 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Conditional Minimum Bayes Risk Decoding
Oct 23, 2025Minimum Bayes Risk (MBR) decoding has seen renewed interest as an alternative to traditional generation strategies. While MBR has proven effective in machine translation, where the variability of a language model's outcome space is naturally constrained, it may face challenges in more open-ended tasks such as dialogue or instruction-following. We hypothesise that in such settings, applying MBR with standard similarity-based utility functions may result in selecting responses that are broadly representative of the model's distribution, yet sub-optimal with respect to any particular grouping of generations that share an underlying latent structure. In this work, we introduce three lightweight adaptations to the utility function, designed to make MBR more sensitive to structural variability in the outcome space. To test our hypothesis, we curate a dataset capturing three representative types of latent structure: dialogue act, emotion, and response structure (e.g., a sentence, a paragraph, or a list). We further propose two metrics to evaluate the structural optimality of MBR. Our analysis demonstrates that common similarity-based utility functions fall short by these metrics. In contrast, our proposed adaptations considerably improve structural optimality. Finally, we evaluate our approaches on real-world instruction-following benchmarks, AlpacaEval and MT-Bench, and show that increased structural sensitivity improves generation quality by up to 13.7 percentage points in win rate.
Teaching Language Models to Faithfully Express their Uncertainty
Oct 14, 2025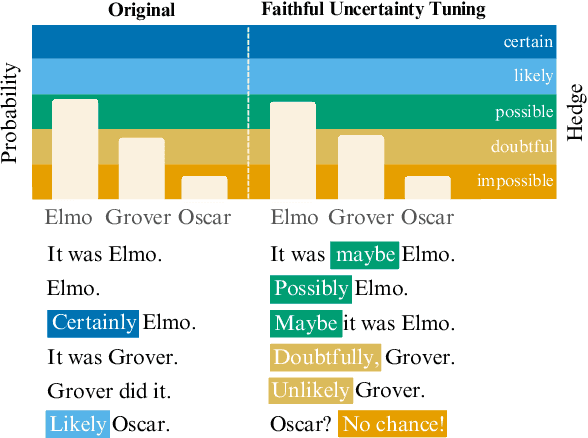
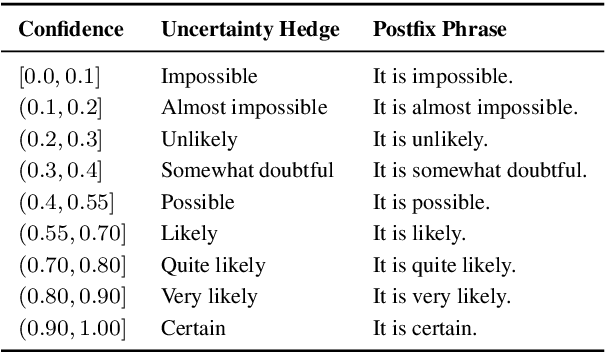
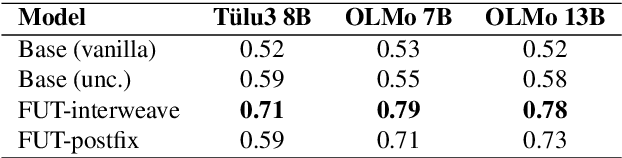
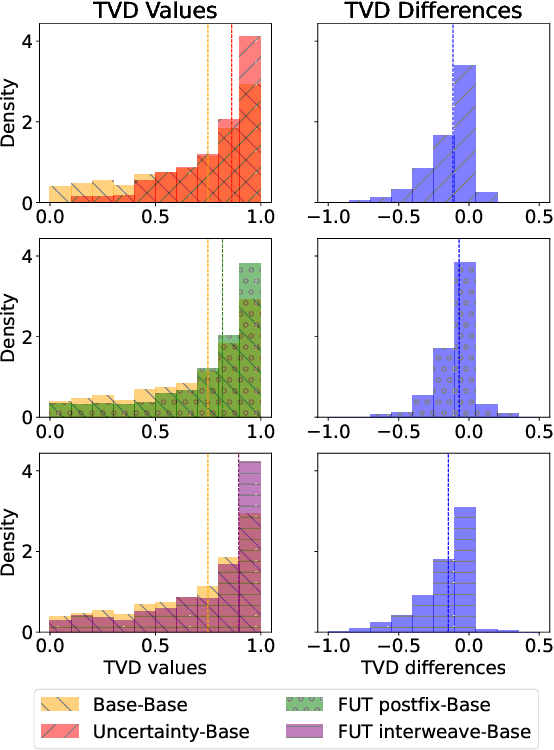
Large language models (LLMs) often miscommunicate their uncertainty: repeated queries can produce divergent answers, yet generated responses are typically unhedged or hedged in ways that do not reflect this variability. This conveys unfaithful information about the uncertain state of the LLMs' knowledge, creating a faithfulness gap that affects even strong LLMs. We introduce Faithful Uncertainty Tuning (FUT): a fine-tuning approach that teaches instruction-tuned LLMs to express uncertainty faithfully without altering their underlying answer distribution. We construct training data by augmenting model samples with uncertainty hedges (i.e. verbal cues such as 'possibly' or 'likely') aligned with sample consistency, requiring no supervision beyond the model and a set of prompts. We evaluate FUT on open-domain question answering (QA) across multiple models and datasets. Our results show that FUT substantially reduces the faithfulness gap, while preserving QA accuracy and introducing minimal semantic distribution shift. Further analyses demonstrate robustness across decoding strategies, choice of hedgers, and other forms of uncertainty expression (i.e. numerical). These findings establish FUT as a simple and effective way to teach LLMs to communicate uncertainty faithfully.
