 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Polarization: Toward Electron Density for Molecules by Extending Equivariant Networks
Jun 01, 2024



Recent SO(3)-equivariant models embedded a molecule as a set of single atoms fixed in the three-dimensional space, which is analogous to a ball-and-stick view. This perspective provides a concise view of atom arrangements, however, the surrounding electron density cannot be represented and its polarization effects may be underestimated. To overcome this limitation, we propose \textit{Neural Polarization}, a novel method extending equivariant network by embedding each atom as a pair of fixed and moving points. Motivated by density functional theory, Neural Polarization represents molecules as a space-filling view which includes an electron density, in contrast with a ball-and-stick view. Neural Polarization can flexibly be applied to most type of existing equivariant models. We showed that Neural Polarization can improve prediction performances of existing models over a wide range of targets. Finally, we verified that our method can improve the expressiveness and equivariance in terms of mathematical aspects.
Gradient Scaling on Deep Spiking Neural Networks with Spike-Dependent Local Information
Aug 01, 2023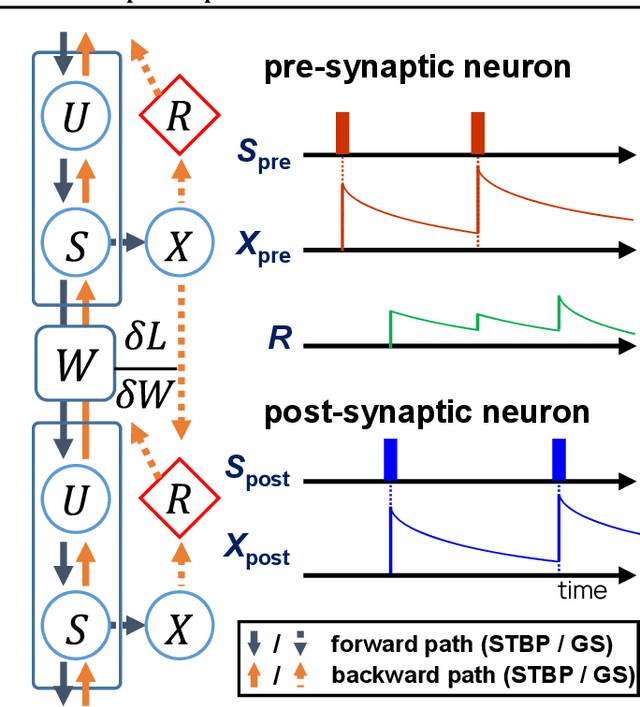
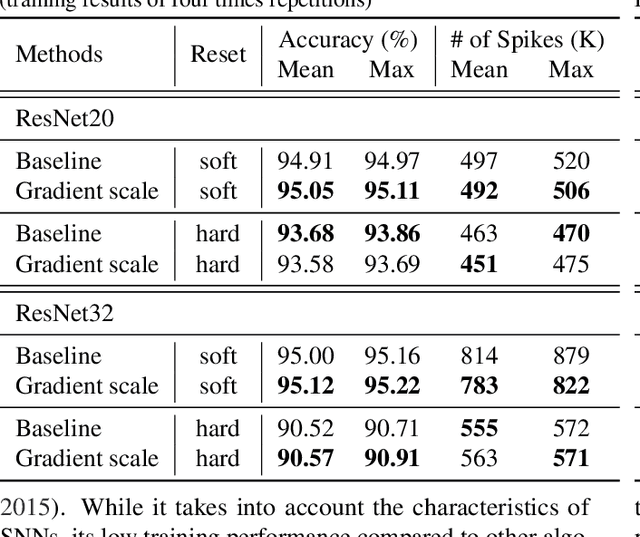
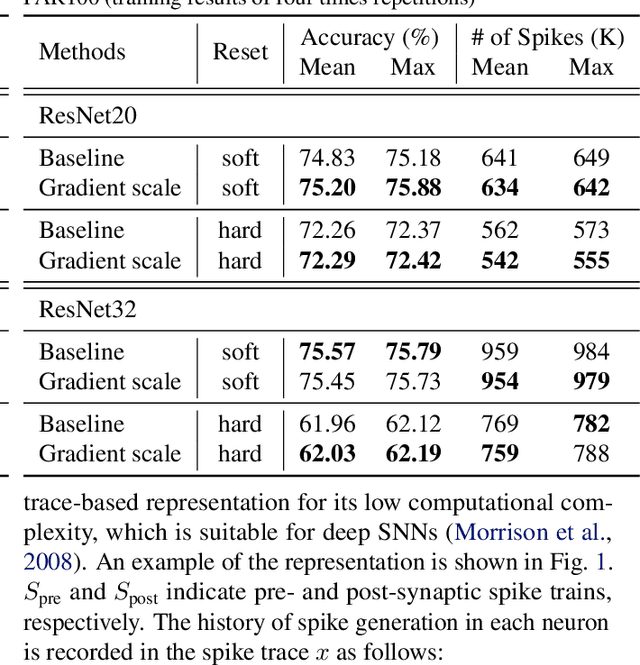
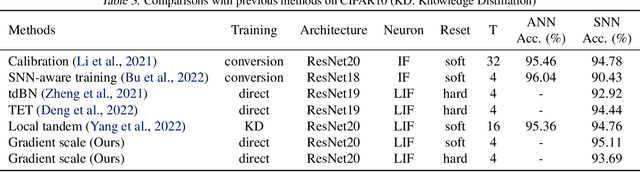
Deep spiking neural networks (SNNs) are promising neural networks for their model capacity from deep neural network architecture and energy efficiency from SNNs' operations. To train deep SNNs, recently, spatio-temporal backpropagation (STBP) with surrogate gradient was proposed. Although deep SNNs have been successfully trained with STBP, they cannot fully utilize spike information. In this work, we proposed gradient scaling with local spike information, which is the relation between pre- and post-synaptic spikes. Considering the causality between spikes, we could enhance the training performance of deep SNNs. According to our experiments, we could achieve higher accuracy with lower spikes by adopting the gradient scaling on image classification tasks, such as CIFAR10 and CIFAR100.
Mass Spectra Prediction with Structural Motif-based Graph Neural Networks
