 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniVoice: Unifying Autoregressive ASR and Flow-Matching based TTS with Large Language Models
Oct 06, 2025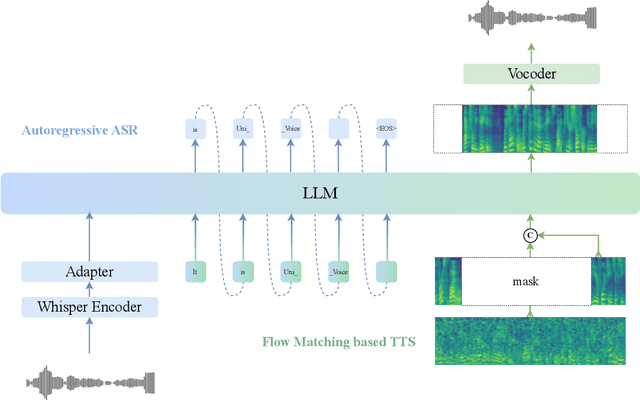
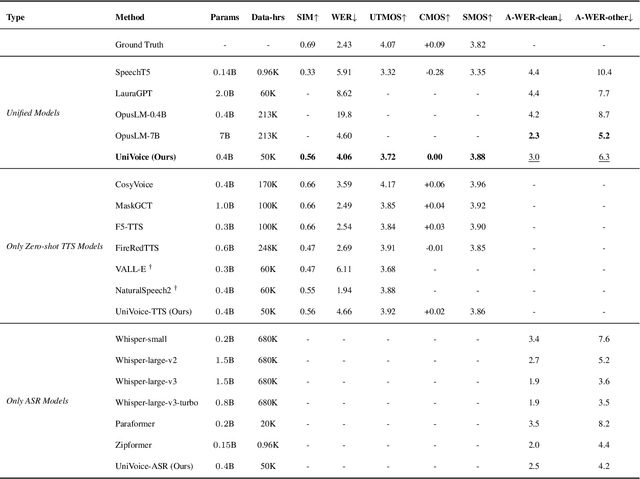
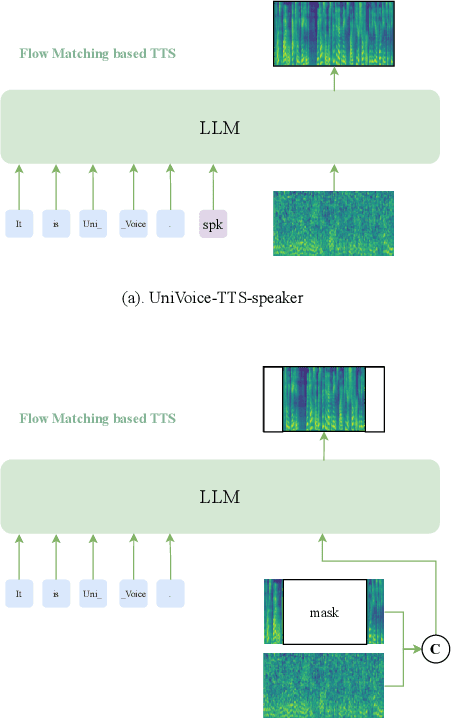

