 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Speech-to-Video Synthesis Approach Using Spatio-Temporal Diffusion for Vocal Tract MRI
Mar 15, 2025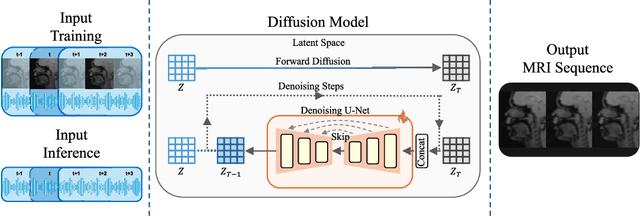
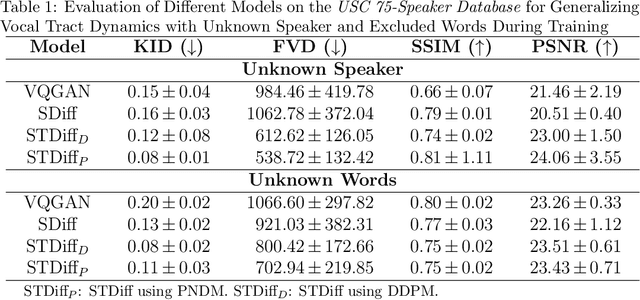
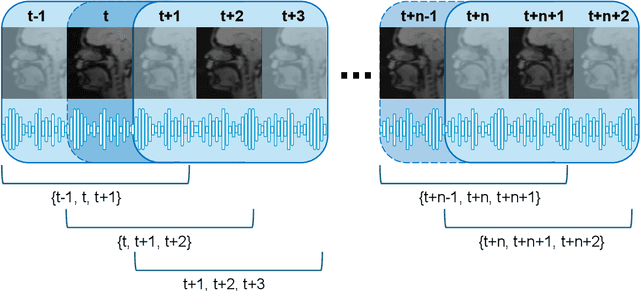

Understanding the relationship between vocal tract motion during speech and the resulting acoustic signal is crucial for aided clinical assessment and developing personalized treatment and rehabilitation strategies. Toward this goal, we introduce an audio-to-video generation framework for creating Real Time/cine-Magnetic Resonance Imaging (RT-/cine-MRI) visuals of the vocal tract from speech signals. Our framework first preprocesses RT-/cine-MRI sequences and speech samples to achieve temporal alignment, ensuring synchronization between visual and audio data. We then employ a modified stable diffusion model, integrating structural and temporal blocks, to effectively capture movement characteristics and temporal dynamics in the synchronized data. This process enables the generation of MRI sequences from new speech inputs, improving the conversion of audio into visual data. We evaluated our framework on healthy controls and tongue cancer patients by analyzing and comparing the vocal tract movements in synthesized videos. Our framework demonstrated adaptability to new speech inputs and effective generalization. In addition, positive human evaluations confirmed its effectiveness, with realistic and accurate visualizations, suggesting its potential for outpatient therapy and personalized simulation of vocal tract visualizations.
Speech motion anomaly detection via cross-modal translation of 4D motion fields from tagged MRI
Feb 10, 2024Understanding the relationship between tongue motion patterns during speech and their resulting speech acoustic outcomes -- i.e., articulatory-acoustic relation -- is of great importance in assessing speech quality and developing innovative treatment and rehabilitative strategies. This is especially important when evaluating and detecting abnormal articulatory features in patients with speech-related disorders. In this work, we aim to develop a framework for detecting speech motion anomalies in conjunction with their corresponding speech acoustics. This is achieved through the use of a deep cross-modal translator trained on data from healthy individuals only, which bridges the gap between 4D motion fields obtained from tagged MRI and 2D spectrograms derived from speech acoustic data. The trained translator is used as an anomaly detector, by measuring the spectrogram reconstruction quality on healthy individuals or patients. In particular, the cross-modal translator is likely to yield limited generalization capabilities on patient data, which includes unseen out-of-distribution patterns and demonstrates subpar performance, when compared with healthy individuals.~A one-class SVM is then used to distinguish the spectrograms of healthy individuals from those of patients. To validate our framework, we collected a total of 39 paired tagged MRI and speech waveforms, consisting of data from 36 healthy individuals and 3 tongue cancer patients. We used both 3D convolutional and transformer-based deep translation models, training them on the healthy training set and then applying them to both the healthy and patient testing sets. Our framework demonstrates a capability to detect abnormal patient data, thereby illustrating its potential in enhancing the understanding of the articulatory-acoustic relation for both healthy individuals and patients.
