 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOsteoFlow: Lyapunov-Guided Flow Distillation for Predicting Bone Remodeling after Mandibular Reconstruction
Mar 23, 2026Predicting long-term bone remodeling after mandibular reconstruction would be of great clinical benefit, yet standard generative models struggle to maintain trajectory-level consistency and anatomical fidelity over long horizons. We introduce OsteoFlow, a flow-based framework predicting Year-1 post-operative CT scans from Day-5 scans. Our core contribution is Lyapunov-guided trajectory distillation: Unlike one-step distillation, our method distills a continuous trajectory over transport time from a registration-derived stationary velocity field teacher. Combined with a resection-aware image loss, this enforces geometric correspondence without sacrificing generative capacity. Evaluated on 344 paired regions of interest, OsteoFlow significantly outperforms state of-the-art baselines, reducing mean absolute error in the surgical resection zone by ~20%. This highlights the promise of trajectory distillation for long-term prediction. Code is available on GitHub: OsteoFlow.
Integrating Posture Control in Speech Motor Models: A Parallel-Structured Simulation Approach
Jul 26, 2024


Posture is an essential aspect of motor behavior, necessitating continuous muscle activation to counteract gravity. It remains stable under perturbation, aiding in maintaining bodily balance and enabling movement execution. Similarities have been observed between gross body postures and speech postures, such as those involving the jaw, tongue, and lips, which also exhibit resilience to perturbations and assist in equilibrium and movement. Although postural control is a recognized element of human movement and balance, particularly in broader motor skills, it has not been adequately incorporated into existing speech motor control models, which typically concentrate on the gestures or motor commands associated with specific speech movements, overlooking the influence of postural control and gravity. Here we introduce a model that aligns speech posture and movement, using simulations to explore whether speech posture within this framework mirrors the principles of bodily postural control. Our findings indicate that, akin to body posture, speech posture is also robust to perturbation and plays a significant role in maintaining local segment balance and enhancing speech production.
Speech Audio Synthesis from Tagged MRI and Non-Negative Matrix Factorization via Plastic Transformer
Sep 26, 2023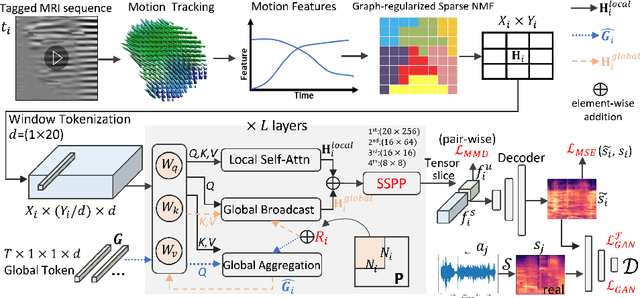
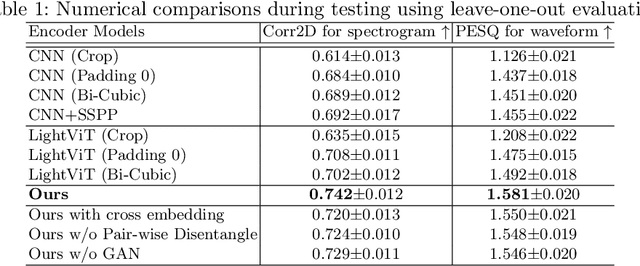
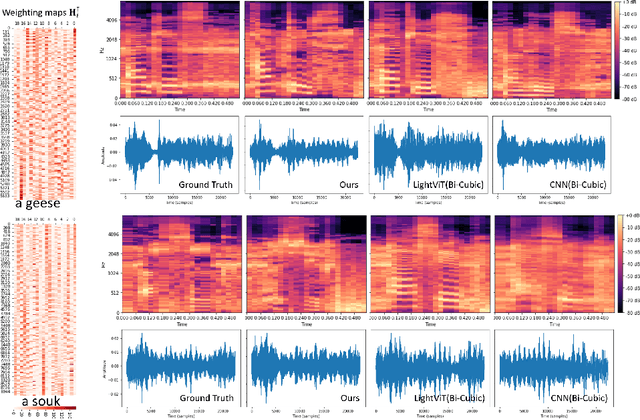
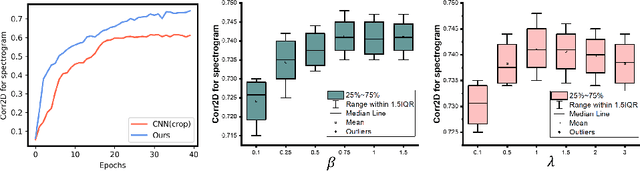