Large language models (LLMs) have demonstrated promising performance in both automatic speech recognition (ASR) and text-to-speech (TTS) systems, gradually becoming the mainstream approach. However, most current approaches address these tasks separately rather than through a unified framework. This work aims to integrate these two tasks into one unified model. Although discrete speech tokenization enables joint modeling, its inherent information loss limits performance in both recognition and generation. In this work, we present UniVoice, a unified LLM framework through continuous representations that seamlessly integrates speech recognition and synthesis within a single model. Our approach combines the strengths of autoregressive modeling for speech recognition with flow matching for high-quality generation. To mitigate the inherent divergence between autoregressive and flow-matching models, we further design a dual attention mechanism, which switches between a causal mask for recognition and a bidirectional attention mask for synthesis. Furthermore, the proposed text-prefix-conditioned speech infilling method enables high-fidelity zero-shot voice cloning. Experimental results demonstrate that our method can achieve or exceed current single-task modeling methods in both ASR and zero-shot TTS tasks. This work explores new possibilities for end-to-end speech understanding and generation.
DS-Codec: Dual-Stage Training with Mirror-to-NonMirror Architecture Switching for Speech Codec
May 30, 2025Neural speech codecs are essential for advancing text-to-speech (TTS) systems. With the recent success of large language models in text generation, developing high-quality speech tokenizers has become increasingly important. This paper introduces DS-Codec, a novel neural speech codec featuring a dual-stage training framework with mirror and non-mirror architectures switching, designed to achieve superior speech reconstruction. We conduct extensive experiments and ablation studies to evaluate the effectiveness of our training strategy and compare the performance of the two architectures. Our results show that the mirrored structure significantly enhances the robustness of the learned codebooks, and the training strategy balances the advantages between mirrored and non-mirrored structures, leading to improved high-fidelity speech reconstruction.
Discl-VC: Disentangled Discrete Tokens and In-Context Learning for Controllable Zero-Shot Voice Conversion
May 30, 2025Currently, zero-shot voice conversion systems are capable of synthesizing the voice of unseen speakers. However, most existing approaches struggle to accurately replicate the speaking style of the source speaker or mimic the distinctive speaking style of the target speaker, thereby limiting the controllability of voice conversion. In this work, we propose Discl-VC, a novel voice conversion framework that disentangles content and prosody information from self-supervised speech representations and synthesizes the target speaker's voice through in-context learning with a flow matching transformer. To enable precise control over the prosody of generated speech, we introduce a mask generative transformer that predicts discrete prosody tokens in a non-autoregressive manner based on prompts. Experimental results demonstrate the superior performance of Discl-VC in zero-shot voice conversion and its remarkable accuracy in prosody control for synthesized speech.
PEEB: Part-based Image Classifiers with an Explainable and Editable Language Bottleneck
Mar 08, 2024



CLIP-based classifiers rely on the prompt containing a {class name} that is known to the text encoder. That is, CLIP performs poorly on new classes or the classes whose names rarely appear on the Internet (e.g., scientific names of birds). For fine-grained classification, we propose PEEB - an explainable and editable classifier to (1) express the class name into a set of pre-defined text descriptors that describe the visual parts of that class; and (2) match the embeddings of the detected parts to their textual descriptors in each class to compute a logit score for classification. In a zero-shot setting where the class names are unknown, PEEB outperforms CLIP by a large margin (~10x in accuracy). Compared to part-based classifiers, PEEB is not only the state-of-the-art on the supervised-learning setting (88.80% accuracy) but also the first to enable users to edit the class definitions to form a new classifier without retraining. Compared to concept bottleneck models, PEEB is also the state-of-the-art in both zero-shot and supervised learning settings.
How explainable are adversarially-robust CNNs?
May 25, 2022
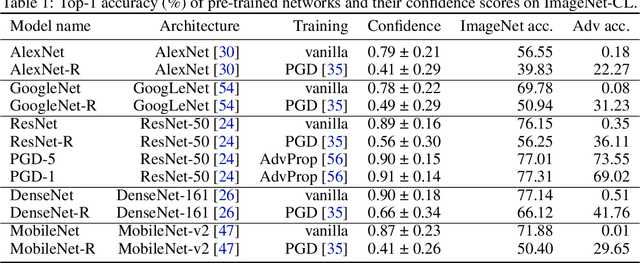
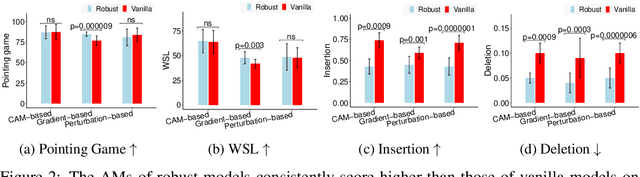

Three important criteria of existing convolutional neural networks (CNNs) are (1) test-set accuracy; (2) out-of-distribution accuracy; and (3) explainability. While these criteria have been studied independently, their relationship is unknown. For example, do CNNs that have a stronger out-of-distribution performance have also stronger explainability? Furthermore, most prior feature-importance studies only evaluate methods on 2-3 common vanilla ImageNet-trained CNNs, leaving it unknown how these methods generalize to CNNs of other architectures and training algorithms. Here, we perform the first, large-scale evaluation of the relations of the three criteria using 9 feature-importance methods and 12 ImageNet-trained CNNs that are of 3 training algorithms and 5 CNN architectures. We find several important insights and recommendations for ML practitioners. First, adversarially robust CNNs have a higher explainability score on gradient-based attribution methods (but not CAM-based or perturbation-based methods). Second, AdvProp models, despite being highly accurate more than both vanilla and robust models alone, are not superior in explainability. Third, among 9 feature attribution methods tested, GradCAM and RISE are consistently the best methods. Fourth, Insertion and Deletion are biased towards vanilla and robust models respectively, due to their strong correlation with the confidence score distributions of a CNN. Fifth, we did not find a single CNN to be the best in all three criteria, which interestingly suggests that CNNs are harder to interpret as they become more accurate.
Intriguing generalization and simplicity of adversarially trained neural networks
Jun 16, 2020