Speech Audio Synthesis from Tagged MRI and Non-Negative Matrix Factorization via Plastic Transformer
Sep 26, 2023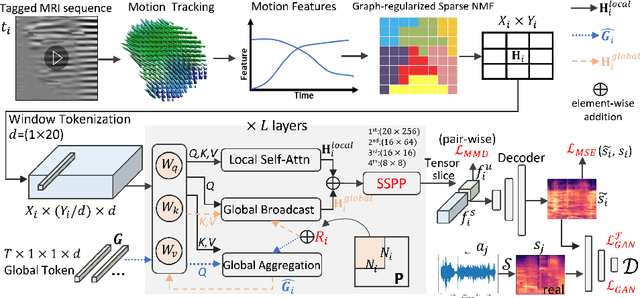
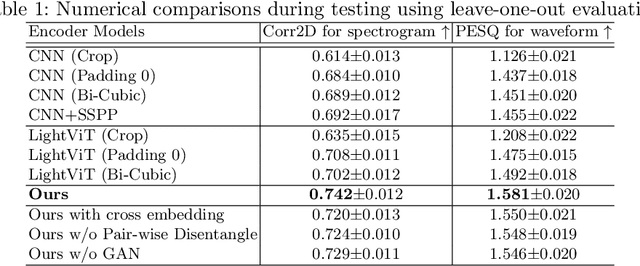
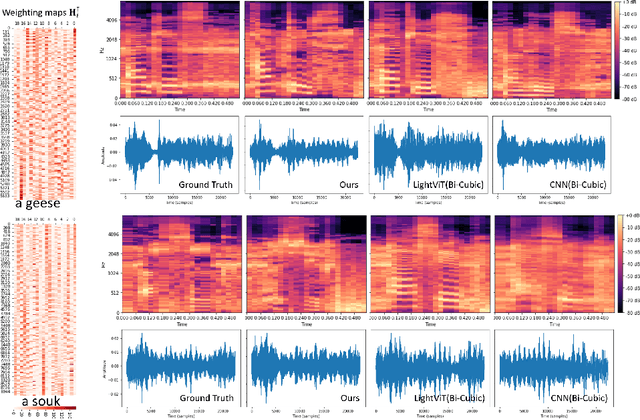
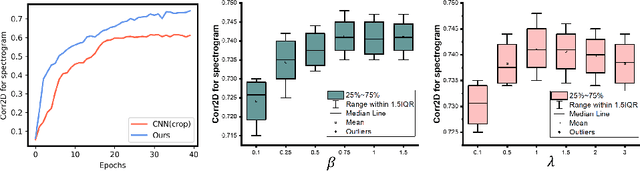
The tongue's intricate 3D structure, comprising localized functional units, plays a crucial role in the production of speech. When measured using tagged MRI, these functional units exhibit cohesive displacements and derived quantities that facilitate the complex process of speech production. Non-negative matrix factorization-based approaches have been shown to estimate the functional units through motion features, yielding a set of building blocks and a corresponding weighting map. Investigating the link between weighting maps and speech acoustics can offer significant insights into the intricate process of speech production. To this end, in this work, we utilize two-dimensional spectrograms as a proxy representation, and develop an end-to-end deep learning framework for translating weighting maps to their corresponding audio waveforms. Our proposed plastic light transformer (PLT) framework is based on directional product relative position bias and single-level spatial pyramid pooling, thus enabling flexible processing of weighting maps with variable size to fixed-size spectrograms, without input information loss or dimension expansion. Additionally, our PLT framework efficiently models the global correlation of wide matrix input. To improve the realism of our generated spectrograms with relatively limited training samples, we apply pair-wise utterance consistency with Maximum Mean Discrepancy constraint and adversarial training. Experimental results on a dataset of 29 subjects speaking two utterances demonstrated that our framework is able to synthesize speech audio waveforms from weighting maps, outperforming conventional convolution and transformer models.
