 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmenting Thalamic Nuclei: T1 Maps Provide a Reliable and Efficient Solution
Aug 17, 2025Accurate thalamic nuclei segmentation is crucial for understanding neurological diseases, brain functions, and guiding clinical interventions. However, the optimal inputs for segmentation remain unclear. This study systematically evaluates multiple MRI contrasts, including MPRAGE and FGATIR sequences, quantitative PD and T1 maps, and multiple T1-weighted images at different inversion times (multi-TI), to determine the most effective inputs. For multi-TI images, we employ a gradient-based saliency analysis with Monte Carlo dropout and propose an Overall Importance Score to select the images contributing most to segmentation. A 3D U-Net is trained on each of these configurations. Results show that T1 maps alone achieve strong quantitative performance and superior qualitative outcomes, while PD maps offer no added value. These findings underscore the value of T1 maps as a reliable and efficient input among the evaluated options, providing valuable guidance for optimizing imaging protocols when thalamic structures are of clinical or research interest.
Synthetic multi-inversion time magnetic resonance images for visualization of subcortical structures
Jun 04, 2025Purpose: Visualization of subcortical gray matter is essential in neuroscience and clinical practice, particularly for disease understanding and surgical planning.While multi-inversion time (multi-TI) T$_1$-weighted (T$_1$-w) magnetic resonance (MR) imaging improves visualization, it is rarely acquired in clinical settings. Approach: We present SyMTIC (Synthetic Multi-TI Contrasts), a deep learning method that generates synthetic multi-TI images using routinely acquired T$_1$-w, T$_2$-weighted (T$_2$-w), and FLAIR images. Our approach combines image translation via deep neural networks with imaging physics to estimate longitudinal relaxation time (T$_1$) and proton density (PD) maps. These maps are then used to compute multi-TI images with arbitrary inversion times. Results: SyMTIC was trained using paired MPRAGE and FGATIR images along with T$_2$-w and FLAIR images. It accurately synthesized multi-TI images from standard clinical inputs, achieving image quality comparable to that from explicitly acquired multi-TI data.The synthetic images, especially for TI values between 400-800 ms, enhanced visualization of subcortical structures and improved segmentation of thalamic nuclei. Conclusion: SyMTIC enables robust generation of high-quality multi-TI images from routine MR contrasts. It generalizes well to varied clinical datasets, including those with missing FLAIR images or unknown parameters, offering a practical solution for improving brain MR image visualization and analysis.
Brightness-Invariant Tracking Estimation in Tagged MRI
May 23, 2025Magnetic resonance (MR) tagging is an imaging technique for noninvasively tracking tissue motion in vivo by creating a visible pattern of magnetization saturation (tags) that deforms with the tissue. Due to longitudinal relaxation and progression to steady-state, the tags and tissue brightnesses change over time, which makes tracking with optical flow methods error-prone. Although Fourier methods can alleviate these problems, they are also sensitive to brightness changes as well as spectral spreading due to motion. To address these problems, we introduce the brightness-invariant tracking estimation (BRITE) technique for tagged MRI. BRITE disentangles the anatomy from the tag pattern in the observed tagged image sequence and simultaneously estimates the Lagrangian motion. The inherent ill-posedness of this problem is addressed by leveraging the expressive power of denoising diffusion probabilistic models to represent the probabilistic distribution of the underlying anatomy and the flexibility of physics-informed neural networks to estimate biologically-plausible motion. A set of tagged MR images of a gel phantom was acquired with various tag periods and imaging flip angles to demonstrate the impact of brightness variations and to validate our method. The results show that BRITE achieves more accurate motion and strain estimates as compared to other state of the art methods, while also being resistant to tag fading.