The tongue's intricate 3D structure, comprising localized functional units, plays a crucial role in the production of speech. When measured using tagged MRI, these functional units exhibit cohesive displacements and derived quantities that facilitate the complex process of speech production. Non-negative matrix factorization-based approaches have been shown to estimate the functional units through motion features, yielding a set of building blocks and a corresponding weighting map. Investigating the link between weighting maps and speech acoustics can offer significant insights into the intricate process of speech production. To this end, in this work, we utilize two-dimensional spectrograms as a proxy representation, and develop an end-to-end deep learning framework for translating weighting maps to their corresponding audio waveforms. Our proposed plastic light transformer (PLT) framework is based on directional product relative position bias and single-level spatial pyramid pooling, thus enabling flexible processing of weighting maps with variable size to fixed-size spectrograms, without input information loss or dimension expansion. Additionally, our PLT framework efficiently models the global correlation of wide matrix input. To improve the realism of our generated spectrograms with relatively limited training samples, we apply pair-wise utterance consistency with Maximum Mean Discrepancy constraint and adversarial training. Experimental results on a dataset of 29 subjects speaking two utterances demonstrated that our framework is able to synthesize speech audio waveforms from weighting maps, outperforming conventional convolution and transformer models.
A comparative study of two-dimensional vocal tract acoustic modeling based on Finite-Difference Time-Domain methods
Feb 09, 2021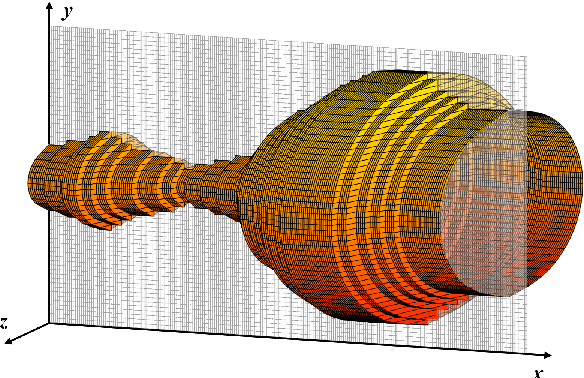
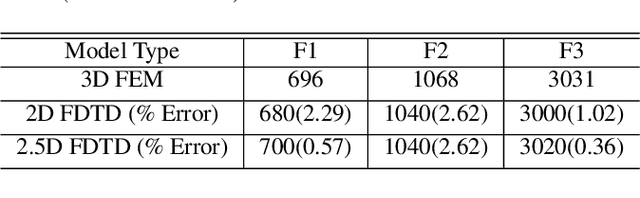
The two-dimensional (2D) numerical approaches for vocal tract (VT) modelling can afford a better balance between the low computational cost and accurate rendering of acoustic wave propagation. However, they require a high spatio-temporal resolution in the numerical scheme for a precise estimation of acoustic formants at the simulation run-time expense. We have recently proposed a new VT acoustic modelling technique, known as the 2.5D Finite-Difference Time-Domain (2.5D FDTD), which extends the existing 2D FDTD approach by adding tube depth to its acoustic wave solver. In this work, first, the simulated acoustic outputs of our new model are shown to be comparable with the 2D FDTD and a realistic 3D FEM VT model at a low spatio-temporal resolution. Next, a radiation model is developed by including a circular baffle around the VT as head geometry. The transfer functions of the radiation model are analyzed using five different vocal tract shapes for vowel sounds /a/, /e/, /i/, /o/ and /u/.