Attentive Continuous Generative Self-training for Unsupervised Domain Adaptive Medical Image Translation
May 23, 2023
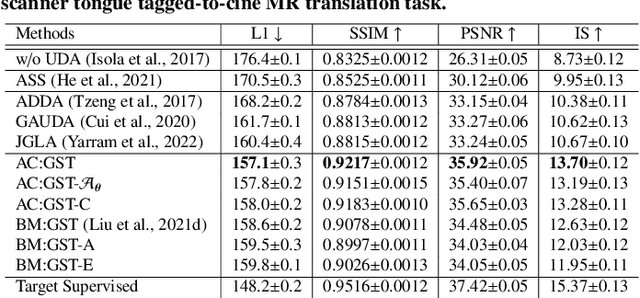
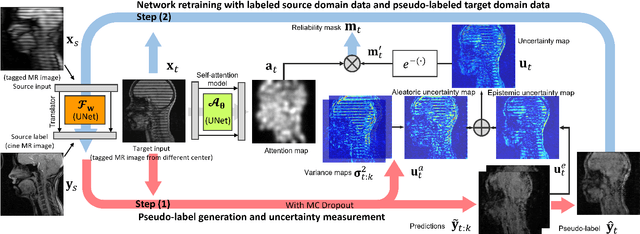
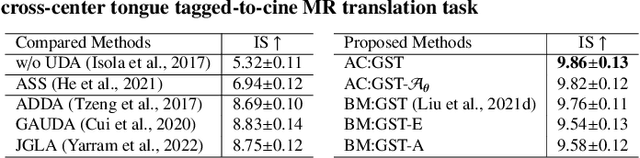
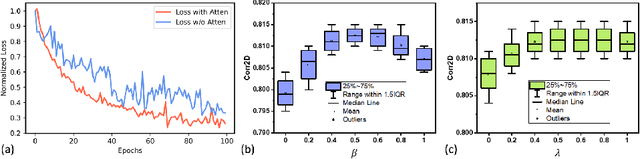
Self-training is an important class of unsupervised domain adaptation (UDA) approaches that are used to mitigate the problem of domain shift, when applying knowledge learned from a labeled source domain to unlabeled and heterogeneous target domains. While self-training-based UDA has shown considerable promise on discriminative tasks, including classification and segmentation, through reliable pseudo-label filtering based on the maximum softmax probability, there is a paucity of prior work on self-training-based UDA for generative tasks, including image modality translation. To fill this gap, in this work, we seek to develop a generative self-training (GST) framework for domain adaptive image translation with continuous value prediction and regression objectives. Specifically, we quantify both aleatoric and epistemic uncertainties within our GST using variational Bayes learning to measure the reliability of synthesized data. We also introduce a self-attention scheme that de-emphasizes the background region to prevent it from dominating the training process. The adaptation is then carried out by an alternating optimization scheme with target domain supervision that focuses attention on the regions with reliable pseudo-labels. We evaluated our framework on two cross-scanner/center, inter-subject translation tasks, including tagged-to-cine magnetic resonance (MR) image translation and T1-weighted MR-to-fractional anisotropy translation. Extensive validations with unpaired target domain data showed that our GST yielded superior synthesis performance in comparison to adversarial training UDA methods.
Synthesizing audio from tongue motion during speech using tagged MRI via transformer
Feb 14, 2023Investigating the relationship between internal tissue point motion of the tongue and oropharyngeal muscle deformation measured from tagged MRI and intelligible speech can aid in advancing speech motor control theories and developing novel treatment methods for speech related-disorders. However, elucidating the relationship between these two sources of information is challenging, due in part to the disparity in data structure between spatiotemporal motion fields (i.e., 4D motion fields) and one-dimensional audio waveforms. In this work, we present an efficient encoder-decoder translation network for exploring the predictive information inherent in 4D motion fields via 2D spectrograms as a surrogate of the audio data. Specifically, our encoder is based on 3D convolutional spatial modeling and transformer-based temporal modeling. The extracted features are processed by an asymmetric 2D convolution decoder to generate spectrograms that correspond to 4D motion fields. Furthermore, we incorporate a generative adversarial training approach into our framework to further improve synthesis quality on our generated spectrograms. We experiment on 63 paired motion field sequences and speech waveforms, demonstrating that our framework enables the generation of clear audio waveforms from a sequence of motion fields. Thus, our framework has the potential to improve our understanding of the relationship between these two modalities and inform the development of treatments for speech disorders.
New starting point registration method for tagged MRI tongue motion estimation
Feb 08, 2023Accurate tongue motion estimation is essential for tongue function evaluation. The harmonic phase processing (HARP) method and the phase vector incompressible registration algorithm (PVIRA) based on HARP can generate motion estimates from tagged MRI images, but they suffer from tag jumping due to large motions. This paper proposes a new registration method by combining the stationary velocity fields produced by PVIRA between successive time frames as a new initialization of the final registration stage to avoid tag jumping. The experiment results demonstrate the proposed method can avoid tag jumping and outperform the existing methods on tongue motion estimates.