A Speech-to-Video Synthesis Approach Using Spatio-Temporal Diffusion for Vocal Tract MRI
Mar 15, 2025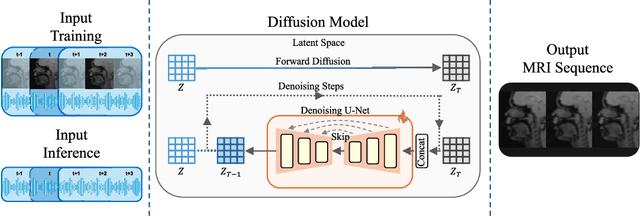
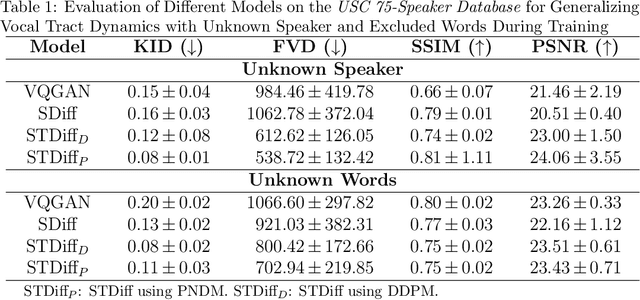
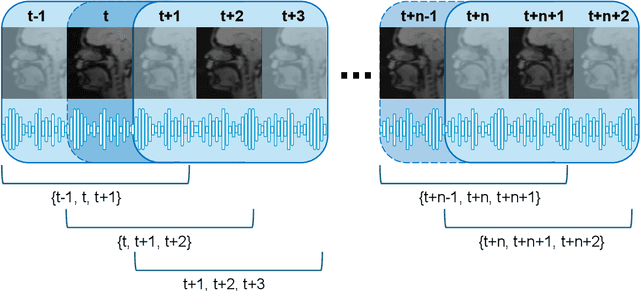

Understanding the relationship between vocal tract motion during speech and the resulting acoustic signal is crucial for aided clinical assessment and developing personalized treatment and rehabilitation strategies. Toward this goal, we introduce an audio-to-video generation framework for creating Real Time/cine-Magnetic Resonance Imaging (RT-/cine-MRI) visuals of the vocal tract from speech signals. Our framework first preprocesses RT-/cine-MRI sequences and speech samples to achieve temporal alignment, ensuring synchronization between visual and audio data. We then employ a modified stable diffusion model, integrating structural and temporal blocks, to effectively capture movement characteristics and temporal dynamics in the synchronized data. This process enables the generation of MRI sequences from new speech inputs, improving the conversion of audio into visual data. We evaluated our framework on healthy controls and tongue cancer patients by analyzing and comparing the vocal tract movements in synthesized videos. Our framework demonstrated adaptability to new speech inputs and effective generalization. In addition, positive human evaluations confirmed its effectiveness, with realistic and accurate visualizations, suggesting its potential for outpatient therapy and personalized simulation of vocal tract visualizations.
RATNUS: Rapid, Automatic Thalamic Nuclei Segmentation using Multimodal MRI inputs
Sep 10, 2024



Accurate segmentation of thalamic nuclei is important for better understanding brain function and improving disease treatment. Traditional segmentation methods often rely on a single T1-weighted image, which has limited contrast in the thalamus. In this work, we introduce RATNUS, which uses synthetic T1-weighted images with many inversion times along with diffusion-derived features to enhance the visibility of nuclei within the thalamus. Using these features, a convolutional neural network is used to segment 13 thalamic nuclei. For comparison with other methods, we introduce a unified nuclei labeling scheme. Our results demonstrate an 87.19% average true positive rate (TPR) against manual labeling. In comparison, FreeSurfer and THOMAS achieve TPRs of 64.25% and 57.64%, respectively, demonstrating the superiority of RATNUS in thalamic nuclei segmentation.
