 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Reason Across Languages?
Jan 10, 2026The real-world information sources are inherently multilingual, which naturally raises a question about whether language models can synthesize information across languages. In this paper, we introduce a simple two-hop question answering setting, where answering a question requires making inferences over two multilingual documents. We find that language models are more sensitive to language variation in answer-span documents than in those providing bridging information, despite the equal importance of both documents for answering a question. Under a step-by-step sub-question evaluation, we further show that in up to 33% of multilingual cases, models fail to infer the bridging information in the first step yet still answer the overall question correctly. This indicates that reasoning in language models, especially in multilingual settings, does not follow a faithful step-by-step decomposition. Subsequently, we show that the absence of reasoning decomposition leads to around 18% composition failure, where both sub-questions are answered correctly but fail for the final two-hop questions. To mitigate this, we propose a simple three-stage SUBQ prompting method to guide the multi-step reasoning with sub-questions, which boosts accuracy from 10.1% to 66.5%.
Unlocking Latent Discourse Translation in LLMs Through Quality-Aware Decoding
Oct 08, 2025Large language models (LLMs) have emerged as strong contenders in machine translation.Yet, they still struggle to adequately handle discourse phenomena, such as pronoun resolution and lexical cohesion at the document level. In this study, we thoroughly investigate the discourse phenomena performance of LLMs in context-aware translation. We demonstrate that discourse knowledge is encoded within LLMs and propose the use of quality-aware decoding (QAD) to effectively extract this knowledge, showcasing its superiority over other decoding approaches through comprehensive analysis. Furthermore, we illustrate that QAD enhances the semantic richness of translations and aligns them more closely with human preferences.
GAMBIT+: A Challenge Set for Evaluating Gender Bias in Machine Translation Quality Estimation Metrics
Oct 08, 2025Gender bias in machine translation (MT) systems has been extensively documented, but bias in automatic quality estimation (QE) metrics remains comparatively underexplored. Existing studies suggest that QE metrics can also exhibit gender bias, yet most analyses are limited by small datasets, narrow occupational coverage, and restricted language variety. To address this gap, we introduce a large-scale challenge set specifically designed to probe the behavior of QE metrics when evaluating translations containing gender-ambiguous occupational terms. Building on the GAMBIT corpus of English texts with gender-ambiguous occupations, we extend coverage to three source languages that are genderless or natural-gendered, and eleven target languages with grammatical gender, resulting in 33 source-target language pairs. Each source text is paired with two target versions differing only in the grammatical gender of the occupational term(s) (masculine vs. feminine), with all dependent grammatical elements adjusted accordingly. An unbiased QE metric should assign equal or near-equal scores to both versions. The dataset's scale, breadth, and fully parallel design, where the same set of texts is aligned across all languages, enables fine-grained bias analysis by occupation and systematic comparisons across languages.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
Analyzing Context Utilization of LLMs in Document-Level Translation
Oct 18, 2024

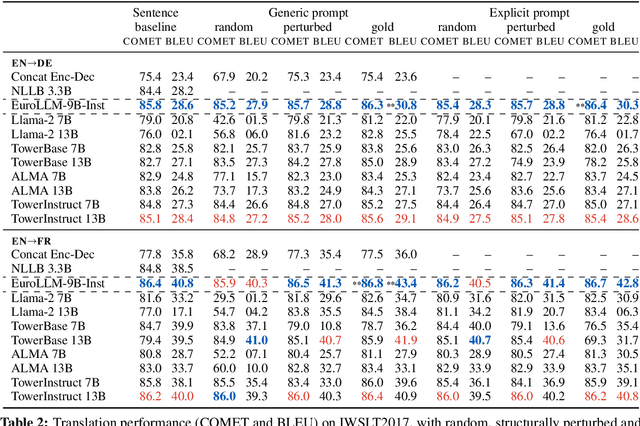
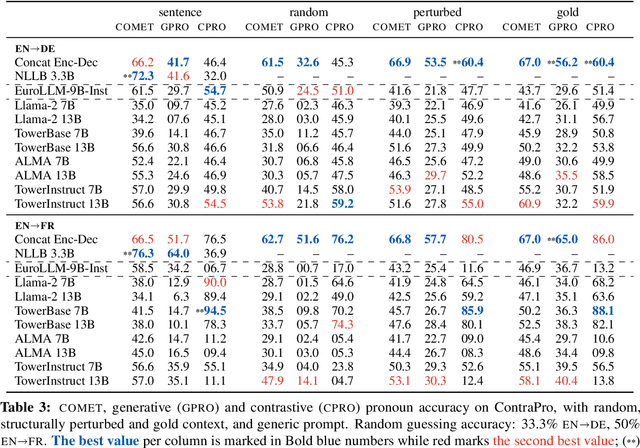
Large language models (LLM) are increasingly strong contenders in machine translation. We study document-level translation, where some words cannot be translated without context from outside the sentence. We investigate the ability of prominent LLMs to utilize context by analyzing models' robustness to perturbed and randomized document context. We find that LLMs' improved document-translation performance is not always reflected in pronoun translation performance. We highlight the need for context-aware finetuning of LLMs with a focus on relevant parts of the context to improve their reliability for document-level translation.