Tagged-MRI Sequence to Audio Synthesis via Self Residual Attention Guided Heterogeneous Translator
Jun 09, 2022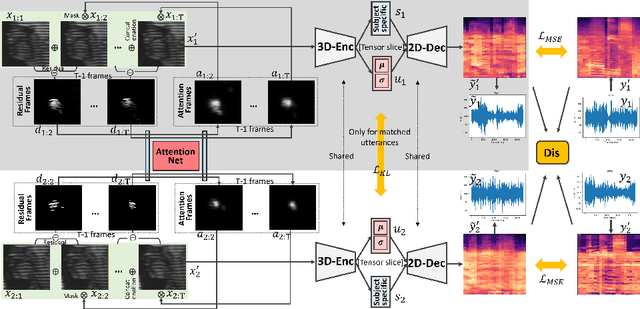
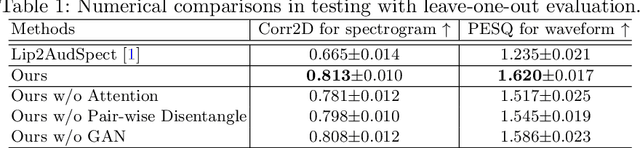
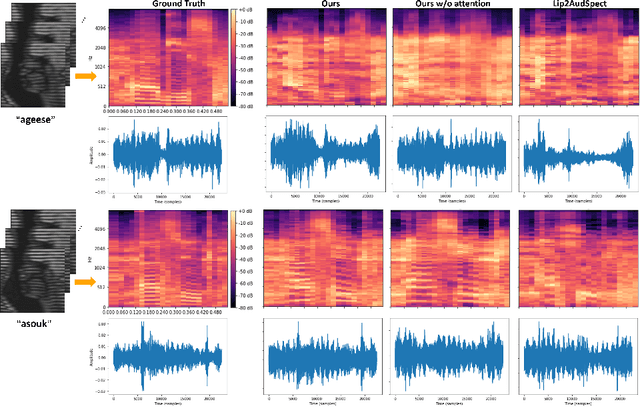
Understanding the underlying relationship between tongue and oropharyngeal muscle deformation seen in tagged-MRI and intelligible speech plays an important role in advancing speech motor control theories and treatment of speech related-disorders. Because of their heterogeneous representations, however, direct mapping between the two modalities -- i.e., two-dimensional (mid-sagittal slice) plus time tagged-MRI sequence and its corresponding one-dimensional waveform -- is not straightforward. Instead, we resort to two-dimensional spectrograms as an intermediate representation, which contains both pitch and resonance, from which to develop an end-to-end deep learning framework to translate from a sequence of tagged-MRI to its corresponding audio waveform with limited dataset size.~Our framework is based on a novel fully convolutional asymmetry translator with guidance of a self residual attention strategy to specifically exploit the moving muscular structures during speech.~In addition, we leverage a pairwise correlation of the samples with the same utterances with a latent space representation disentanglement strategy.~Furthermore, we incorporate an adversarial training approach with generative adversarial networks to offer improved realism on our generated spectrograms.~Our experimental results, carried out with a total of 63 tagged-MRI sequences alongside speech acoustics, showed that our framework enabled the generation of clear audio waveforms from a sequence of tagged-MRI, surpassing competing methods. Thus, our framework provides the great potential to help better understand the relationship between the two modalities.
