 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReStyle-TTS: Relative and Continuous Style Control for Zero-Shot Speech Synthesis
Jan 07, 2026Zero-shot text-to-speech models can clone a speaker's timbre from a short reference audio, but they also strongly inherit the speaking style present in the reference. As a result, synthesizing speech with a desired style often requires carefully selecting reference audio, which is impractical when only limited or mismatched references are available. While recent controllable TTS methods attempt to address this issue, they typically rely on absolute style targets and discrete textual prompts, and therefore do not support continuous and reference-relative style control. We propose ReStyle-TTS, a framework that enables continuous and reference-relative style control in zero-shot TTS. Our key insight is that effective style control requires first reducing the model's implicit dependence on reference style before introducing explicit control mechanisms. To this end, we introduce Decoupled Classifier-Free Guidance (DCFG), which independently controls text and reference guidance, reducing reliance on reference style while preserving text fidelity. On top of this, we apply style-specific LoRAs together with Orthogonal LoRA Fusion to enable continuous and disentangled multi-attribute control, and introduce a Timbre Consistency Optimization module to mitigate timbre drift caused by weakened reference guidance. Experiments show that ReStyle-TTS enables user-friendly, continuous, and relative control over pitch, energy, and multiple emotions while maintaining intelligibility and speaker timbre, and performs robustly in challenging mismatched reference-target style scenarios.
UniVoice: Unifying Autoregressive ASR and Flow-Matching based TTS with Large Language Models
Oct 06, 2025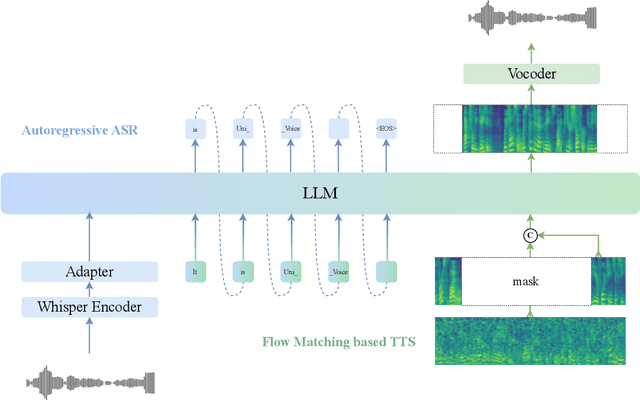
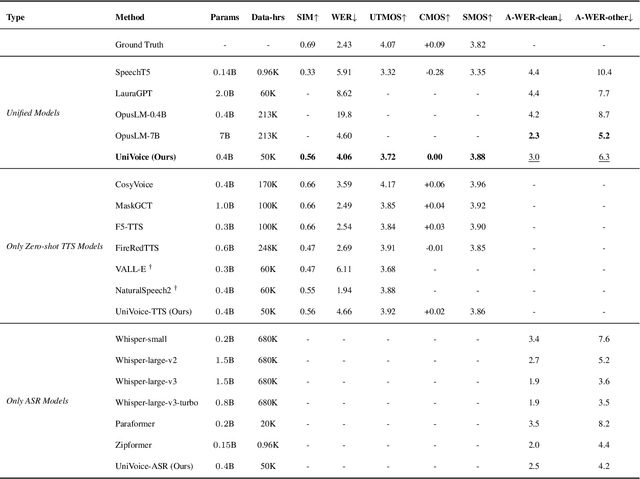
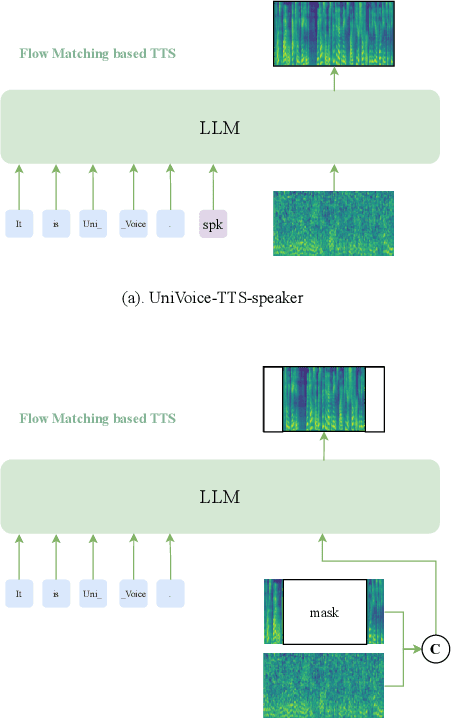

Large language models (LLMs) have demonstrated promising performance in both automatic speech recognition (ASR) and text-to-speech (TTS) systems, gradually becoming the mainstream approach. However, most current approaches address these tasks separately rather than through a unified framework. This work aims to integrate these two tasks into one unified model. Although discrete speech tokenization enables joint modeling, its inherent information loss limits performance in both recognition and generation. In this work, we present UniVoice, a unified LLM framework through continuous representations that seamlessly integrates speech recognition and synthesis within a single model. Our approach combines the strengths of autoregressive modeling for speech recognition with flow matching for high-quality generation. To mitigate the inherent divergence between autoregressive and flow-matching models, we further design a dual attention mechanism, which switches between a causal mask for recognition and a bidirectional attention mask for synthesis. Furthermore, the proposed text-prefix-conditioned speech infilling method enables high-fidelity zero-shot voice cloning. Experimental results demonstrate that our method can achieve or exceed current single-task modeling methods in both ASR and zero-shot TTS tasks. This work explores new possibilities for end-to-end speech understanding and generation.
