 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Sing Voice Conversion: built upon clustering-based phoneme representations
Paper and Code
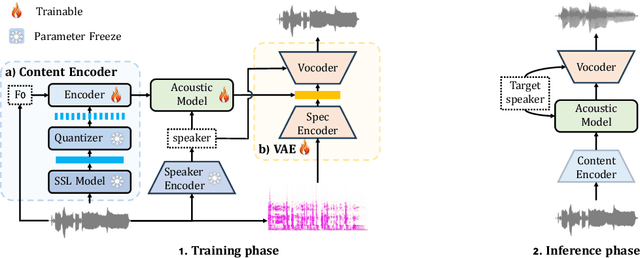
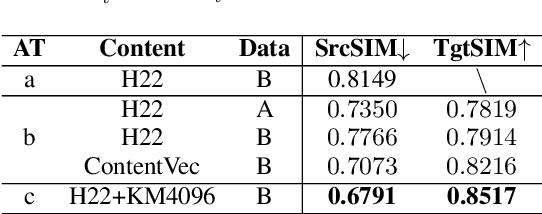

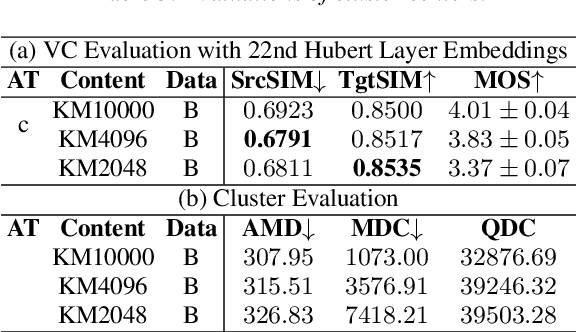
This study presents an innovative Zero-Shot any-to-any Singing Voice Conversion (SVC) method, leveraging a novel clustering-based phoneme representation to effectively separate content, timbre, and singing style. This approach enables precise voice characteristic manipulation. We discovered that datasets with fewer recordings per artist are more susceptible to timbre leakage. Extensive testing on over 10,000 hours of singing and user feedback revealed our model significantly improves sound quality and timbre accuracy, aligning with our objectives and advancing voice conversion technology. Furthermore, this research advances zero-shot SVC and sets the stage for future work on discrete speech representation, emphasizing the preservation of rhyme.