 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparative study of two-dimensional vocal tract acoustic modeling based on Finite-Difference Time-Domain methods
Feb 09, 2021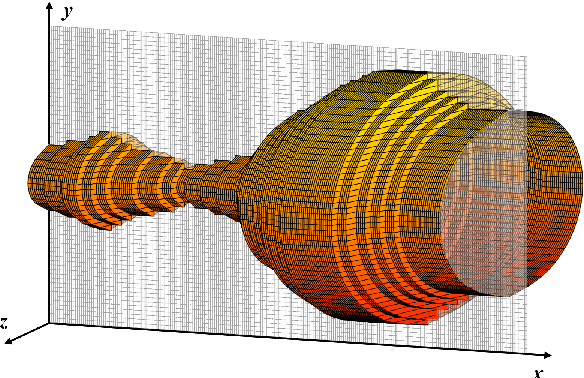
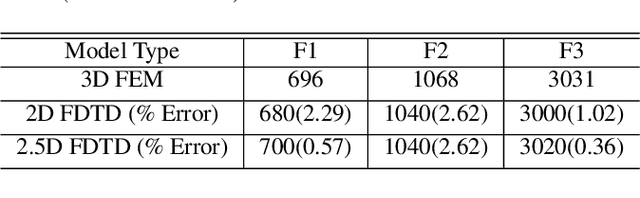
The two-dimensional (2D) numerical approaches for vocal tract (VT) modelling can afford a better balance between the low computational cost and accurate rendering of acoustic wave propagation. However, they require a high spatio-temporal resolution in the numerical scheme for a precise estimation of acoustic formants at the simulation run-time expense. We have recently proposed a new VT acoustic modelling technique, known as the 2.5D Finite-Difference Time-Domain (2.5D FDTD), which extends the existing 2D FDTD approach by adding tube depth to its acoustic wave solver. In this work, first, the simulated acoustic outputs of our new model are shown to be comparable with the 2D FDTD and a realistic 3D FEM VT model at a low spatio-temporal resolution. Next, a radiation model is developed by including a circular baffle around the VT as head geometry. The transfer functions of the radiation model are analyzed using five different vocal tract shapes for vowel sounds /a/, /e/, /i/, /o/ and /u/.
SPEAK WITH YOUR HANDS Using Continuous Hand Gestures to control Articulatory Speech Synthesizer
Feb 02, 2021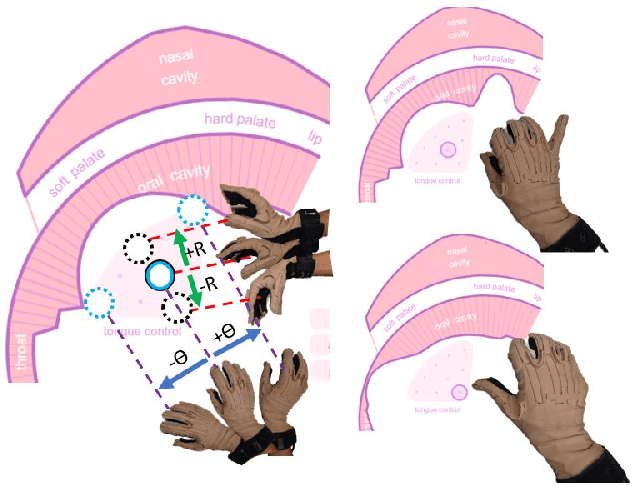
This work presents our advancements in controlling an articulatory speech synthesis engine, \textit{viz.}, Pink Trombone, with hand gestures. Our interface translates continuous finger movements and wrist flexion into continuous speech using vocal tract area-function based articulatory speech synthesis. We use Cyberglove II with 18 sensors to capture the kinematic information of the wrist and the individual fingers, in order to control a virtual tongue. The coordinates and the bending values of the sensors are then utilized to fit a spline tongue model that smoothens out the noisy values and outliers. Considering the upper palate as fixed and the spline model as the dynamically moving lower surface (tongue) of the vocal tract, we compute 1D area functional values that are fed to the Pink Trombone, generating continuous speech sounds. Therefore, by learning to manipulate one's wrist and fingers, one can learn to produce speech sounds just through one's hands, without the need for using the vocal tract.
Limitations of Source-Filter Coupling In Phonation
Nov 19, 2018

The coupling of vocal fold (source) and vocal tract (filter) is one of the most critical factors in source-filter articulation theory. The traditional linear source-filter theory has been challenged by current research which clearly shows the impact of acoustic loading on the dynamic behavior of the vocal fold vibration as well as the variations in the glottal flow pulses shape. This paper outlines the underlying mechanism of source-filter interactions; demonstrates the design and working principles of coupling for the various existing vocal cord and vocal tract biomechanical models. For our study, we have considered self-oscillating lumped-element models of the acoustic source and computational models of the vocal tract as articulators. To understand the limitations of source-filter interactions which are associated with each of those models, we compare them concerning their mechanical design, acoustic and physiological characteristics and aerodynamic simulation.