SPEAK WITH YOUR HANDS Using Continuous Hand Gestures to control Articulatory Speech Synthesizer
Feb 02, 2021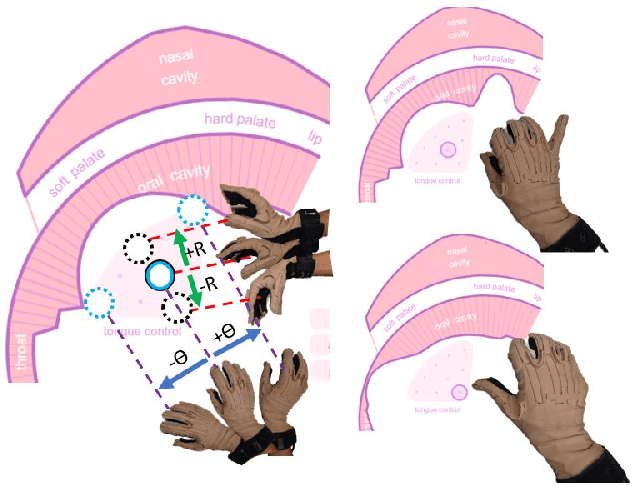
This work presents our advancements in controlling an articulatory speech synthesis engine, \textit{viz.}, Pink Trombone, with hand gestures. Our interface translates continuous finger movements and wrist flexion into continuous speech using vocal tract area-function based articulatory speech synthesis. We use Cyberglove II with 18 sensors to capture the kinematic information of the wrist and the individual fingers, in order to control a virtual tongue. The coordinates and the bending values of the sensors are then utilized to fit a spline tongue model that smoothens out the noisy values and outliers. Considering the upper palate as fixed and the spline model as the dynamically moving lower surface (tongue) of the vocal tract, we compute 1D area functional values that are fed to the Pink Trombone, generating continuous speech sounds. Therefore, by learning to manipulate one's wrist and fingers, one can learn to produce speech sounds just through one's hands, without the need for using the vocal tract.
Ultra2Speech -- A Deep Learning Framework for Formant Frequency Estimation and Tracking from Ultrasound Tongue Images
Jun 29, 2020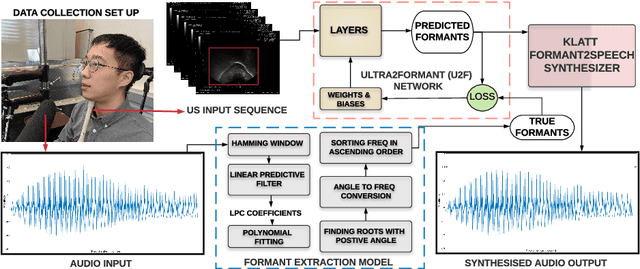
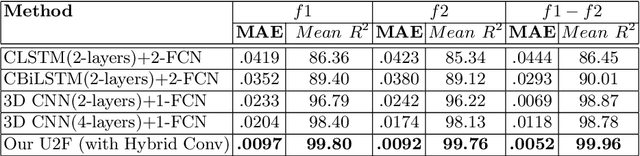
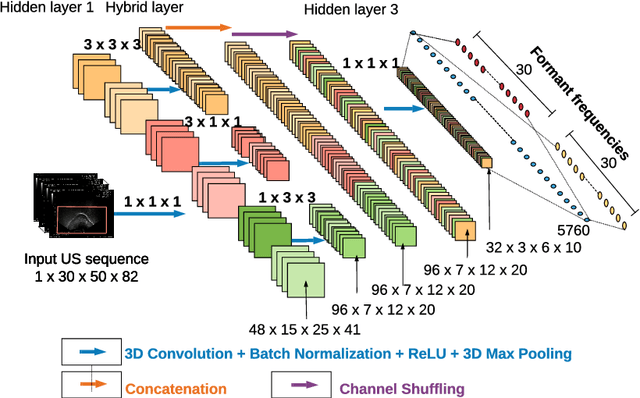
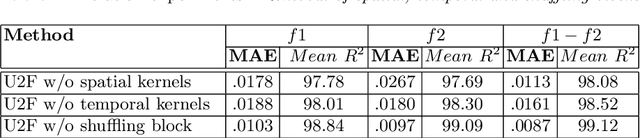
Thousands of individuals need surgical removal of their larynx due to critical diseases every year and therefore, require an alternative form of communication to articulate speech sounds after the loss of their voice box. This work addresses the articulatory-to-acoustic mapping problem based on ultrasound (US) tongue images for the development of a silent-speech interface (SSI) that can provide them with an assistance in their daily interactions. Our approach targets automatically extracting tongue movement information by selecting an optimal feature set from US images and mapping these features to the acoustic space. We use a novel deep learning architecture to map US tongue images from the US probe placed beneath a subject's chin to formants that we call, Ultrasound2Formant (U2F) Net. It uses hybrid spatio-temporal 3D convolutions followed by feature shuffling, for the estimation and tracking of vowel formants from US images. The formant values are then utilized to synthesize continuous time-varying vowel trajectories, via Klatt Synthesizer. Our best model achieves R-squared (R^2) measure of 99.96% for the regression task. Our network lays the foundation for an SSI as it successfully tracks the tongue contour automatically as an internal representation without any explicit annotation.
