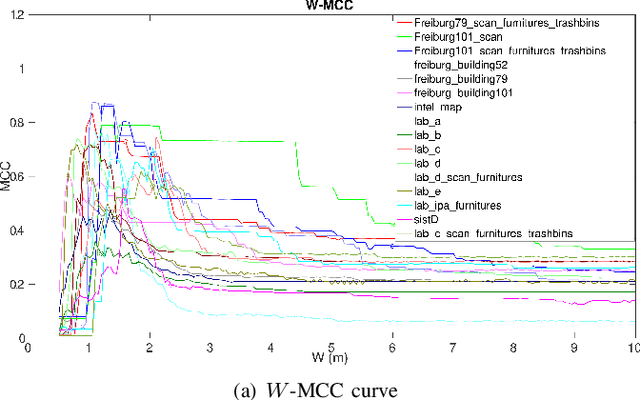
Representing a scanned map of the real environment as a topological structure is an important research topic in robotics. Since topological representations of maps save a huge amount of map storage space and online computing time, they are widely used in fields such as path planning, map matching, and semantic mapping. We use a topological map representation, the Area Graph, in which the vertices represent areas and edges represent passages. The Area Graph is developed from a pruned Voronoi Graph, the Topology Graph. We also employ a simple room detection algorithm to compensate the fact that the Voronoi Graph gets unstable in open areas. We claim that our area segmentation method is superior to state-of-the-art approaches in complex indoor environments and support this claim with a number of experiments.