Jun 28, 2023Mass spectra, which are agglomerations of ionized fragments from targeted molecules, play a crucial role across various fields for the identification of molecular structures. A prevalent analysis method involves spectral library searches,where unknown spectra are cross-referenced with a database. The effectiveness of such search-based approaches, however, is restricted by the scope of the existing mass spectra database, underscoring the need to expand the database via mass spectra prediction. In this research, we propose the Motif-based Mass Spectrum Prediction Network (MoMS-Net), a system that predicts mass spectra using the information derived from structural motifs and the implementation of Graph Neural Networks (GNNs). We have tested our model across diverse mass spectra and have observed its superiority over other existing models. MoMS-Net considers substructure at the graph level, which facilitates the incorporation of long-range dependencies while using less memory compared to the graph transformer model.
E2V-SDE: From Asynchronous Events to Fast and Continuous Video Reconstruction via Neural Stochastic Differential Equations
Jun 15, 2022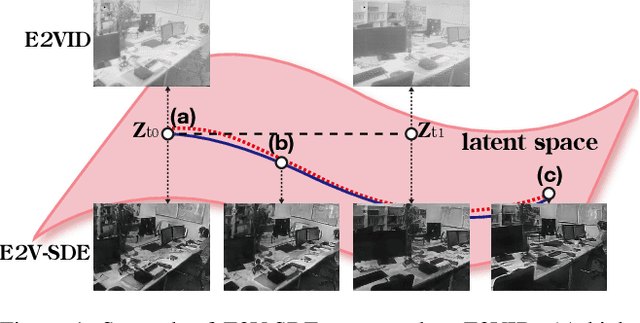
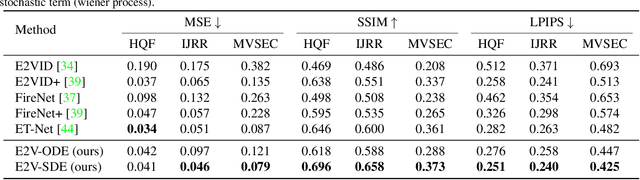
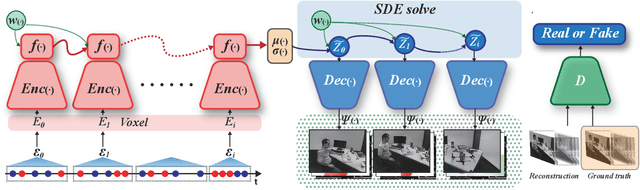
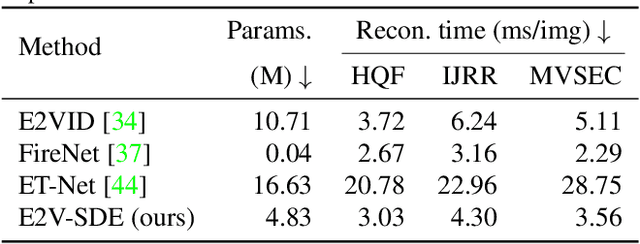
Event cameras respond to brightness changes in the scene asynchronously and independently for every pixel. Due to the properties, these cameras have distinct features: high dynamic range (HDR), high temporal resolution, and low power consumption. However, the results of event cameras should be processed into an alternative representation for computer vision tasks. Also, they are usually noisy and cause poor performance in areas with few events. In recent years, numerous researchers have attempted to reconstruct videos from events. However, they do not provide good quality videos due to a lack of temporal information from irregular and discontinuous data. To overcome these difficulties, we introduce an E2V-SDE whose dynamics are governed in a latent space by Stochastic differential equations (SDE). Therefore, E2V-SDE can rapidly reconstruct images at arbitrary time steps and make realistic predictions on unseen data. In addition, we successfully adopted a variety of image composition techniques for improving image clarity and temporal consistency. By conducting extensive experiments on simulated and real-scene datasets, we verify that our model outperforms state-of-the-art approaches under various video reconstruction settings. In terms of image quality, the LPIPS score improves by up to 12% and the reconstruction speed is 87% higher than that of ET-Net.