Discl-VC: Disentangled Discrete Tokens and In-Context Learning for Controllable Zero-Shot Voice Conversion
May 30, 2025Currently, zero-shot voice conversion systems are capable of synthesizing the voice of unseen speakers. However, most existing approaches struggle to accurately replicate the speaking style of the source speaker or mimic the distinctive speaking style of the target speaker, thereby limiting the controllability of voice conversion. In this work, we propose Discl-VC, a novel voice conversion framework that disentangles content and prosody information from self-supervised speech representations and synthesizes the target speaker's voice through in-context learning with a flow matching transformer. To enable precise control over the prosody of generated speech, we introduce a mask generative transformer that predicts discrete prosody tokens in a non-autoregressive manner based on prompts. Experimental results demonstrate the superior performance of Discl-VC in zero-shot voice conversion and its remarkable accuracy in prosody control for synthesized speech.
DS-Codec: Dual-Stage Training with Mirror-to-NonMirror Architecture Switching for Speech Codec
May 30, 2025Neural speech codecs are essential for advancing text-to-speech (TTS) systems. With the recent success of large language models in text generation, developing high-quality speech tokenizers has become increasingly important. This paper introduces DS-Codec, a novel neural speech codec featuring a dual-stage training framework with mirror and non-mirror architectures switching, designed to achieve superior speech reconstruction. We conduct extensive experiments and ablation studies to evaluate the effectiveness of our training strategy and compare the performance of the two architectures. Our results show that the mirrored structure significantly enhances the robustness of the learned codebooks, and the training strategy balances the advantages between mirrored and non-mirrored structures, leading to improved high-fidelity speech reconstruction.
SlimSpeech: Lightweight and Efficient Text-to-Speech with Slim Rectified Flow
Apr 10, 2025Recently, flow matching based speech synthesis has significantly enhanced the quality of synthesized speech while reducing the number of inference steps. In this paper, we introduce SlimSpeech, a lightweight and efficient speech synthesis system based on rectified flow. We have built upon the existing speech synthesis method utilizing the rectified flow model, modifying its structure to reduce parameters and serve as a teacher model. By refining the reflow operation, we directly derive a smaller model with a more straight sampling trajectory from the larger model, while utilizing distillation techniques to further enhance the model performance. Experimental results demonstrate that our proposed method, with significantly reduced model parameters, achieves comparable performance to larger models through one-step sampling.
Zero-Shot Sing Voice Conversion: built upon clustering-based phoneme representations
Sep 12, 2024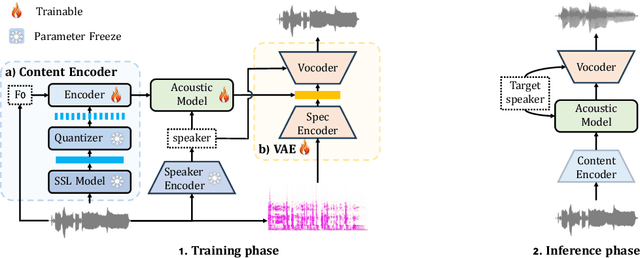
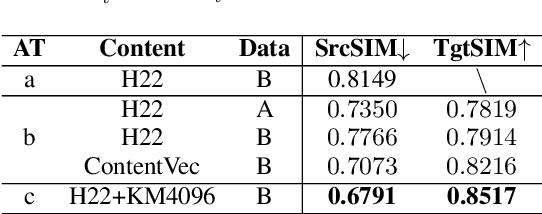

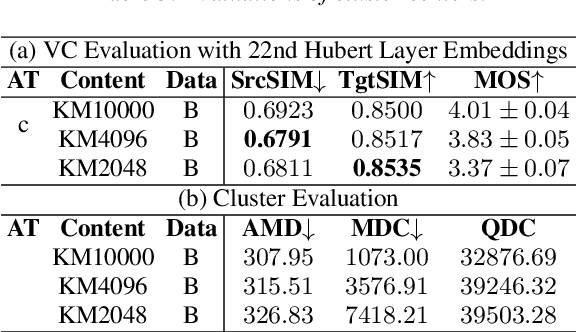
This study presents an innovative Zero-Shot any-to-any Singing Voice Conversion (SVC) method, leveraging a novel clustering-based phoneme representation to effectively separate content, timbre, and singing style. This approach enables precise voice characteristic manipulation. We discovered that datasets with fewer recordings per artist are more susceptible to timbre leakage. Extensive testing on over 10,000 hours of singing and user feedback revealed our model significantly improves sound quality and timbre accuracy, aligning with our objectives and advancing voice conversion technology. Furthermore, this research advances zero-shot SVC and sets the stage for future work on discrete speech representation, emphasizing the preservation of rhyme.
