 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Measuring Context Utilization in Document-Level MT Systems
Paper and Code


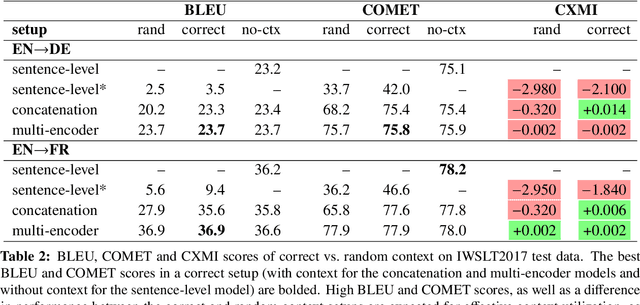

Document-level translation models are usually evaluated using general metrics such as BLEU, which are not informative about the benefits of context. Current work on context-aware evaluation, such as contrastive methods, only measure translation accuracy on words that need context for disambiguation. Such measures cannot reveal whether the translation model uses the correct supporting context. We propose to complement accuracy-based evaluation with measures of context utilization. We find that perturbation-based analysis (comparing models' performance when provided with correct versus random context) is an effective measure of overall context utilization. For a finer-grained phenomenon-specific evaluation, we propose to measure how much the supporting context contributes to handling context-dependent discourse phenomena. We show that automatically-annotated supporting context gives similar conclusions to human-annotated context and can be used as alternative for cases where human annotations are not available. Finally, we highlight the importance of using discourse-rich datasets when assessing context utilization.