Findings of the WMT 2024 Shared Task on Chat Translation
Oct 15, 2024



This paper presents the findings from the third edition of the Chat Translation Shared Task. As with previous editions, the task involved translating bilingual customer support conversations, specifically focusing on the impact of conversation context in translation quality and evaluation. We also include two new language pairs: English-Korean and English-Dutch, in addition to the set of language pairs from previous editions: English-German, English-French, and English-Brazilian Portuguese. We received 22 primary submissions and 32 contrastive submissions from eight teams, with each language pair having participation from at least three teams. We evaluated the systems comprehensively using both automatic metrics and human judgments via a direct assessment framework. The official rankings for each language pair were determined based on human evaluation scores, considering performance in both translation directions--agent and customer. Our analysis shows that while the systems excelled at translating individual turns, there is room for improvement in overall conversation-level translation quality.
Sampling from Discrete Energy-Based Models with Quality/Efficiency Trade-offs
Dec 10, 2021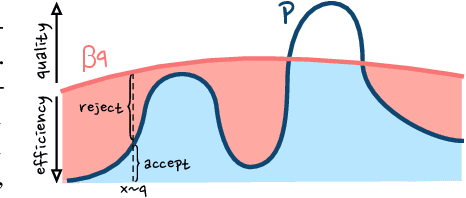

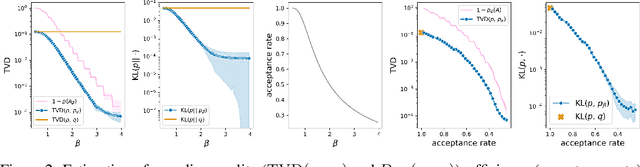
Energy-Based Models (EBMs) allow for extremely flexible specifications of probability distributions. However, they do not provide a mechanism for obtaining exact samples from these distributions. Monte Carlo techniques can aid us in obtaining samples if some proposal distribution that we can easily sample from is available. For instance, rejection sampling can provide exact samples but is often difficult or impossible to apply due to the need to find a proposal distribution that upper-bounds the target distribution everywhere. Approximate Markov chain Monte Carlo sampling techniques like Metropolis-Hastings are usually easier to design, exploiting a local proposal distribution that performs local edits on an evolving sample. However, these techniques can be inefficient due to the local nature of the proposal distribution and do not provide an estimate of the quality of their samples. In this work, we propose a new approximate sampling technique, Quasi Rejection Sampling (QRS), that allows for a trade-off between sampling efficiency and sampling quality, while providing explicit convergence bounds and diagnostics. QRS capitalizes on the availability of high-quality global proposal distributions obtained from deep learning models. We demonstrate the effectiveness of QRS sampling for discrete EBMs over text for the tasks of controlled text generation with distributional constraints and paraphrase generation. We show that we can sample from such EBMs with arbitrary precision at the cost of sampling efficiency.