Dynamic Language Group-Based MoE: Enhancing Efficiency and Flexibility for Code-Switching Speech Recognition
Jul 26, 2024



The Mixture of Experts (MoE) approach is ideally suited for tackling multilingual and code-switching (CS) challenges due to its multi-expert architecture. This work introduces the DLG-MoE, which is optimized for bilingual and CS scenarios. Our novel Dynamic Language Group-based MoE layer features a language router with shared weights for explicit language modeling, while independent unsupervised routers within the language group handle attributes beyond language. This structure not only enhances expert extension capabilities but also supports dynamic top-k training, allowing for flexible inference across various top-k values and improving overall performance. The model requires no pre-training and supports streaming recognition, achieving state-of-the-art (SOTA) results with unmatched flexibility compared to other methods. The Code will be released.
LAFMA: A Latent Flow Matching Model for Text-to-Audio Generation
Jun 12, 2024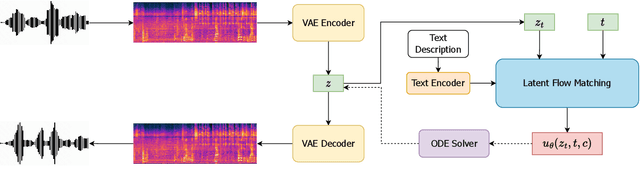
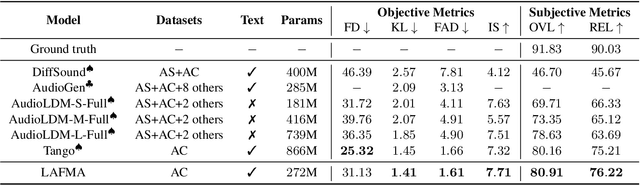
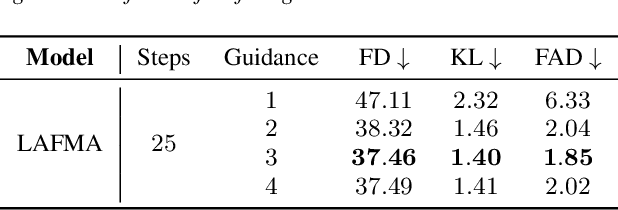
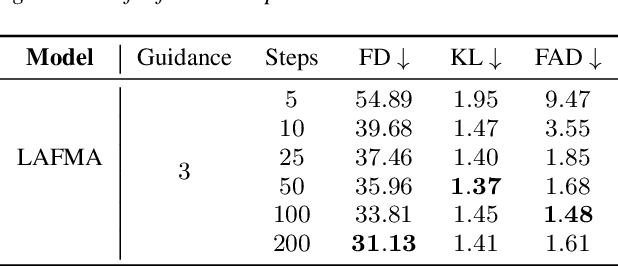
Recently, the application of diffusion models has facilitated the significant development of speech and audio generation. Nevertheless, the quality of samples generated by diffusion models still needs improvement. And the effectiveness of the method is accompanied by the extensive number of sampling steps, leading to an extended synthesis time necessary for generating high-quality audio. Previous Text-to-Audio (TTA) methods mostly used diffusion models in the latent space for audio generation. In this paper, we explore the integration of the Flow Matching (FM) model into the audio latent space for audio generation. The FM is an alternative simulation-free method that trains continuous normalization flows (CNF) based on regressing vector fields. We demonstrate that our model significantly enhances the quality of generated audio samples, achieving better performance than prior models. Moreover, it reduces the number of inference steps to ten steps almost without sacrificing performance.
