 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Posture Control in Speech Motor Models: A Parallel-Structured Simulation Approach
Jul 26, 2024


Posture is an essential aspect of motor behavior, necessitating continuous muscle activation to counteract gravity. It remains stable under perturbation, aiding in maintaining bodily balance and enabling movement execution. Similarities have been observed between gross body postures and speech postures, such as those involving the jaw, tongue, and lips, which also exhibit resilience to perturbations and assist in equilibrium and movement. Although postural control is a recognized element of human movement and balance, particularly in broader motor skills, it has not been adequately incorporated into existing speech motor control models, which typically concentrate on the gestures or motor commands associated with specific speech movements, overlooking the influence of postural control and gravity. Here we introduce a model that aligns speech posture and movement, using simulations to explore whether speech posture within this framework mirrors the principles of bodily postural control. Our findings indicate that, akin to body posture, speech posture is also robust to perturbation and plays a significant role in maintaining local segment balance and enhancing speech production.
Pruning Convolutional Filters using Batch Bridgeout
Sep 23, 2020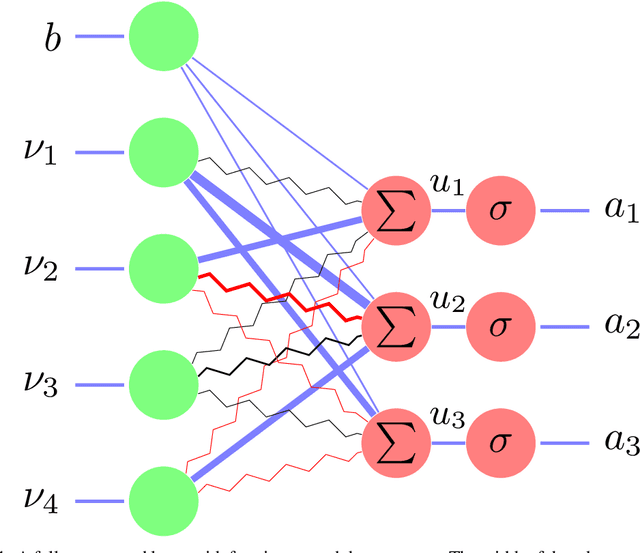


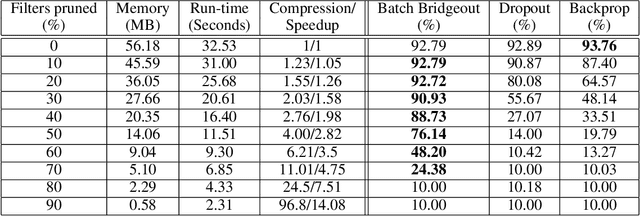
State-of-the-art computer vision models are rapidly increasing in capacity, where the number of parameters far exceeds the number required to fit the training set. This results in better optimization and generalization performance. However, the huge size of contemporary models results in large inference costs and limits their use on resource-limited devices. In order to reduce inference costs, convolutional filters in trained neural networks could be pruned to reduce the run-time memory and computational requirements during inference. However, severe post-training pruning results in degraded performance if the training algorithm results in dense weight vectors. We propose the use of Batch Bridgeout, a sparsity inducing stochastic regularization scheme, to train neural networks so that they could be pruned efficiently with minimal degradation in performance. We evaluate the proposed method on common computer vision models VGGNet, ResNet, and Wide-ResNet on the CIFAR image classification task. For all the networks, experimental results show that Batch Bridgeout trained networks achieve higher accuracy across a wide range of pruning intensities compared to Dropout and weight decay regularization.
Sparseout: Controlling Sparsity in Deep Networks
Apr 17, 2019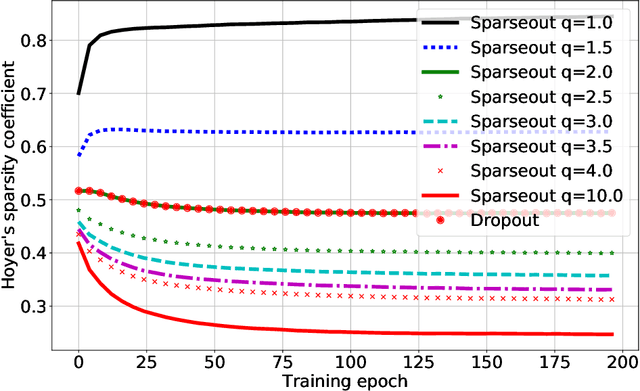