Structure-aware Unsupervised Tagged-to-Cine MRI Synthesis with Self Disentanglement
Feb 25, 2022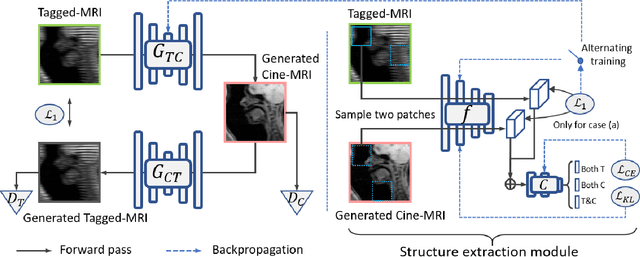

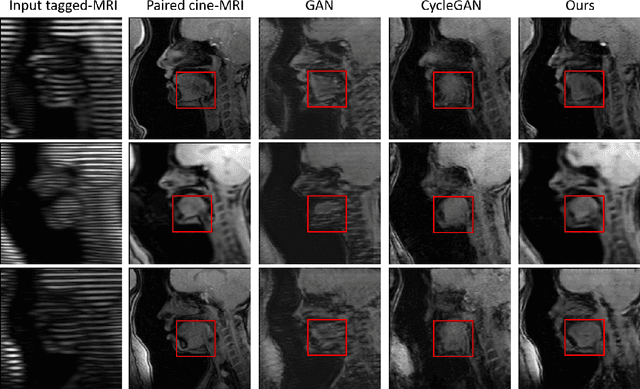
Cycle reconstruction regularized adversarial training -- e.g., CycleGAN, DiscoGAN, and DualGAN -- has been widely used for image style transfer with unpaired training data. Several recent works, however, have shown that local distortions are frequent, and structural consistency cannot be guaranteed. Targeting this issue, prior works usually relied on additional segmentation or consistent feature extraction steps that are task-specific. To counter this, this work aims to learn a general add-on structural feature extractor, by explicitly enforcing the structural alignment between an input and its synthesized image. Specifically, we propose a novel input-output image patches self-training scheme to achieve a disentanglement of underlying anatomical structures and imaging modalities. The translator and structure encoder are updated, following an alternating training protocol. In addition, the information w.r.t. imaging modality can be eliminated with an asymmetric adversarial game. We train, validate, and test our network on 1,768, 416, and 1,560 unpaired subject-independent slices of tagged and cine magnetic resonance imaging from a total of twenty healthy subjects, respectively, demonstrating superior performance over competing methods.
Generative Self-training for Cross-domain Unsupervised Tagged-to-Cine MRI Synthesis
Jun 23, 2021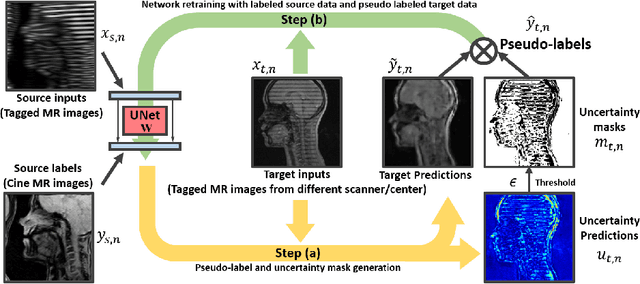
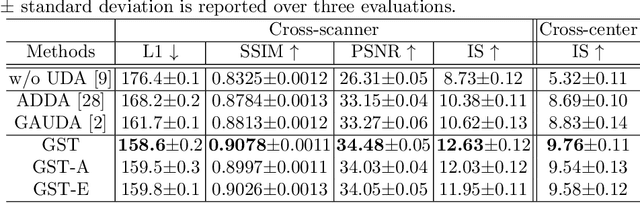
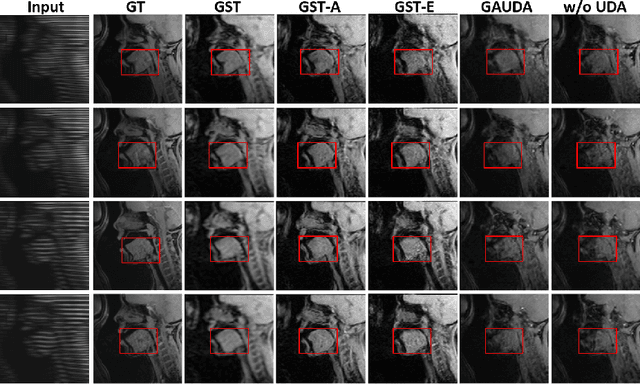
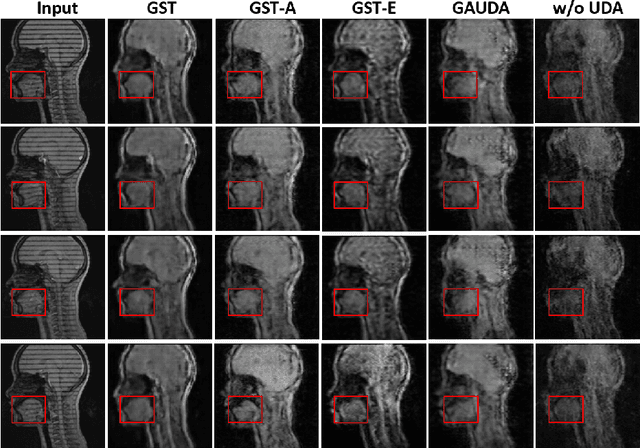
Self-training based unsupervised domain adaptation (UDA) has shown great potential to address the problem of domain shift, when applying a trained deep learning model in a source domain to unlabeled target domains. However, while the self-training UDA has demonstrated its effectiveness on discriminative tasks, such as classification and segmentation, via the reliable pseudo-label selection based on the softmax discrete histogram, the self-training UDA for generative tasks, such as image synthesis, is not fully investigated. In this work, we propose a novel generative self-training (GST) UDA framework with continuous value prediction and regression objective for cross-domain image synthesis. Specifically, we propose to filter the pseudo-label with an uncertainty mask, and quantify the predictive confidence of generated images with practical variational Bayes learning. The fast test-time adaptation is achieved by a round-based alternative optimization scheme. We validated our framework on the tagged-to-cine magnetic resonance imaging (MRI) synthesis problem, where datasets in the source and target domains were acquired from different scanners or centers. Extensive validations were carried out to verify our framework against popular adversarial training UDA methods. Results show that our GST, with tagged MRI of test subjects in new target domains, improved the synthesis quality by a large margin, compared with the adversarial training UDA methods.