Sampling-Based Minimum Bayes Risk Decoding for Neural Machine Translation
Aug 10, 2021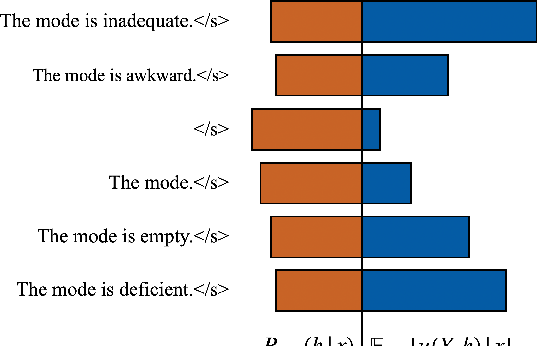
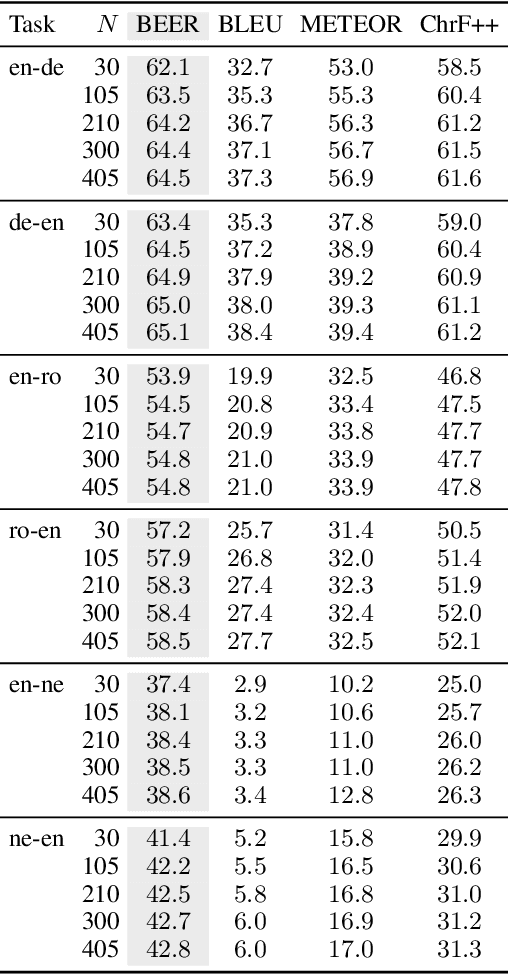
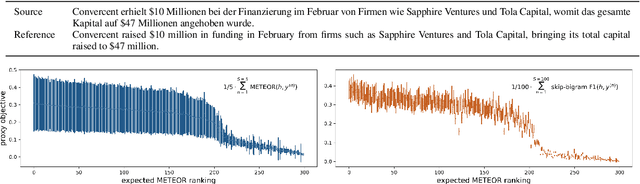
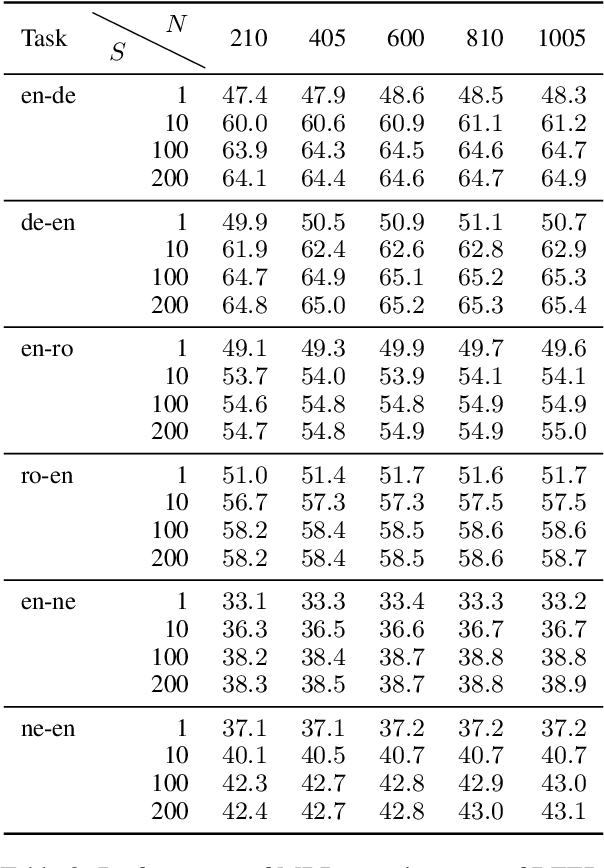
In neural machine translation (NMT), we search for the mode of the model distribution to form predictions. The mode as well as other high probability translations found by beam search have been shown to often be inadequate in a number of ways. This prevents practitioners from improving translation quality through better search, as these idiosyncratic translations end up being selected by the decoding algorithm, a problem known as the beam search curse. Recently, a sampling-based approximation to minimum Bayes risk (MBR) decoding has been proposed as an alternative decision rule for NMT that would likely not suffer from the same problems. We analyse this approximation and establish that it has no equivalent to the beam search curse, i.e. better search always leads to better translations. We also design different approximations aimed at decoupling the cost of exploration from the cost of robust estimation of expected utility. This allows for exploration of much larger hypothesis spaces, which we show to be beneficial. We also show that it can be beneficial to make use of strategies like beam search and nucleus sampling to construct hypothesis spaces efficiently. We show on three language pairs (English into and from German, Romanian, and Nepali) that MBR can improve upon beam search with moderate computation.
Is MAP Decoding All You Need? The Inadequacy of the Mode in Neural Machine Translation
May 20, 2020



Recent studies have revealed a number of pathologies of neural machine translation (NMT) systems. Hypotheses explaining these mostly suggest that there is something fundamentally wrong with NMT as a model or its training algorithm, maximum likelihood estimation (MLE). Most of this evidence was gathered using maximum a posteriori (MAP) decoding, a decision rule aimed at