 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUPS: A Simulated Underground Parking Scenario Dataset for Autonomous Driving
Paper and Code

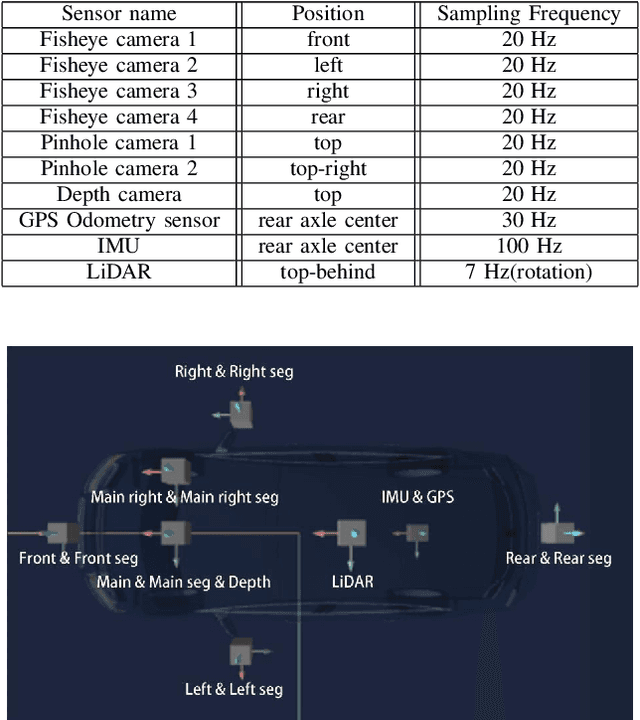

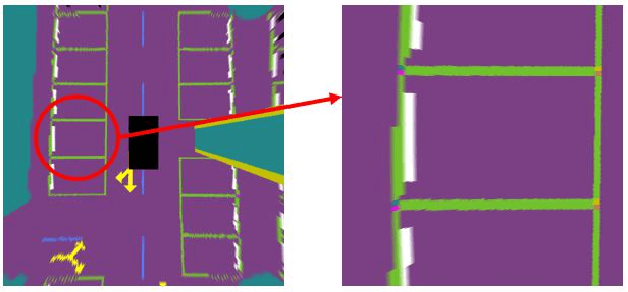
Automatic underground parking has attracted considerable attention as the scope of autonomous driving expands. The auto-vehicle is supposed to obtain the environmental information, track its location, and build a reliable map of the scenario. Mainstream solutions consist of well-trained neural networks and simultaneous localization and mapping (SLAM) methods, which need numerous carefully labeled images and multiple sensor estimations. However, there is a lack of underground parking scenario datasets with multiple sensors and well-labeled images that support both SLAM tasks and perception tasks, such as semantic segmentation and parking slot detection. In this paper, we present SUPS, a simulated dataset for underground automatic parking, which supports multiple tasks with multiple sensors and multiple semantic labels aligned with successive images according to timestamps. We intend to cover the defect of existing datasets with the variability of environments and the diversity and accessibility of sensors in the virtual scene. Specifically, the dataset records frames from four surrounding fisheye cameras, two forward pinhole cameras, a depth camera, and data from LiDAR, inertial measurement unit (IMU), GNSS. Pixel-level semantic labels are provided for objects, especially ground signs such as arrows, parking lines, lanes, and speed bumps. Perception, 3D reconstruction, depth estimation, and SLAM, and other relative tasks are supported by our dataset. We also evaluate the state-of-the-art SLAM algorithms and perception models on our dataset. Finally, we open source our virtual 3D scene built based on Unity Engine and release our dataset at https://github.com/jarvishou829/SUPS.