 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Deploying Learning-based Quadruped Loco-Manipulation
Dec 22, 2025Quadruped mobile manipulators offer strong potential for agile loco-manipulation but remain difficult to control and transfer reliably from simulation to reality. Reinforcement learning (RL) shows promise for whole-body control, yet most frameworks are proprietary and hard to reproduce on real hardware. We present an open pipeline for training, benchmarking, and deploying RL-based controllers on the Unitree B1 quadruped with a Z1 arm. The framework unifies sim-to-sim and sim-to-real transfer through ROS, re-implementing a policy trained in Isaac Gym, extending it to MuJoCo via a hardware abstraction layer, and deploying the same controller on physical hardware. Sim-to-sim experiments expose discrepancies between Isaac Gym and MuJoCo contact models that influence policy behavior, while real-world teleoperated object-picking trials show that coordinated whole-body control extends reach and improves manipulation over floating-base baselines. The pipeline provides a transparent, reproducible foundation for developing and analyzing RL-based loco-manipulation controllers and will be released open source to support future research.
Integrating Posture Control in Speech Motor Models: A Parallel-Structured Simulation Approach
Jul 26, 2024


Posture is an essential aspect of motor behavior, necessitating continuous muscle activation to counteract gravity. It remains stable under perturbation, aiding in maintaining bodily balance and enabling movement execution. Similarities have been observed between gross body postures and speech postures, such as those involving the jaw, tongue, and lips, which also exhibit resilience to perturbations and assist in equilibrium and movement. Although postural control is a recognized element of human movement and balance, particularly in broader motor skills, it has not been adequately incorporated into existing speech motor control models, which typically concentrate on the gestures or motor commands associated with specific speech movements, overlooking the influence of postural control and gravity. Here we introduce a model that aligns speech posture and movement, using simulations to explore whether speech posture within this framework mirrors the principles of bodily postural control. Our findings indicate that, akin to body posture, speech posture is also robust to perturbation and plays a significant role in maintaining local segment balance and enhancing speech production.
Bootstrapping meaning through listening: Unsupervised learning of spoken sentence embeddings
Oct 23, 2022Inducing semantic representations directly from speech signals is a highly challenging task but has many useful applications in speech mining and spoken language understanding. This study tackles the unsupervised learning of semantic representations for spoken utterances. Through converting speech signals into hidden units generated from acoustic unit discovery, we propose WavEmbed, a multimodal sequential autoencoder that predicts hidden units from a dense representation of speech. Secondly, we also propose S-HuBERT to induce meaning through knowledge distillation, in which a sentence embedding model is first trained on hidden units and passes its knowledge to a speech encoder through contrastive learning. The best performing model achieves a moderate correlation (0.5~0.6) with human judgments, without relying on any labels or transcriptions. Furthermore, these models can also be easily extended to leverage textual transcriptions of speech to learn much better speech embeddings that are strongly correlated with human annotations. Our proposed methods are applicable to the development of purely data-driven systems for speech mining, indexing and search.
