 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVolumetric Conditioning Module to Control Pretrained Diffusion Models for 3D Medical Images
Oct 29, 2024
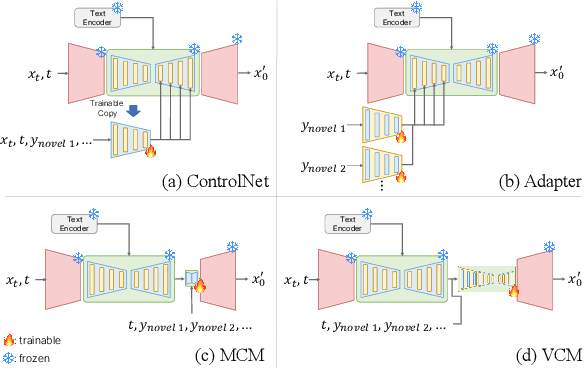


Spatial control methods using additional modules on pretrained diffusion models have gained attention for enabling conditional generation in natural images. These methods guide the generation process with new conditions while leveraging the capabilities of large models. They could be beneficial as training strategies in the context of 3D medical imaging, where training a diffusion model from scratch is challenging due to high computational costs and data scarcity. However, the potential application of spatial control methods with additional modules to 3D medical images has not yet been explored. In this paper, we present a tailored spatial control method for 3D medical images with a novel lightweight module, Volumetric Conditioning Module (VCM). Our VCM employs an asymmetric U-Net architecture to effectively encode complex information from various levels of 3D conditions, providing detailed guidance in image synthesis. To examine the applicability of spatial control methods and the effectiveness of VCM for 3D medical data, we conduct experiments under single- and multimodal conditions scenarios across a wide range of dataset sizes, from extremely small datasets with 10 samples to large datasets with 500 samples. The experimental results show that the VCM is effective for conditional generation and efficient in terms of requiring less training data and computational resources. We further investigate the potential applications for our spatial control method through axial super-resolution for medical images. Our code is available at \url{https://github.com/Ahn-Ssu/VCM}
Two-Stage Approach for Brain MR Image Synthesis: 2D Image Synthesis and 3D Refinement
Oct 14, 2024Despite significant advancements in automatic brain tumor segmentation methods, their performance is not guaranteed when certain MR sequences are missing. Addressing this issue, it is crucial to synthesize the missing MR images that reflect the unique characteristics of the absent modality with precise tumor representation. Typically, MRI synthesis methods generate partial images rather than full-sized volumes due to computational constraints. This limitation can lead to a lack of comprehensive 3D volumetric information and result in image artifacts during the merging process. In this paper, we propose a two-stage approach that first synthesizes MR images from 2D slices using a novel intensity encoding method and then refines the synthesized MRI. The proposed intensity encoding reduces artifacts when synthesizing MRI on a 2D slice basis. Then, the \textit{Refiner}, which leverages complete 3D volume information, further improves the quality of the synthesized images and enhances their applicability to segmentation methods. Experimental results demonstrate that the intensity encoding effectively minimizes artifacts in the synthesized MRI and improves perceptual quality. Furthermore, using the \textit{Refiner} on synthesized MRI significantly improves brain tumor segmentation results, highlighting the potential of our approach in practical applications.