identifying the highest-scoring translation, i.e. the mode, under the model distribution. We argue that the evidence corroborates the inadequacy of MAP decoding more than casts doubt on the model and its training algorithm. In this work, we criticise NMT models probabilistically showing that stochastic samples following the model's own generative story do reproduce various statistics of the training data well, but that it is beam search that strays from such statistics. We show that some of the known pathologies of NMT are due to MAP decoding and not to NMT's statistical assumptions nor MLE. In particular, we show that the most likely translations under the model accumulate so little probability mass that the mode can be considered essentially arbitrary. We therefore advocate for the use of decision rules that take into account statistics gathered from the model distribution holistically. As a proof of concept we show that a straightforward implementation of minimum Bayes risk decoding gives good results outperforming beam search using as little as 30 samples, confirming that MLE-trained NMT models do capture important aspects of translation well in expectation.
Auto-Encoding Variational Neural Machine Translation
Aug 01, 2018


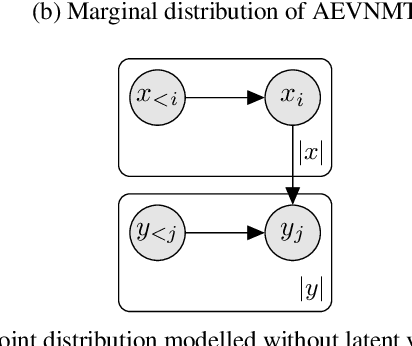
We present a deep generative model of bilingual sentence pairs. The model generates source and target sentences jointly from a shared latent representation and is parameterised by neural networks. Efficient training is done by amortised variational inference and reparameterised gradients. Additionally, we discuss the statistical implications of joint modelling and propose an efficient approximation to maximum a posteriori decoding for fast test-time predictions. We demonstrate the effectiveness of our model in three machine translation scenarios: in-domain training, mixed-domain training, and learning from a mix of gold-standard and synthetic data. Our experiments show consistently that our joint formulation outperforms conditional modelling in all such scenarios.