 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntriguing generalization and simplicity of adversarially trained neural networks
Paper and Code



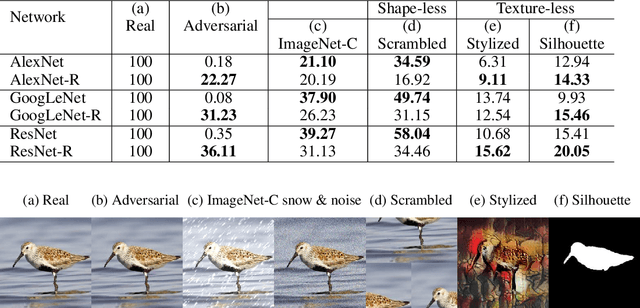
Adversarial training has been the topic of dozens of studies and a leading method for defending against adversarial attacks. Yet, it remains unknown (a) how adversarially-trained classifiers (a.k.a "robust" classifiers) generalize to new types of out-of-distribution examples; and (b) what hidden representations were learned by robust networks. In this paper, we perform a thorough, systematic study to answer these two questions on AlexNet, GoogLeNet, and ResNet-50 trained on ImageNet. While robust models often perform on-par or worse than standard models on unseen distorted, texture-preserving images (e.g. blurred), they are consistently more accurate on texture-less images (i.e. silhouettes and stylized). That is, robust models rely heavily on shapes, in stark contrast to the strong texture bias in standard ImageNet classifiers (Geirhos et al. 2018). Remarkably, adversarial training causes three significant shifts in the functions of hidden neurons. That is, each convolutional neuron often changes to (1) detect pixel-wise smoother patterns; (2) detect more lower-level features i.e. textures and colors (instead of objects); and (3) be simpler in terms of complexity i.e. detecting more limited sets of concepts.