Findings of the WMT 2024 Shared Task on Chat Translation
Oct 15, 2024



This paper presents the findings from the third edition of the Chat Translation Shared Task. As with previous editions, the task involved translating bilingual customer support conversations, specifically focusing on the impact of conversation context in translation quality and evaluation. We also include two new language pairs: English-Korean and English-Dutch, in addition to the set of language pairs from previous editions: English-German, English-French, and English-Brazilian Portuguese. We received 22 primary submissions and 32 contrastive submissions from eight teams, with each language pair having participation from at least three teams. We evaluated the systems comprehensively using both automatic metrics and human judgments via a direct assessment framework. The official rankings for each language pair were determined based on human evaluation scores, considering performance in both translation directions--agent and customer. Our analysis shows that while the systems excelled at translating individual turns, there is room for improvement in overall conversation-level translation quality.
On Measuring Context Utilization in Document-Level MT Systems
Feb 02, 2024

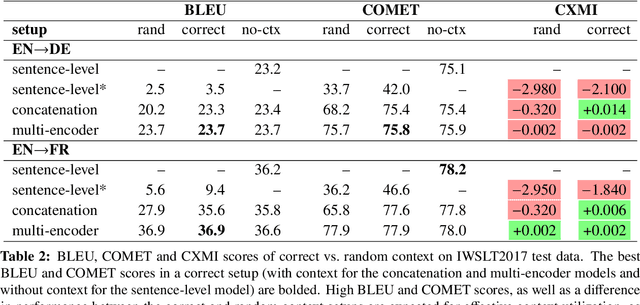

Document-level translation models are usually evaluated using general metrics such as BLEU, which are not informative about the benefits of context. Current work on context-aware evaluation, such as contrastive methods, only measure translation accuracy on words that need context for disambiguation. Such measures cannot reveal whether the translation model uses the correct supporting context. We propose to complement accuracy-based evaluation with measures of context utilization. We find that perturbation-based analysis (comparing models' performance when provided with correct versus random context) is an effective measure of overall context utilization. For a finer-grained phenomenon-specific evaluation, we propose to measure how much the supporting context contributes to handling context-dependent discourse phenomena. We show that automatically-annotated supporting context gives similar conclusions to human-annotated context and can be used as alternative for cases where human annotations are not available. Finally, we highlight the importance of using discourse-rich datasets when assessing context utilization.