Learning Joint Articulatory-Acoustic Representations with Normalizing Flows
May 16, 2020
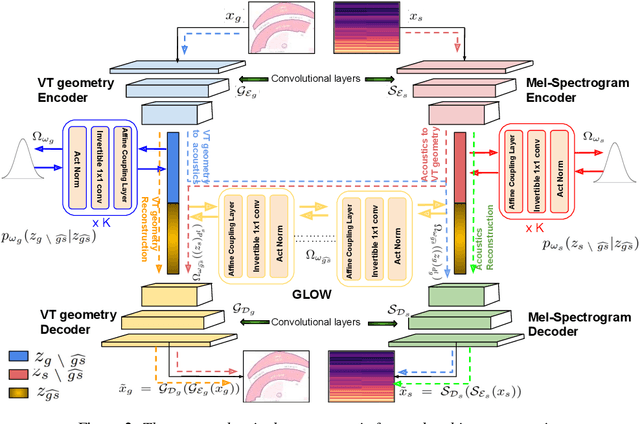


The articulatory geometric configurations of the vocal tract and the acoustic properties of the resultant speech sound are considered to have a strong causal relationship. This paper aims at finding a joint latent representation between the articulatory and acoustic domain for vowel sounds via invertible neural network models, while simultaneously preserving the respective domain-specific features. Our model utilizes a convolutional autoencoder architecture and normalizing flow-based models to allow both forward and inverse mappings in a semi-supervised manner, between the mid-sagittal vocal tract geometry of a two degrees-of-freedom articulatory synthesizer with 1D acoustic wave model and the Mel-spectrogram representation of the synthesized speech sounds. Our approach achieves satisfactory performance in achieving both articulatory-to-acoustic as well as acoustic-to-articulatory mapping, thereby demonstrating our success in achieving a joint encoding of both the domains.
Variational Learning with Disentanglement-PyTorch
Dec 11, 2019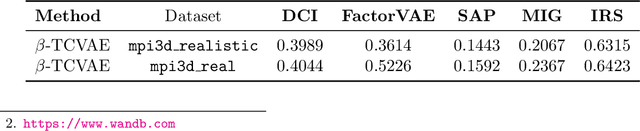

Unsupervised learning of disentangled representations is an open problem in machine learning. The Disentanglement-PyTorch library is developed to facilitate research, implementation, and testing of new variational algorithms. In this modular library, neural architectures, dimensionality of the latent space, and the training algorithms are fully decoupled, allowing for independent and consistent experiments across variational methods. The library handles the training scheduling, logging, and visualizations of reconstructions and latent space traversals. It also evaluates the encodings based on various disentanglement metrics. The library, so far, includes implementations of the following unsupervised algorithms VAE, Beta-VAE, Factor-VAE, DIP-I-VAE, DIP-II-VAE, Info-VAE, and Beta-TCVAE, as well as conditional approaches such as CVAE and IFCVAE. The library is compatible with the Disentanglement Challenge of NeurIPS 2019, hosted on AICrowd, and achieved the 3rd rank in both the first and second stages of the challenge.
