 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Selective Reduction of CT Data for Self-Supervised Pre-Training of Deep Learning Models with Contrastive Learning Improves Downstream Classification Performance
Oct 18, 2024Self-supervised pre-training of deep learning models with contrastive learning is a widely used technique in image analysis. Current findings indicate a strong potential for contrastive pre-training on medical images. However, further research is necessary to incorporate the particular characteristics of these images. We hypothesize that the similarity of medical images hinders the success of contrastive learning in the medical imaging domain. To this end, we investigate different strategies based on deep embedding, information theory, and hashing in order to identify and reduce redundancy in medical pre-training datasets. The effect of these different reduction strategies on contrastive learning is evaluated on two pre-training datasets and several downstream classification tasks. In all of our experiments, dataset reduction leads to a considerable performance gain in downstream tasks, e.g., an AUC score improvement from 0.78 to 0.83 for the COVID CT Classification Grand Challenge, 0.97 to 0.98 for the OrganSMNIST Classification Challenge and 0.73 to 0.83 for a brain hemorrhage classification task. Furthermore, pre-training is up to nine times faster due to the dataset reduction. In conclusion, the proposed approach highlights the importance of dataset quality and provides a transferable approach to improve contrastive pre-training for classification downstream tasks on medical images.
* Published in Computers in Biology and Medicine
Dealing with Small Datasets for Deep Learning in Medical Imaging: An Evaluation of Self-Supervised Pre-Training on CT Scans Comparing Contrastive and Masked Autoencoder Methods for Convolutional Models
Aug 24, 2023Deep learning in medical imaging has the potential to minimize the risk of diagnostic errors, reduce radiologist workload, and accelerate diagnosis. Training such deep learning models requires large and accurate datasets, with annotations for all training samples. However, in the medical imaging domain, annotated datasets for specific tasks are often small due to the high complexity of annotations, limited access, or the rarity of diseases. To address this challenge, deep learning models can be pre-trained on large image datasets without annotations using methods from the field of self-supervised learning. After pre-training, small annotated datasets are sufficient to fine-tune the models for a specific task. The most popular self-supervised pre-training approaches in medical imaging are based on contrastive learning. However, recent studies in natural image processing indicate a strong potential for masked autoencoder approaches. Our work compares state-of-the-art contrastive learning methods with the recently introduced masked autoencoder approach "SparK" for convolutional neural networks (CNNs) on medical images. Therefore we pre-train on a large unannotated CT image dataset and fine-tune on several CT classification tasks. Due to the challenge of obtaining sufficient annotated training data in medical imaging, it is of particular interest to evaluate how the self-supervised pre-training methods perform when fine-tuning on small datasets. By experimenting with gradually reducing the training dataset size for fine-tuning, we find that the reduction has different effects depending on the type of pre-training chosen. The SparK pre-training method is more robust to the training dataset size than the contrastive methods. Based on our results, we propose the SparK pre-training for medical imaging tasks with only small annotated datasets.
Where to look first? Behaviour control for fetch-and-carry missions of service robots
Oct 06, 2015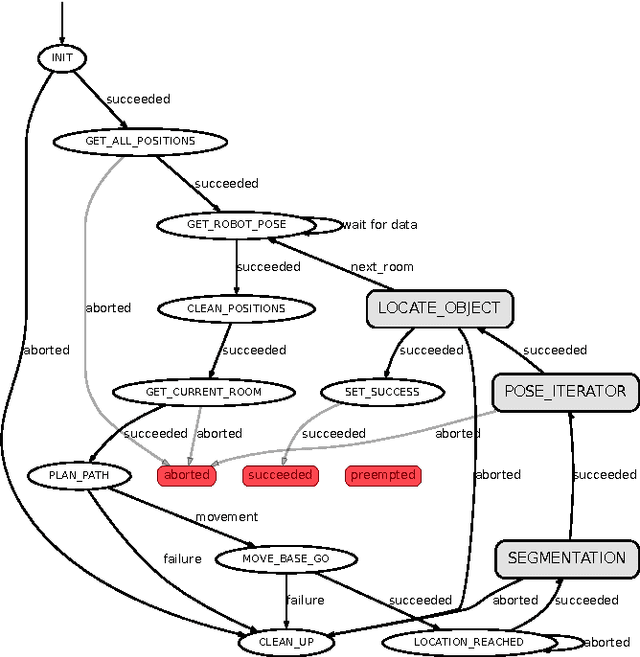


This paper presents the behaviour control of a service robot for intelligent object search in a domestic environment. A major challenge in service robotics is to enable fetch-and-carry missions that are satisfying for the user in terms of efficiency and human-oriented perception. The proposed behaviour controller provides an informed intelligent search based on a semantic segmentation framework for indoor scenes and integrates it with object recognition and grasping. Instead of manually annotating search positions in the environment, the framework automatically suggests likely locations to search for an object based on contextual information, e.g. next to tables and shelves. In a preliminary set of experiments we demonstrate that this behaviour control is as efficient as using manually annotated locations. Moreover, we argue that our approach will reduce the intensity of labour associated with programming fetch-and-carry tasks for service robots and that it will be perceived as more human-oriented.
Find my mug: Efficient object search with a mobile robot using semantic segmentation
Apr 23, 2014
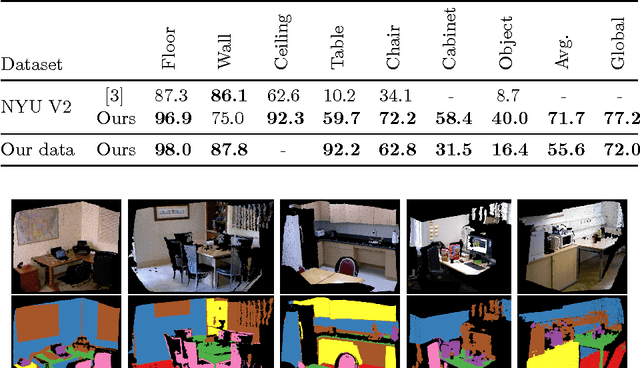
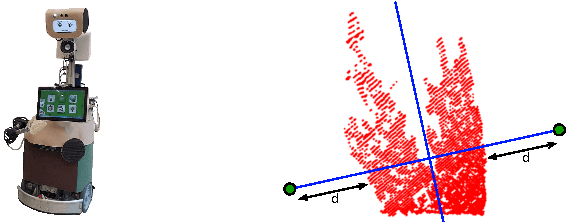
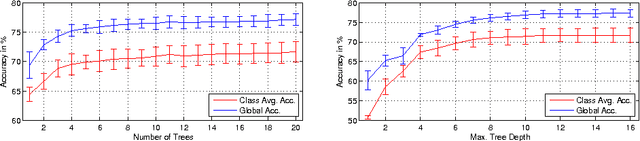
In this paper, we propose an efficient semantic segmentation framework for indoor scenes, tailored to the application on a mobile robot. Semantic segmentation can help robots to gain a reasonable understanding of their environment, but to reach this goal, the algorithms not only need to be accurate, but also fast and robust. Therefore, we developed an optimized 3D point cloud processing framework based on a Randomized Decision Forest, achieving competitive results at sufficiently high frame rates. We evaluate the capabilities of our method on the popular NYU depth dataset and our own data and demonstrate its feasibility by deploying it on a mobile service robot, for which we could optimize an object search procedure using our results.