* 2022 CVPR oral
Geometry-aware Transformer for molecular property prediction
Jun 29, 2021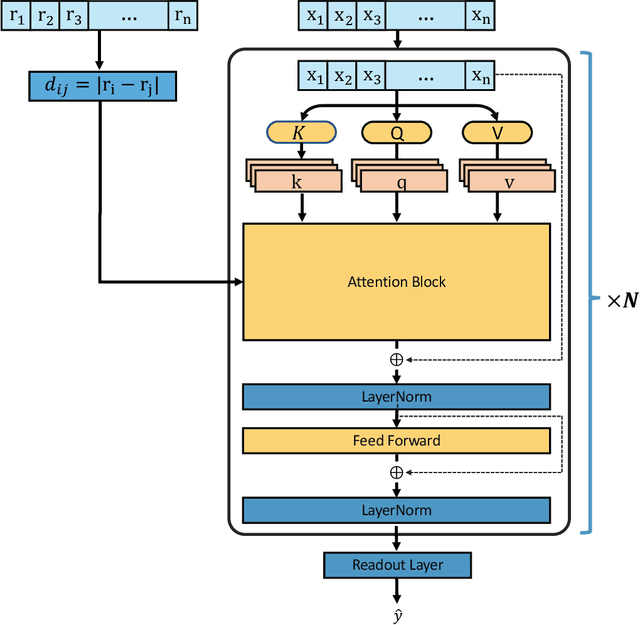
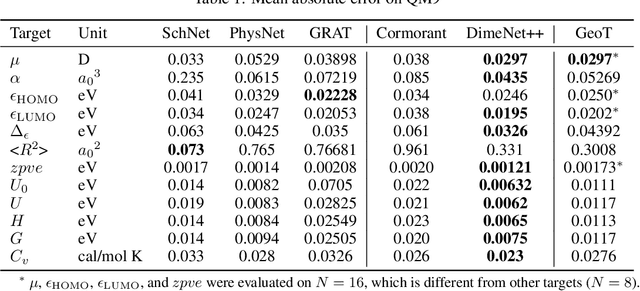
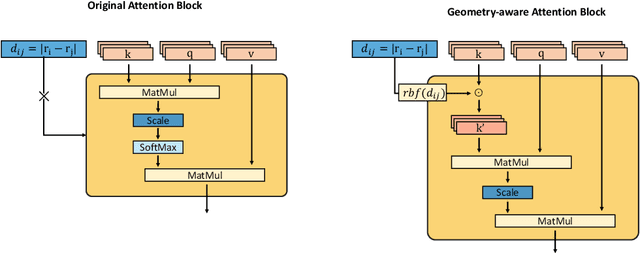
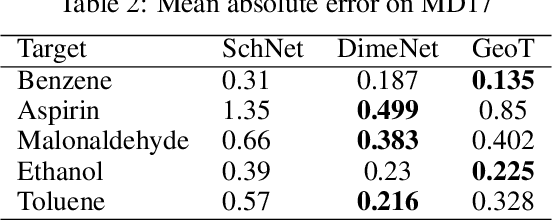
Recently, graph neural networks (GNNs) have achieved remarkable performances for quantum mechanical problems. However, a graph convolution can only cover a localized region, and cannot capture long-range interactions of atoms. This behavior is contrary to theoretical interatomic potentials, which is a fundamental limitation of the spatial based GNNs. In this work, we propose a novel attention-based framework for molecular property prediction tasks. We represent a molecular conformation as a discrete atomic sequence combined by atom-atom distance attributes, named Geometry-aware Transformer (GeoT). In particular, we adopt a Transformer architecture, which has been widely used for sequential data. Our proposed model trains sequential representations of molecular graphs based on globally constructed attentions, maintaining all spatial arrangements of atom pairs. Our method does not suffer from cost intensive computations, such as angle calculations. The experimental results on several public benchmarks and visualization maps verified that keeping the long-range interatomic attributes can significantly improve the model predictability.