Revisiting registration-based synthesis: A focus on unsupervised MR image synthesis
Feb 19, 2024Deep learning (DL) has led to significant improvements in medical image synthesis, enabling advanced image-to-image translation to generate synthetic images. However, DL methods face challenges such as domain shift and high demands for training data, limiting their generalizability and applicability. Historically, image synthesis was also carried out using deformable image registration (DIR), a method that warps moving images of a desired modality to match the anatomy of a fixed image. However, concerns about its speed and accuracy led to its decline in popularity. With the recent advances of DL-based DIR, we now revisit and reinvigorate this line of research. In this paper, we propose a fast and accurate synthesis method based on DIR. We use the task of synthesizing a rare magnetic resonance (MR) sequence, white matter nulled (WMn) T1-weighted (T1-w) images, to demonstrate the potential of our approach. During training, our method learns a DIR model based on the widely available MPRAGE sequence, which is a cerebrospinal fluid nulled (CSFn) T1-w inversion recovery gradient echo pulse sequence. During testing, the trained DIR model is first applied to estimate the deformation between moving and fixed CSFn images. Subsequently, this estimated deformation is applied to align the paired WMn counterpart of the moving CSFn image, yielding a synthetic WMn image for the fixed CSFn image. Our experiments demonstrate promising results for unsupervised image synthesis using DIR. These findings highlight the potential of our technique in contexts where supervised synthesis methods are constrained by limited training data.
Speech motion anomaly detection via cross-modal translation of 4D motion fields from tagged MRI
Feb 10, 2024Understanding the relationship between tongue motion patterns during speech and their resulting speech acoustic outcomes -- i.e., articulatory-acoustic relation -- is of great importance in assessing speech quality and developing innovative treatment and rehabilitative strategies. This is especially important when evaluating and detecting abnormal articulatory features in patients with speech-related disorders. In this work, we aim to develop a framework for detecting speech motion anomalies in conjunction with their corresponding speech acoustics. This is achieved through the use of a deep cross-modal translator trained on data from healthy individuals only, which bridges the gap between 4D motion fields obtained from tagged MRI and 2D spectrograms derived from speech acoustic data. The trained translator is used as an anomaly detector, by measuring the spectrogram reconstruction quality on healthy individuals or patients. In particular, the cross-modal translator is likely to yield limited generalization capabilities on patient data, which includes unseen out-of-distribution patterns and demonstrates subpar performance, when compared with healthy individuals.~A one-class SVM is then used to distinguish the spectrograms of healthy individuals from those of patients. To validate our framework, we collected a total of 39 paired tagged MRI and speech waveforms, consisting of data from 36 healthy individuals and 3 tongue cancer patients. We used both 3D convolutional and transformer-based deep translation models, training them on the healthy training set and then applying them to both the healthy and patient testing sets. Our framework demonstrates a capability to detect abnormal patient data, thereby illustrating its potential in enhancing the understanding of the articulatory-acoustic relation for both healthy individuals and patients.
Is Registering Raw Tagged-MR Enough for Strain Estimation in the Era of Deep Learning?
Jan 31, 2024Magnetic Resonance Imaging with tagging (tMRI) has long been utilized for quantifying tissue motion and strain during deformation. However, a phenomenon known as tag fading, a gradual decrease in tag visibility over time, often complicates post-processing. The first contribution of this study is to model tag fading by considering the interplay between $T_1$ relaxation and the repeated application of radio frequency (RF) pulses during serial imaging sequences. This is a factor that has been overlooked in prior research on tMRI post-processing. Further, we have observed an emerging trend of utilizing raw tagged MRI within a deep learning-based (DL) registration framework for motion estimation. In this work, we evaluate and analyze the impact of commonly used image similarity objectives in training DL registrations on raw tMRI. This is then compared with the Harmonic Phase-based approach, a traditional approach which is claimed to be robust to tag fading. Our findings, derived from both simulated images and an actual phantom scan, reveal the limitations of various similarity losses in raw tMRI and emphasize caution in registration tasks where image intensity changes over time.
