 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2Former: Multi-Scale Patch Selection for Fine-Grained Visual Recognition
Aug 04, 2023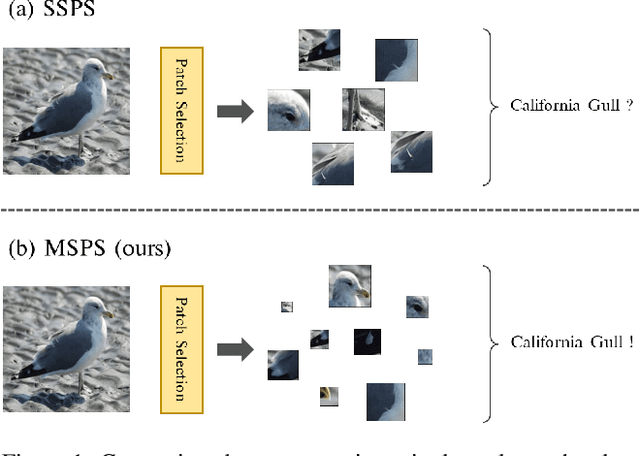
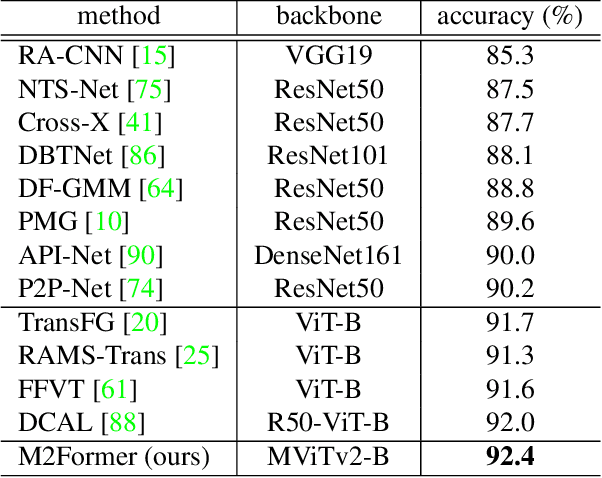
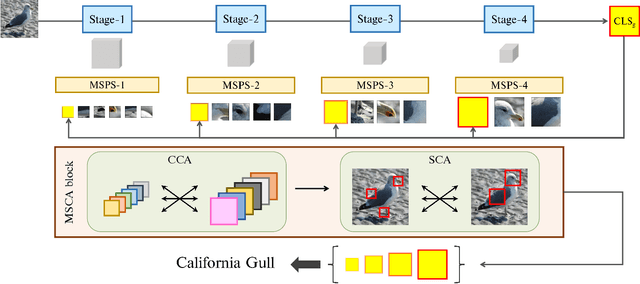
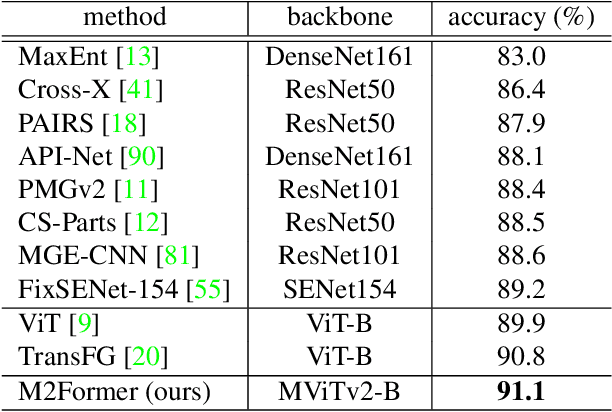
Recently, vision Transformers (ViTs) have been actively applied to fine-grained visual recognition (FGVR). ViT can effectively model the interdependencies between patch-divided object regions through an inherent self-attention mechanism. In addition, patch selection is used with ViT to remove redundant patch information and highlight the most discriminative object patches. However, existing ViT-based FGVR models are limited to single-scale processing, and their fixed receptive fields hinder representational richness and exacerbate vulnerability to scale variability. Therefore, we propose multi-scale patch selection (MSPS) to improve the multi-scale capabilities of existing ViT-based models. Specifically, MSPS selects salient patches of different scales at different stages of a multi-scale vision Transformer (MS-ViT). In addition, we introduce class token transfer (CTT) and multi-scale cross-attention (MSCA) to model cross-scale interactions between selected multi-scale patches and fully reflect them in model decisions. Compared to previous single-scale patch selection (SSPS), our proposed MSPS encourages richer object representations based on feature hierarchy and consistently improves performance from small-sized to large-sized objects. As a result, we propose M2Former, which outperforms CNN-/ViT-based models on several widely used FGVR benchmarks.
SimFLE: Simple Facial Landmark Encoding for Self-Supervised Facial Expression Recognition in the Wild
Mar 14, 2023One of the key issues in facial expression recognition in the wild (FER-W) is that curating large-scale labeled facial images is challenging due to the inherent complexity and ambiguity of facial images. Therefore, in this paper, we propose a self-supervised simple facial landmark encoding (SimFLE) method that can learn effective encoding of facial landmarks, which are important features for improving the performance of FER-W, without expensive labels. Specifically, we introduce novel FaceMAE module for this purpose. FaceMAE reconstructs masked facial images with elaborately designed semantic masking. Unlike previous random masking, semantic masking is conducted based on channel information processed in the backbone, so rich semantics of channels can be explored. Additionally, the semantic masking process is fully trainable, enabling FaceMAE to guide the backbone to learn spatial details and contextual properties of fine-grained facial landmarks. Experimental results on several FER-W benchmarks prove that the proposed SimFLE is superior in facial landmark localization and noticeably improved performance compared to the supervised baseline and other self-supervised methods.