Dual-cycle Constrained Bijective VAE-GAN For Tagged-to-Cine Magnetic Resonance Image Synthesis
Jan 14, 2021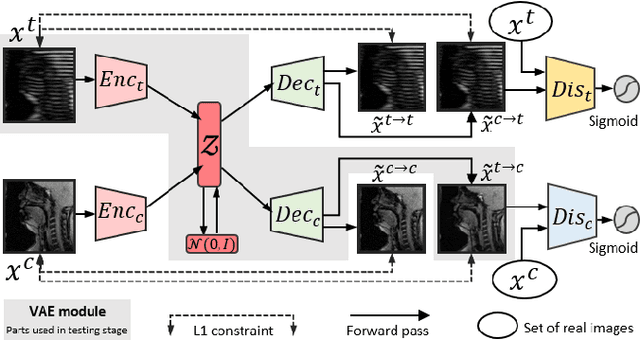
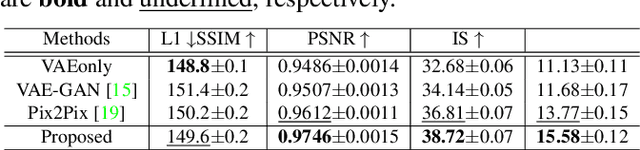
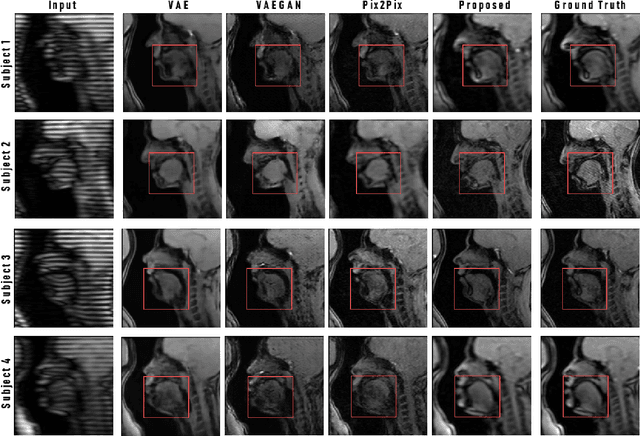
Tagged magnetic resonance imaging (MRI) is a widely used imaging technique for measuring tissue deformation in moving organs. Due to tagged MRI's intrinsic low anatomical resolution, another matching set of cine MRI with higher resolution is sometimes acquired in the same scanning session to facilitate tissue segmentation, thus adding extra time and cost. To mitigate this, in this work, we propose a novel dual-cycle constrained bijective VAE-GAN approach to carry out tagged-to-cine MR image synthesis. Our method is based on a variational autoencoder backbone with cycle reconstruction constrained adversarial training to yield accurate and realistic cine MR images given tagged MR images. Our framework has been trained, validated, and tested using 1,768, 416, and 1,560 subject-independent paired slices of tagged and cine MRI from twenty healthy subjects, respectively, demonstrating superior performance over the comparison methods. Our method can potentially be used to reduce the extra acquisition time and cost, while maintaining the same workflow for further motion analyses.