Visual Grounding of Inter-lingual Word-Embeddings
Sep 08, 2022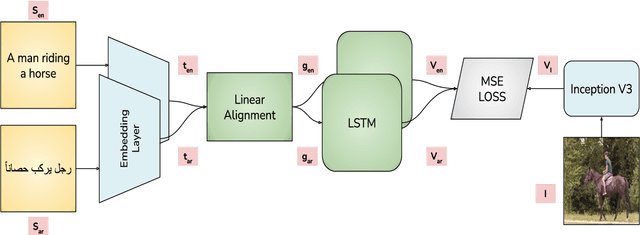
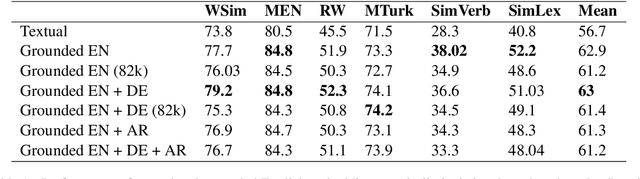
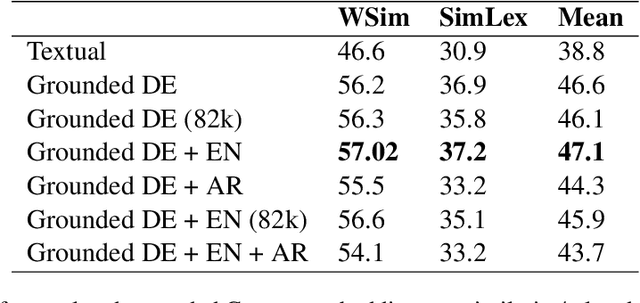
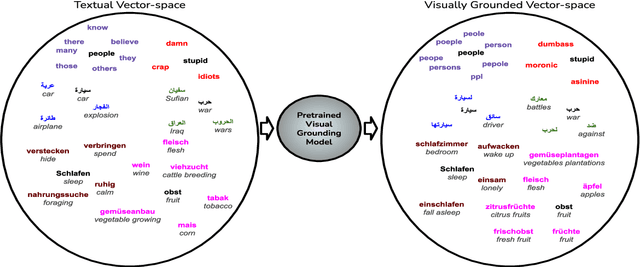
Visual grounding of Language aims at enriching textual representations of language with multiple sources of visual knowledge such as images and videos. Although visual grounding is an area of intense research, inter-lingual aspects of visual grounding have not received much attention. The present study investigates the inter-lingual visual grounding of word embeddings. We propose an implicit alignment technique between the two spaces of vision and language in which inter-lingual textual information interacts in order to enrich pre-trained textual word embeddings. We focus on three languages in our experiments, namely, English, Arabic, and German. We obtained visually grounded vector representations for these languages and studied whether visual grounding on one or multiple languages improved the performance of embeddings on word similarity and categorization benchmarks. Our experiments suggest that inter-lingual knowledge improves the performance of grounded embeddings in similar languages such as German and English. However, inter-lingual grounding of German or English with Arabic led to a slight degradation in performance on word similarity benchmarks. On