Flexible dual-branched message passing neural network for quantum mechanical property prediction with molecular conformation
Jun 14, 2021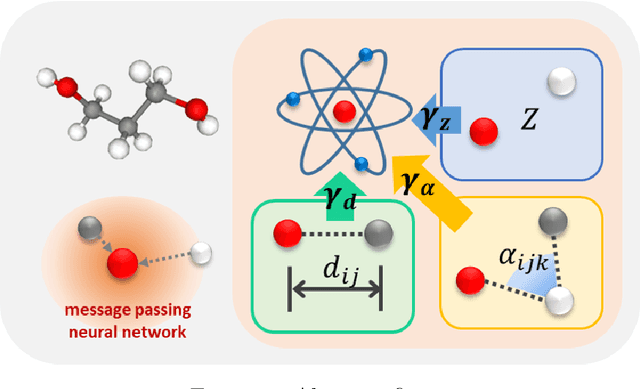
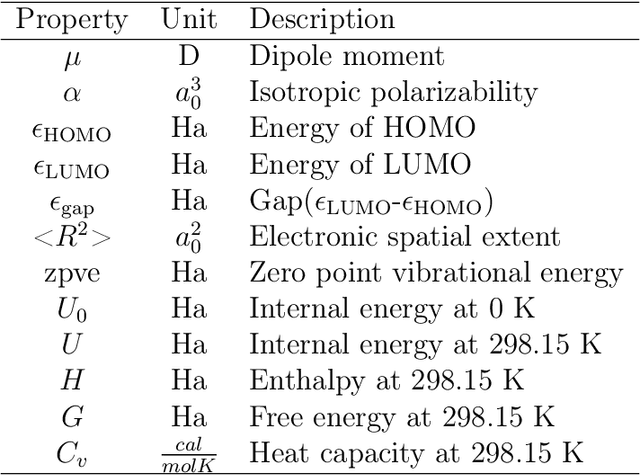
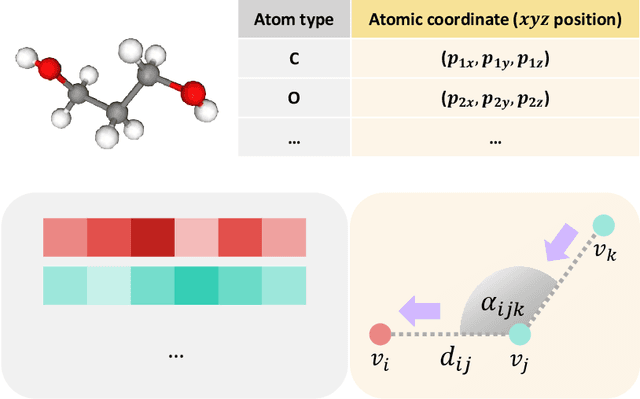
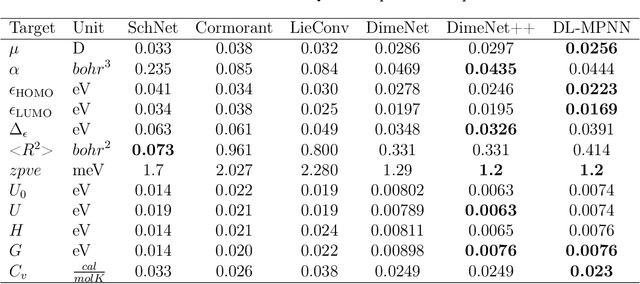
A molecule is a complex of heterogeneous components, and the spatial arrangements of these components determine the whole molecular properties and characteristics. With the advent of deep learning in computational chemistry, several studies have focused on how to predict molecular properties based on molecular configurations. Message passing neural network provides an effective framework for capturing molecular geometric features with the perspective of a molecule as a graph. However, most of these studies assumed that all heterogeneous molecular features, such as atomic charge, bond length, or other geometric features always contribute equivalently to the target prediction, regardless of the task type. In this study, we propose a dual-branched neural network for molecular property prediction based on message-passing framework. Our model learns heterogeneous molecular features with different scales, which are trained flexibly according to each prediction target. In addition, we introduce a discrete branch to learn single atom features without local aggregation, apart from message-passing steps. We verify that this novel structure can improve the model performance with faster convergence in most targets. The proposed model outperforms other recent models with sparser representations. Our experimental results indicate that in the chemical property prediction tasks, the diverse chemical nature of targets should be carefully considered for both model performance and generalizability.