LOP-Field: Brain-inspired Layout-Object-Position Fields for Robotic Scene Understanding
Jun 11, 2024Spatial cognition empowers animals with remarkably efficient navigation abilities, largely depending on the scene-level understanding of spatial environments. Recently, it has been found that a neural population in the postrhinal cortex of rat brains is more strongly tuned to the spatial layout rather than objects in a scene. Inspired by the representations of spatial layout in local scenes to encode different regions separately, we proposed LOP-Field that realizes the Layout-Object-Position(LOP) association to model the hierarchical representations for robotic scene understanding. Powered by foundation models and implicit scene representation, a neural field is implemented as a scene memory for robots, storing a queryable representation of scenes with position-wise, object-wise, and layout-wise information. To validate the built LOP association, the model is tested to infer region information from 3D positions with quantitative metrics, achieving an average accuracy of more than 88\%. It is also shown that the proposed method using region information can achieve improved object and view localization results with text and RGB input compared to state-of-the-art localization methods.
FastOcc: Accelerating 3D Occupancy Prediction by Fusing the 2D Bird's-Eye View and Perspective View
Mar 05, 2024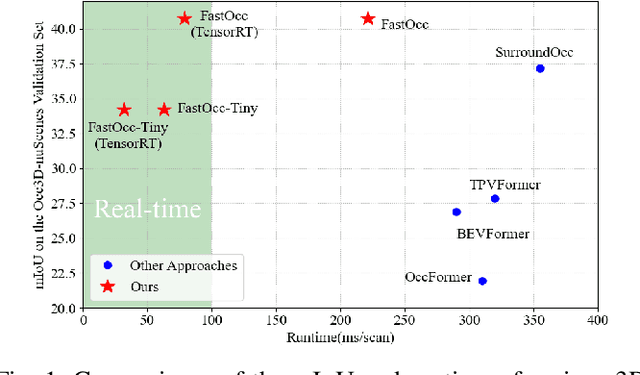
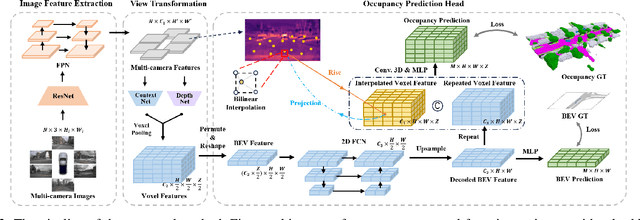
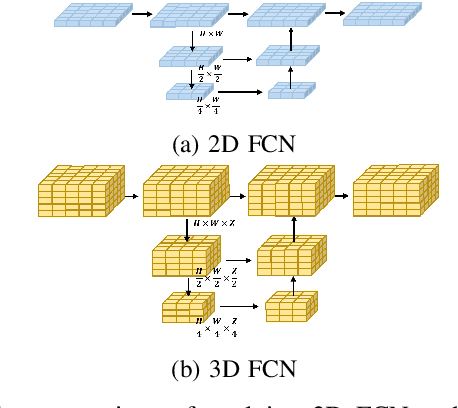
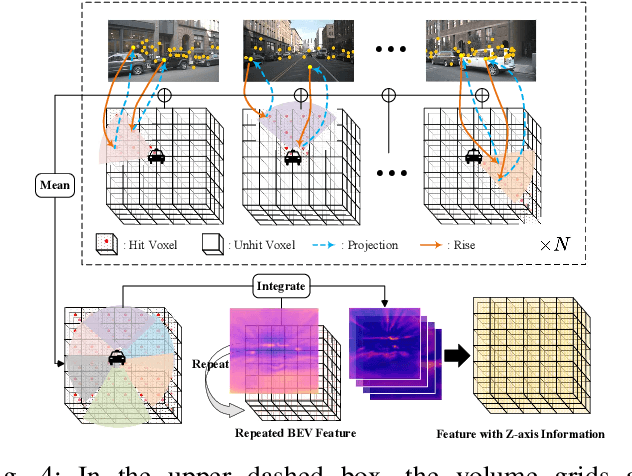
In autonomous driving, 3D occupancy prediction outputs voxel-wise status and semantic labels for more comprehensive understandings of 3D scenes compared with traditional perception tasks, such as 3D object detection and bird's-eye view (BEV) semantic segmentation. Recent researchers have extensively explored various aspects of this task, including view transformation techniques, ground-truth label generation, and elaborate network design, aiming to achieve superior performance. However, the inference speed, crucial for running on an autonomous vehicle, is neglected. To this end, a new method, dubbed FastOcc, is proposed. By carefully analyzing the network effect and latency from four parts, including the input image resolution, image backbone, view transformation, and occupancy prediction head, it is found that the occupancy prediction head holds considerable potential for accelerating the model while keeping its accuracy. Targeted at improving this component, the time-consuming 3D convolution network is replaced with a novel residual-like architecture, where features are mainly digested by a lightweight 2D BEV convolution network and compensated by integrating the 3D voxel features interpolated from the original image features. Experiments on the Occ3D-nuScenes benchmark demonstrate that our FastOcc achieves state-of-the-art results with a fast inference speed.