the other hand, we observed an opposite trend on categorization benchmarks where Arabic had the most improvement on English. In the discussion section, several reasons for those findings are laid out. We hope that our experiments provide a baseline for further research on inter-lingual visual grounding.
Masader Plus: A New Interface for Exploring +500 Arabic NLP Datasets
Aug 01, 2022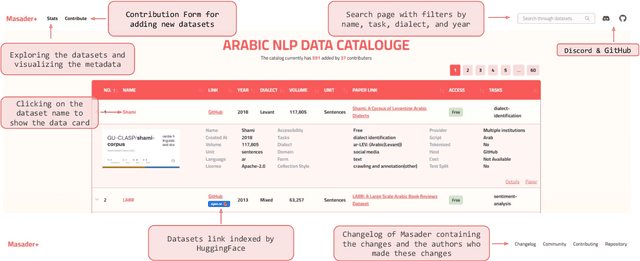
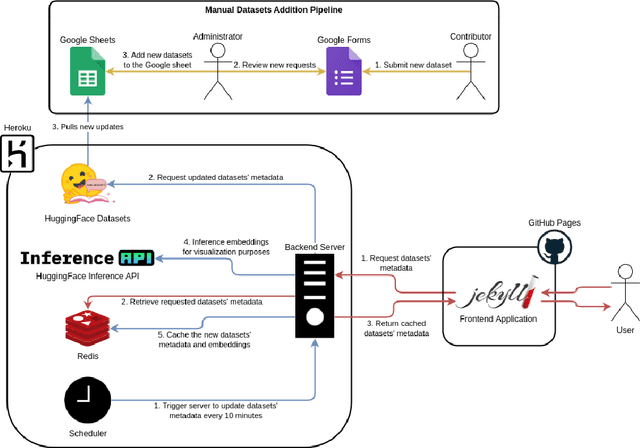
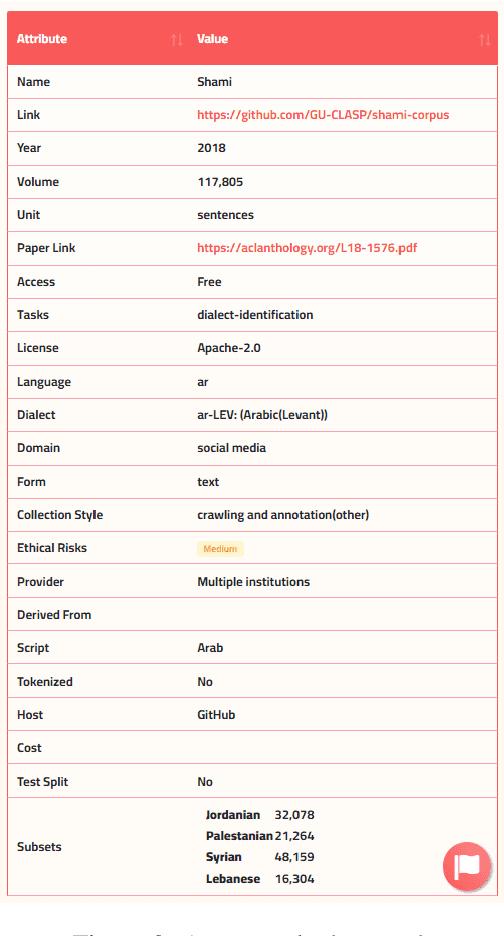
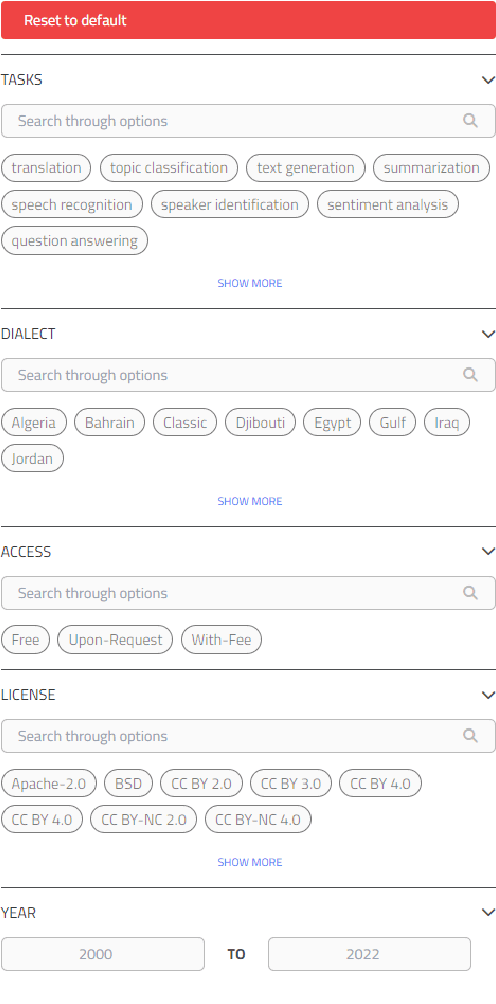
Masader (Alyafeai et al., 2021) created a metadata structure to be used for cataloguing Arabic NLP datasets. However, developing an easy way to explore such a catalogue is a challenging task. In order to give the optimal experience for users and researchers exploring the catalogue, several design and user experience challenges must be resolved. Furthermore, user interactions with the website may provide an easy approach to improve the catalogue. In this paper, we introduce Masader Plus, a web interface for users to browse Masader. We demonstrate data exploration, filtration, and a simple API that allows users to examine datasets from the backend. Masader Plus can be explored using this link https://arbml.github.io/masader. A video recording explaining the interface can be found here https://www.youtube.com/watch?v=SEtdlSeqchk.