Convolutional Neural Networks with A Topographic Representation Module for EEG-Based Brain-Computer Interfaces
Aug 30, 2022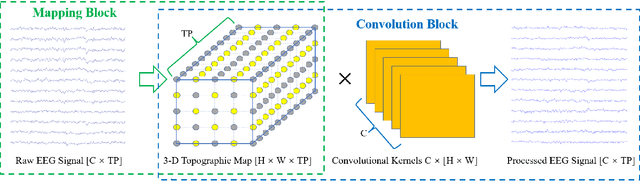
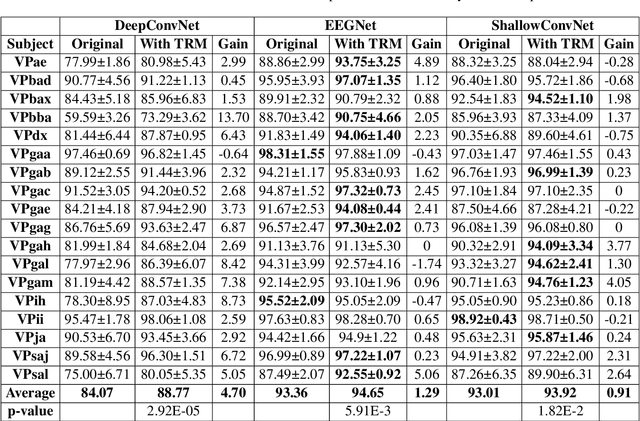
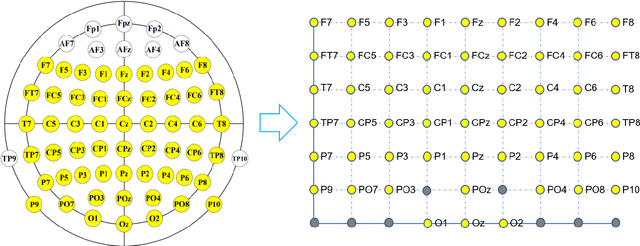
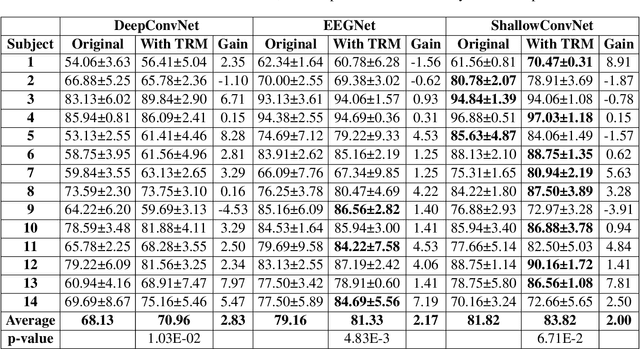
Objective: Convolutional Neural Networks (CNNs) have shown great potential in the field of Brain-Computer Interfaces (BCIs). The raw Electroencephalogram (EEG) signal is usually represented as 2-Dimensional (2-D) matrix composed of channels and time points, which ignores the spatial topological information. Our goal is to make the CNN with the raw EEG signal as input have the ability to learn EEG spatial topological features, and improve its performance while essentially maintaining its original structure. Methods:We propose an EEG Topographic Representation Module (TRM). This module consists of (1) a mapping block from the raw EEG signal to a 3-D topographic map and (2) a convolution block from the topographic map to an output of the same size as input. According to the size of the kernel used in the convolution block, we design 2 types of TRMs, namely TRM-(5,5) and TRM-(3,3). We embed the TRM into 3 widely used CNNs, and tested them on 2 publicly available datasets (Emergency Braking During Simulated Driving Dataset (EBDSDD), and High Gamma Dataset (HGD)). Results: The results show that the classification accuracies of all 3 CNNs are improved on both datasets after using the TRM. With TRM-(5,5), the average accuracies of DeepConvNet, EEGNet and ShallowConvNet are improved by 6.54%, 1.72% and 2.07% on EBDSDD, and by 6.05%, 3.02% and 5.14% on HGD, respectively; with TRM-(3,3), they are improved by 7.76%, 1.71% and 2.17% on EBDSDD, and by 7.61%, 5.06% and 6.28% on HGD, respectively. Significance: We improve the classification performance of 3 CNNs on 2 datasets by the use of TRM, indicating that it has the capability to mine the EEG spatial topological information. In addition, since the output of TRM has the same size as the input, CNNs with the raw EEG signal as input can use this module without changing their original structures.
Ultra2Speech -- A Deep Learning Framework for Formant Frequency Estimation and Tracking from Ultrasound Tongue Images
Jun 29, 2020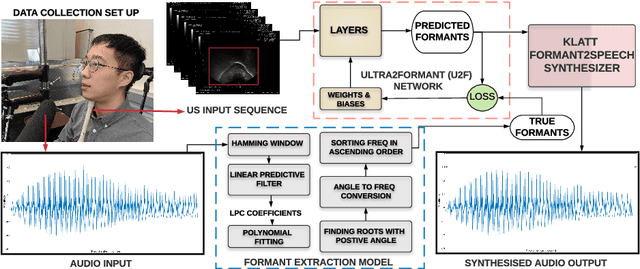
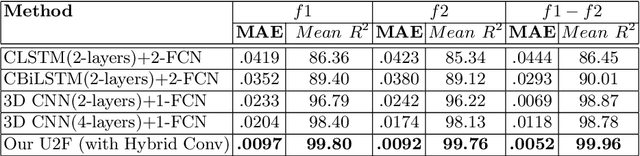
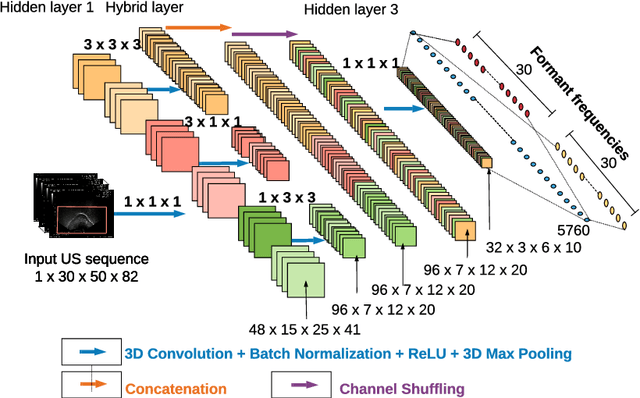
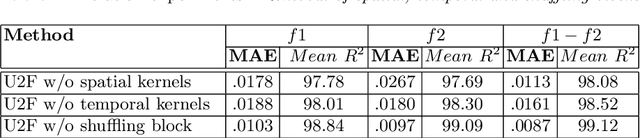
Thousands of individuals need surgical removal of their larynx due to critical diseases every year and therefore, require an alternative form of communication to articulate speech sounds after the loss of their voice box. This work addresses the articulatory-to-acoustic mapping problem based on ultrasound (US) tongue images for the development of a silent-speech interface (SSI) that can provide them with an assistance in their daily interactions. Our approach targets automatically extracting tongue movement information by selecting an optimal feature set from US images and mapping these features to the acoustic space. We use a novel deep learning architecture to map US tongue images from the US probe placed beneath a subject's chin to formants that we call, Ultrasound2Formant (U2F) Net. It uses hybrid spatio-temporal 3D convolutions followed by feature shuffling, for the estimation and tracking of vowel formants from US images. The formant values are then utilized to synthesize continuous time-varying vowel trajectories, via Klatt Synthesizer. Our best model achieves R-squared (R^2) measure of 99.96% for the regression task. Our network lays the foundation for an SSI as it successfully tracks the tongue contour automatically as an internal representation without any explicit annotation.