Speech Audio Synthesis from Tagged MRI and Non-Negative Matrix Factorization via Plastic Transformer
Sep 26, 2023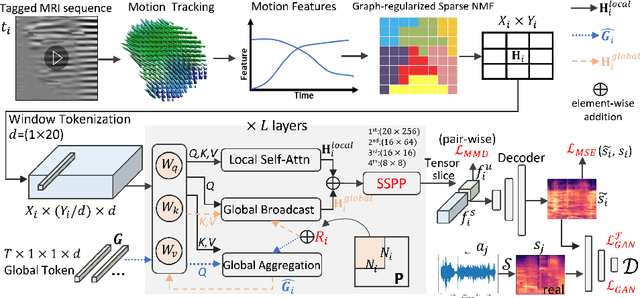
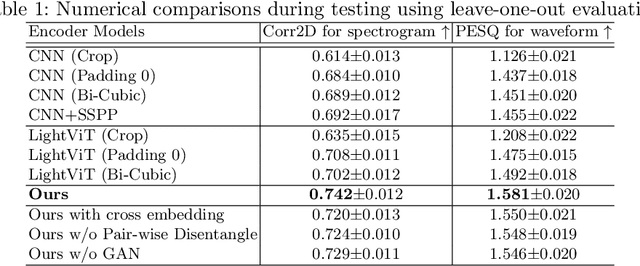
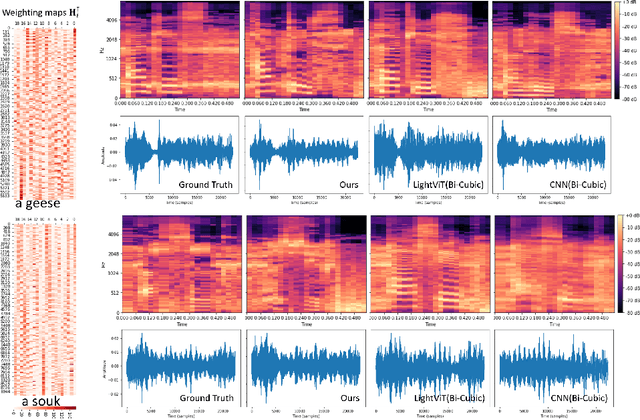
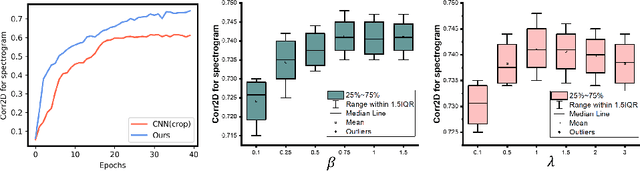
The tongue's intricate 3D structure, comprising localized functional units, plays a crucial role in the production of speech. When measured using tagged MRI, these functional units exhibit cohesive displacements and derived quantities that facilitate the complex process of speech production. Non-negative matrix factorization-based approaches have been shown to estimate the functional units through motion features, yielding a set of building blocks and a corresponding weighting map. Investigating the link between weighting maps and speech acoustics can offer significant insights into the intricate process of speech production. To this end, in this work, we utilize two-dimensional spectrograms as a proxy representation, and develop an end-to-end deep learning framework for translating weighting maps to their corresponding audio waveforms. Our proposed plastic light transformer (PLT) framework is based on directional product relative position bias and single-level spatial pyramid pooling, thus enabling flexible processing of weighting maps with variable size to fixed-size spectrograms, without input information loss or dimension expansion. Additionally, our PLT framework efficiently models the global correlation of wide matrix input. To improve the realism of our generated spectrograms with relatively limited training samples, we apply pair-wise utterance consistency with Maximum Mean Discrepancy constraint and adversarial training. Experimental results on a dataset of 29 subjects speaking two utterances demonstrated that our framework is able to synthesize speech audio waveforms from weighting maps, outperforming conventional convolution and transformer models.
MomentaMorph: Unsupervised Spatial-Temporal Registration with Momenta, Shooting, and Correction
Aug 05, 2023



Tagged magnetic resonance imaging (tMRI) has been employed for decades to measure the motion of tissue undergoing deformation. However, registration-based motion estimation from tMRI is difficult due to the periodic patterns in these images, particularly when the motion is large. With a larger motion the registration approach gets trapped in a local optima, leading to motion estimation errors. We introduce a novel "momenta, shooting, and correction" framework for Lagrangian motion estimation in the presence of repetitive patterns and large motion. This framework, grounded in Lie algebra and Lie group principles, accumulates momenta in the tangent vector space and employs exponential mapping in the diffeomorphic space for rapid approximation towards true optima, circumventing local optima. A subsequent correction step ensures convergence to true optima. The results on a 2D synthetic dataset and a real 3D tMRI dataset demonstrate our method's efficiency in estimating accurate, dense, and diffeomorphic 2D/3D motion fields amidst large motion and repetitive patterns.