 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Age and Identity with a Mutual Information Minimization Approach for Cross-Age Speaker Verification
Sep 24, 2024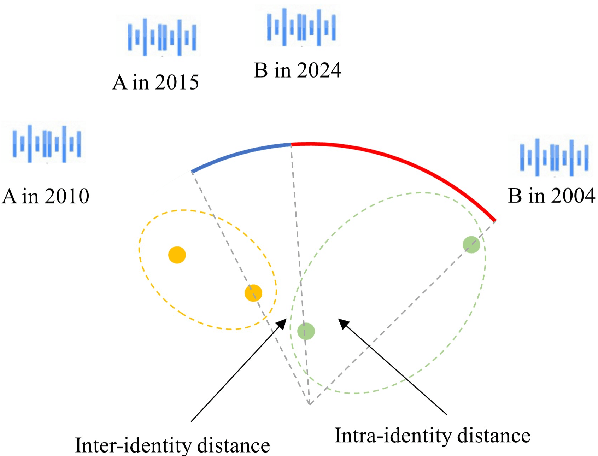
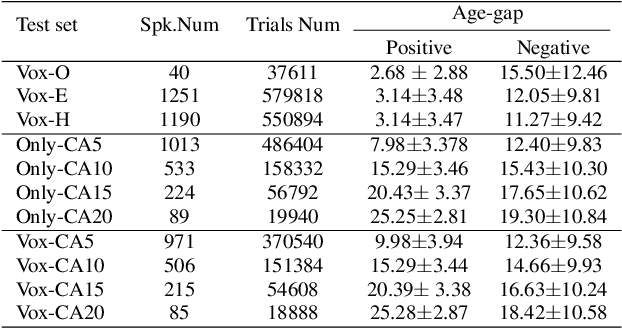
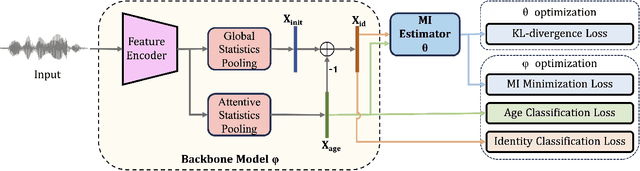

There has been an increasing research interest in cross-age speaker verification~(CASV). However, existing speaker verification systems perform poorly in CASV due to the great individual differences in voice caused by aging. In this paper, we propose a disentangled representation learning framework for CASV based on mutual information~(MI) minimization. In our method, a backbone model is trained to disentangle the identity- and age-related embeddings from speaker information, and an MI estimator is trained to minimize the correlation between age- and identity-related embeddings via MI minimization, resulting in age-invariant speaker embeddings. Furthermore, by using the age gaps between positive and negative samples, we propose an aging-aware MI minimization loss function that allows the backbone model to focus more on the vocal changes with large age gaps. Experimental results show that the proposed method outperforms other methods on multiple Cross-Age test sets of Vox-CA.
Dynamic Language Group-Based MoE: Enhancing Efficiency and Flexibility for Code-Switching Speech Recognition
Jul 26, 2024



The Mixture of Experts (MoE) approach is ideally suited for tackling multilingual and code-switching (CS) challenges due to its multi-expert architecture. This work introduces the DLG-MoE, which is optimized for bilingual and CS scenarios. Our novel Dynamic Language Group-based MoE layer features a language router with shared weights for explicit language modeling, while independent unsupervised routers within the language group handle attributes beyond language. This structure not only enhances expert extension capabilities but also supports dynamic top-k training, allowing for flexible inference across various top-k values and improving overall performance. The model requires no pre-training and supports streaming recognition, achieving state-of-the-art (SOTA) results with unmatched flexibility compared to other methods. The Code will be released.
Improving Gated Recurrent Unit Based Acoustic Modeling with Batch Normalization and Enlarged Context
Nov 26, 2018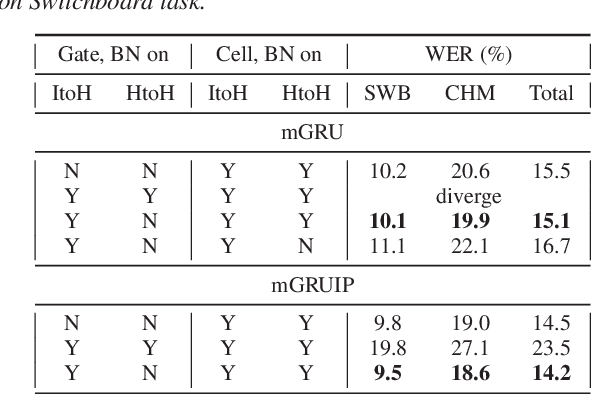
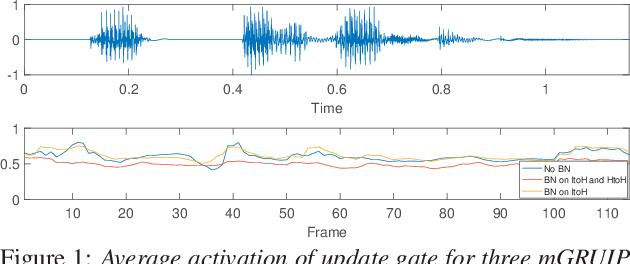

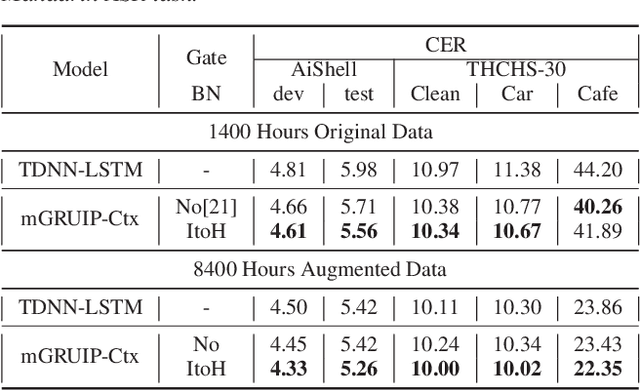
The use of future contextual information is typically shown to be helpful for acoustic modeling. Recently, we proposed a RNN model called minimal gated recurrent unit with input projection (mGRUIP), in which a context module namely temporal convolution, is specifically designed to model the future context. This model, mGRUIP with context module (mGRUIP-Ctx), has been shown to be able of utilizing the future context effectively, meanwhile with quite low model latency and computation cost. In this paper, we continue to improve mGRUIP-Ctx with two revisions: applying BN methods and enlarging model context. Experimental results on two Mandarin ASR tasks (8400 hours and 60K hours) show that, the revised mGRUIP-Ctx outperform LSTM with a large margin (11% to 38%). It even performs slightly better than a superior BLSTM on the 8400h task, with 33M less parameters and just 290ms model latency.