A Study into Echocardiography View Conversion
Dec 05, 2019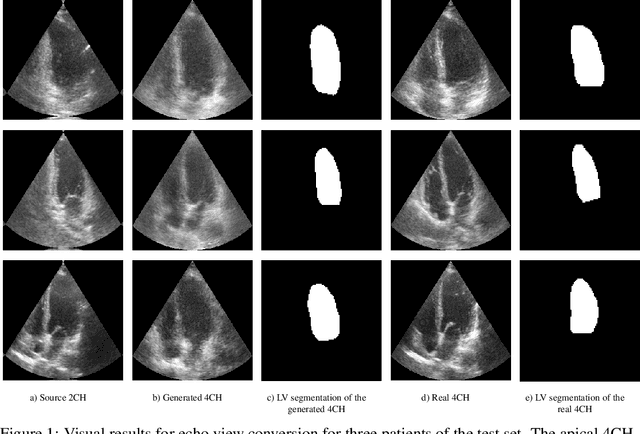
Transthoracic echo is one of the most common means of cardiac studies in the clinical routines. During the echo exam, the sonographer captures a set of standard cross sections (echo views) of the heart. Each 2D echo view cuts through the 3D cardiac geometry via a unique plane. Consequently, different views share some limited information. In this work, we investigate the feasibility of generating a 2D echo view using another view based on adversarial generative models. The objective optimized to train the view-conversion model is based on the ideas introduced by LSGAN, PatchGAN and Conditional GAN (cGAN). The size and length of the left ventricle in the generated target echo view is compared against that of the target ground-truth to assess the validity of the echo view conversion. Results show that there is a correlation of 0.50 between the LV areas and 0.49 between the LV lengths of the generated target frames and the real target frames.
A Preliminary Study of Disentanglement With Insights on the Inadequacy of Metrics
Nov 26, 2019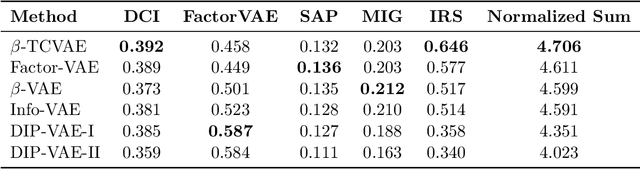
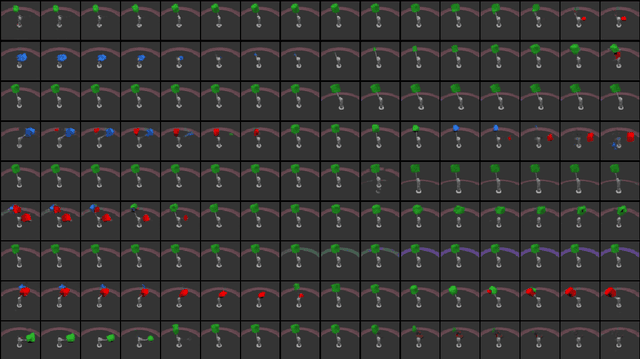

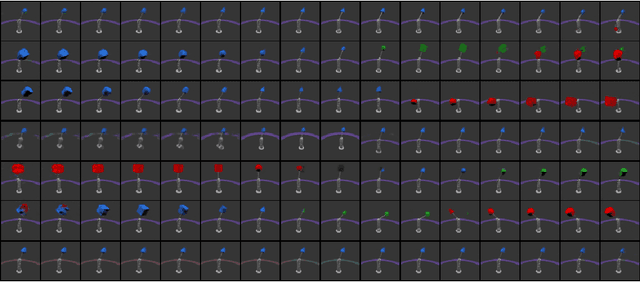
Disentangled encoding is an important step towards a better representation learning. However, despite the numerous efforts, there still is no clear winner that captures the independent features of the data in an unsupervised fashion. In this work we empirically evaluate the performance of six unsupervised disentanglement approaches on the mpi3d toy dataset curated and released for the NeurIPS 2019 Disentanglement Challenge. The methods investigated in this work are Beta-VAE, Factor-VAE, DIP-I-VAE, DIP-II-VAE, Info-VAE, and Beta-TCVAE. The capacities of all models were progressively increased throughout the training and the hyper-parameters were kept intact across experiments. The methods were evaluated based on five disentanglement metrics, namely, DCI, Factor-VAE, IRS, MIG, and SAP-Score. Within the limitations of this study, the Beta-TCVAE approach was found to outperform its alternatives with respect to the normalized sum of metrics. However, a qualitative study of the encoded latents reveal that there is not a consistent correlation between the reported metrics and the disentanglement potential of the model.