Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Context Utilization of LLMs in Document-Level Translation
Paper and Code
Oct 18, 2024

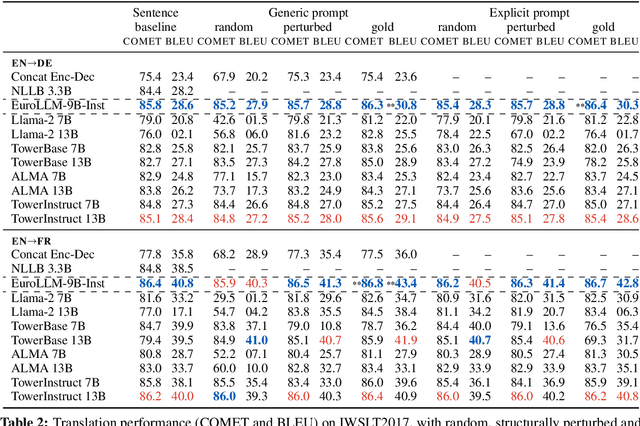
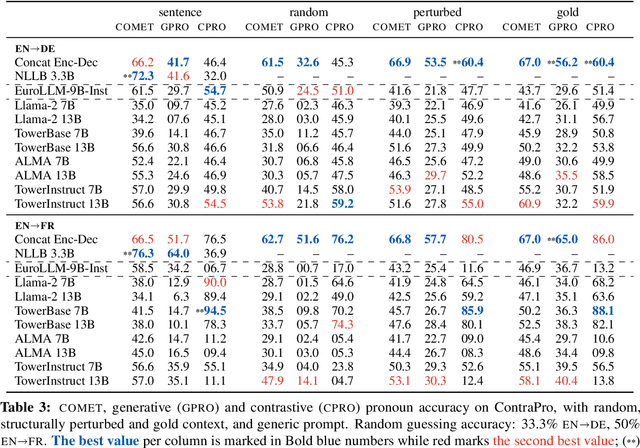
Large language models (LLM) are increasingly strong contenders in machine translation. We study document-level translation, where some words cannot be translated without context from outside the sentence. We investigate the ability of prominent LLMs to utilize context by analyzing models' robustness to perturbed and randomized document context. We find that LLMs' improved document-translation performance is not always reflected in pronoun translation performance. We highlight the need for context-aware finetuning of LLMs with a focus on relevant parts of the context to improve their reliability for document-level translation.
* 4 pages, 2 figures, 2 tables
View paper on