 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling-Based Minimum Bayes Risk Decoding for Neural Machine Translation
Paper and Code
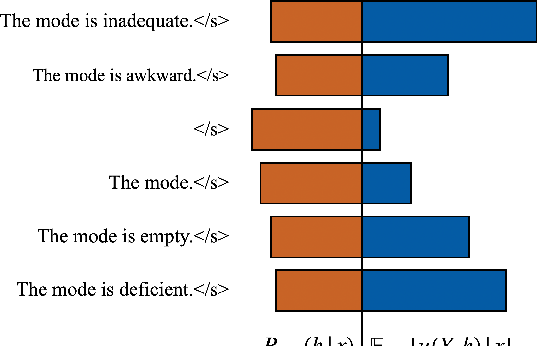
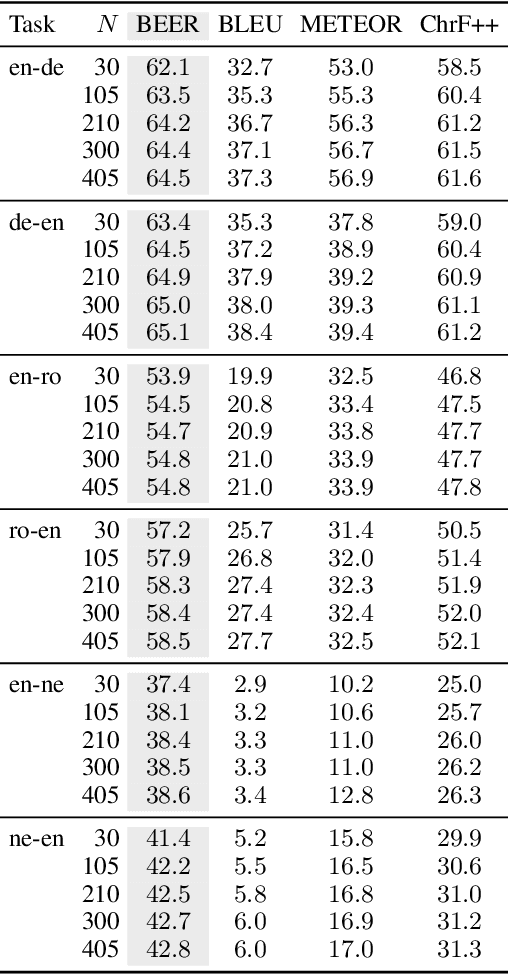
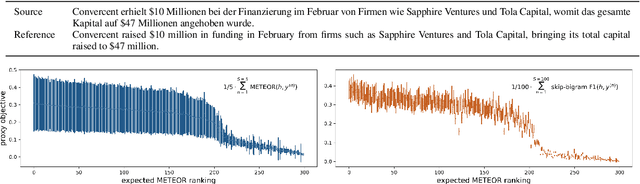
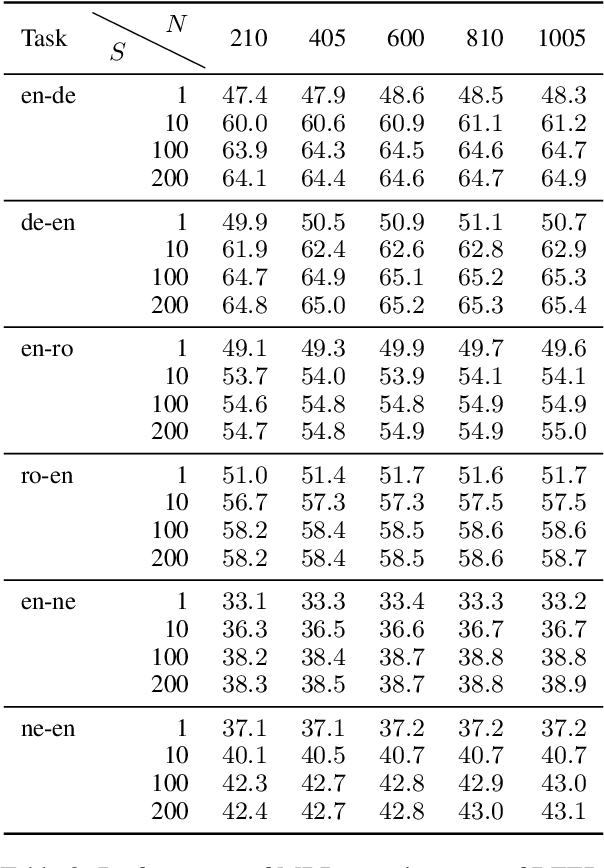
In neural machine translation (NMT), we search for the mode of the model distribution to form predictions. The mode as well as other high probability translations found by beam search have been shown to often be inadequate in a number of ways. This prevents practitioners from improving translation quality through better search, as these idiosyncratic translations end up being selected by the decoding algorithm, a problem known as the beam search curse. Recently, a sampling-based approximation to minimum Bayes risk (MBR) decoding has been proposed as an alternative decision rule for NMT that would likely not suffer from the same problems. We analyse this approximation and establish that it has no equivalent to the beam search curse, i.e. better search always leads to better translations. We also design different approximations aimed at decoupling the cost of exploration from the cost of robust estimation of expected utility. This allows for exploration of much larger hypothesis spaces, which we show to be beneficial. We also show that it can be beneficial to make use of strategies like beam search and nucleus sampling to construct hypothesis spaces efficiently. We show on three language pairs (English into and from German, Romanian, and Nepali) that MBR can improve upon beam search with moderate computation.