 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Gated Recurrent Unit Based Acoustic Modeling with Batch Normalization and Enlarged Context
Paper and Code
Nov 26, 2018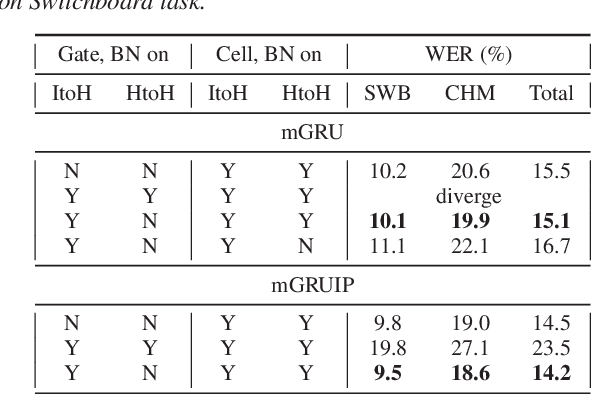
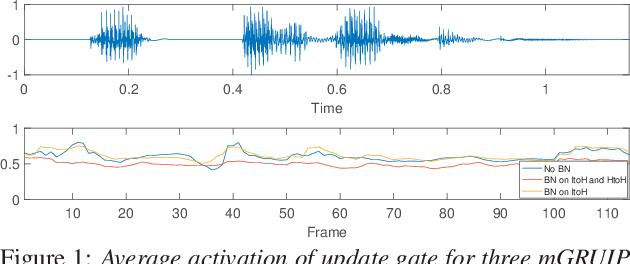

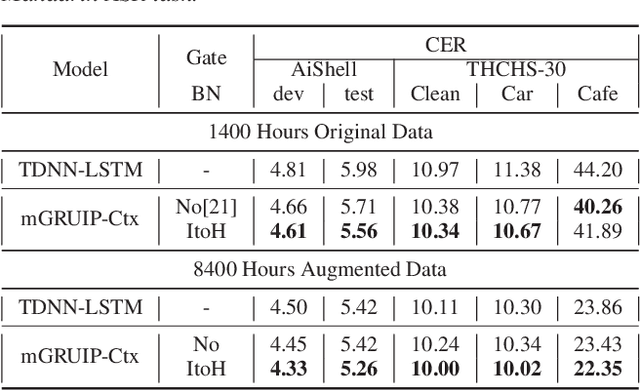
The use of future contextual information is typically shown to be helpful for acoustic modeling. Recently, we proposed a RNN model called minimal gated recurrent unit with input projection (mGRUIP), in which a context module namely temporal convolution, is specifically designed to model the future context. This model, mGRUIP with context module (mGRUIP-Ctx), has been shown to be able of utilizing the future context effectively, meanwhile with quite low model latency and computation cost. In this paper, we continue to improve mGRUIP-Ctx with two revisions: applying BN methods and enlarging model context. Experimental results on two Mandarin ASR tasks (8400 hours and 60K hours) show that, the revised mGRUIP-Ctx outperform LSTM with a large margin (11% to 38%). It even performs slightly better than a superior BLSTM on the 8400h task, with 33M less parameters and just 290ms model latency.