 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagged-MRI Sequence to Audio Synthesis via Self Residual Attention Guided Heterogeneous Translator
Paper and Code
Jun 09, 2022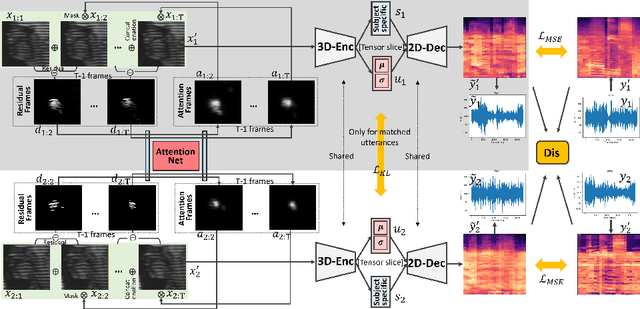
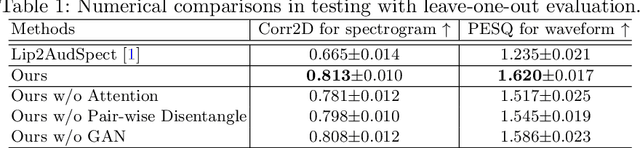
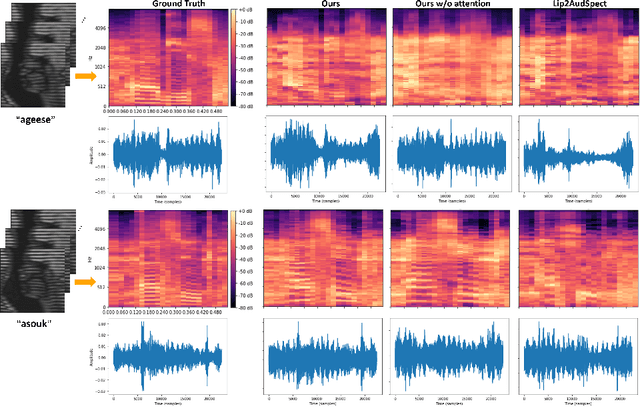
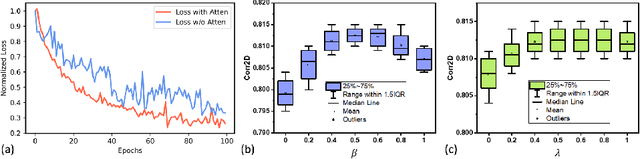
Understanding the underlying relationship between tongue and oropharyngeal muscle deformation seen in tagged-MRI and intelligible speech plays an important role in advancing speech motor control theories and treatment of speech related-disorders. Because of their heterogeneous representations, however, direct mapping between the two modalities -- i.e., two-dimensional (mid-sagittal slice) plus time tagged-MRI sequence and its corresponding one-dimensional waveform -- is not straightforward. Instead, we resort to two-dimensional spectrograms as an intermediate representation, which contains both pitch and resonance, from which to develop an end-to-end deep learning framework to translate from a sequence of tagged-MRI to its corresponding audio waveform with limited dataset size.~Our framework is based on a novel fully convolutional asymmetry translator with guidance of a self residual attention strategy to specifically exploit the moving muscular structures during speech.~In addition, we leverage a pairwise correlation of the samples with the same utterances with a latent space representation disentanglement strategy.~Furthermore, we incorporate an adversarial training approach with generative adversarial networks to offer improved realism on our generated spectrograms.~Our experimental results, carried out with a total of 63 tagged-MRI sequences alongside speech acoustics, showed that our framework enabled the generation of clear audio waveforms from a sequence of tagged-MRI, surpassing competing methods. Thus, our framework provides the great potential to help better understand the relationship between the two modalities.