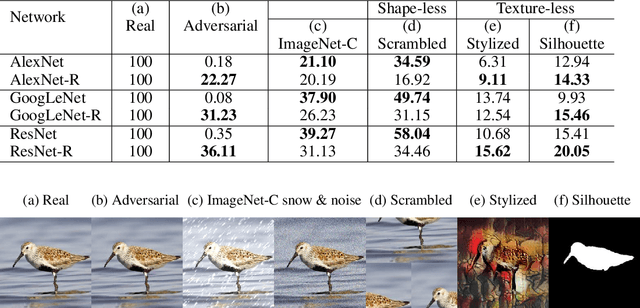
Adversarial training has been the topic of dozens of studies and a leading method for defending against adversarial attacks. Yet, it remains unknown (a) how adversarially-trained classifiers (a.k.a "robust" classifiers) generalize to new types of out-of-distribution examples; and (b) what hidden representations were learned by robust networks. In this paper, we perform a thorough, systematic study to answer these two questions on AlexNet, GoogLeNet, and ResNet-50 trained on ImageNet. While robust models often perform on-par or worse than standard models on unseen distorted, texture-preserving images (e.g. blurred), they are consistently more accurate on texture-less images (i.e. silhouettes and stylized). That is, robust models rely heavily on shapes, in stark contrast to the strong texture bias in standard ImageNet classifiers (Geirhos et al. 2018). Remarkably, adversarial training causes three significant shifts in the functions of hidden neurons. That is, each convolutional neuron often changes to (1) detect pixel-wise smoother patterns; (2) detect more lower-level features i.e. textures and colors (instead of objects); and (3) be simpler in terms of complexity i.e. detecting more limited sets of concepts.
Neurons Activation Visualization and Information Theoretic Analysis
May 14, 2019


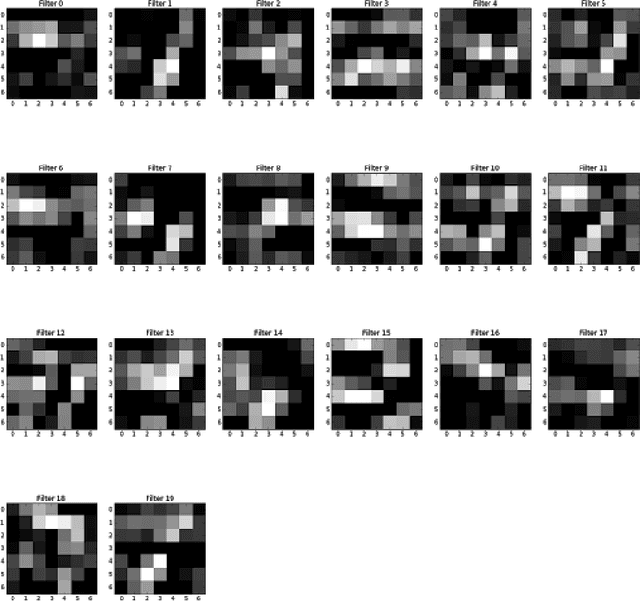
Understanding the inner working mechanism of deep neural networks (DNNs) is essential and important for researchers to design and improve the performance of DNNs. In this work, the entropy analysis is leveraged to study the neurons activation behavior of the fully connected layers of DNNs. The entropy of the activation patterns of each layer can provide a performance metric for the evaluation of the network model accuracy. The study is conducted based on a well trained network model. The activation patterns of shallow and deep layers of the fully connected layers are analyzed by inputting the images of a single class. It is found that for the well trained deep neural networks model, the entropy of the neuron activation pattern is monotonically reduced with the depth of the layers. That is, the neuron activation patterns become more and more stable with the depth of the fully connected layers. The entropy pattern of the fully connected layers can also provide guidelines as to how many fully connected layers are needed to guarantee the accuracy of the model. The study in this work provides a new perspective on the analysis of DNN, which shows some interesting results.