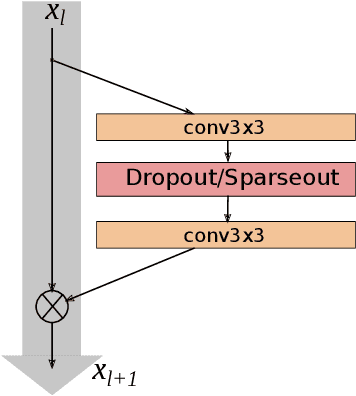
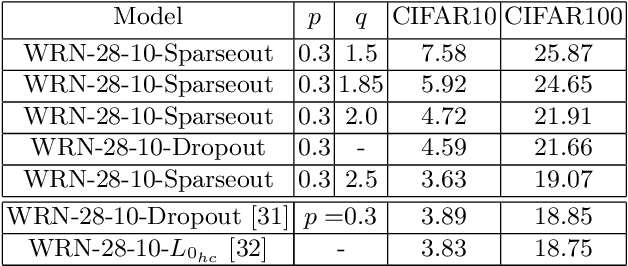
Dropout is commonly used to help reduce overfitting in deep neural networks. Sparsity is a potentially important property of neural networks, but is not explicitly controlled by Dropout-based regularization. In this work, we propose Sparseout a simple and efficient variant of Dropout that can be used to control the sparsity of the activations in a neural network. We theoretically prove that Sparseout is equivalent to an $L_q$ penalty on the features of a generalized linear model and that Dropout is a special case of Sparseout for neural networks. We empirically demonstrate that Sparseout is computationally inexpensive and is able to control the desired level of sparsity in the activations. We evaluated Sparseout on image classification and language modelling tasks to see the effect of sparsity on these tasks. We found that sparsity of the activations is favorable for language modelling performance while image classification benefits from denser activations. Sparseout provides a way to investigate sparsity in state-of-the-art deep learning models. Source code for Sparseout could be found at \url{https://github.com/najeebkhan/sparseout}.
A parallel implementation of the covariance matrix adaptation evolution strategy
May 28, 2018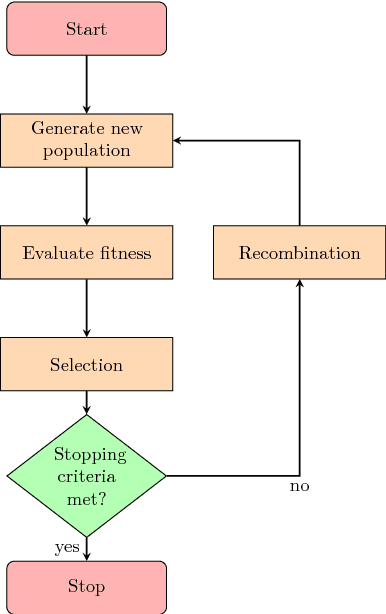
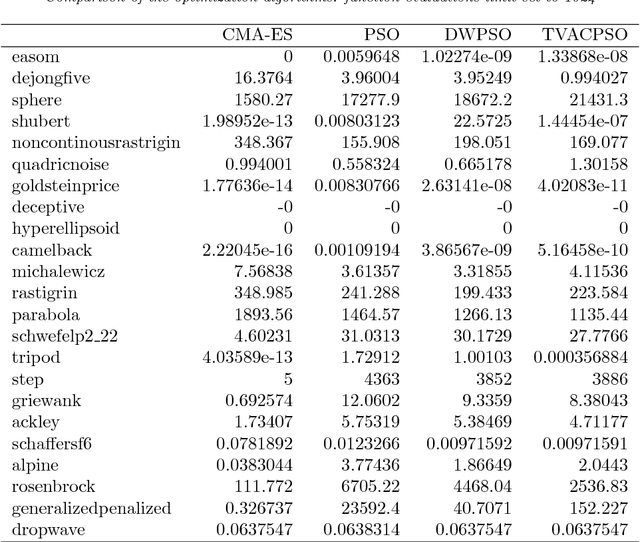
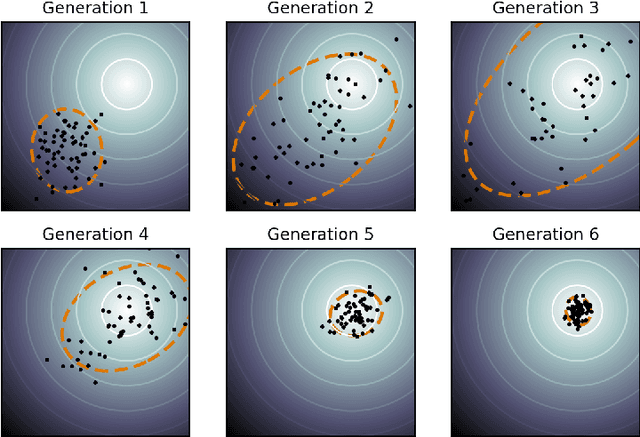
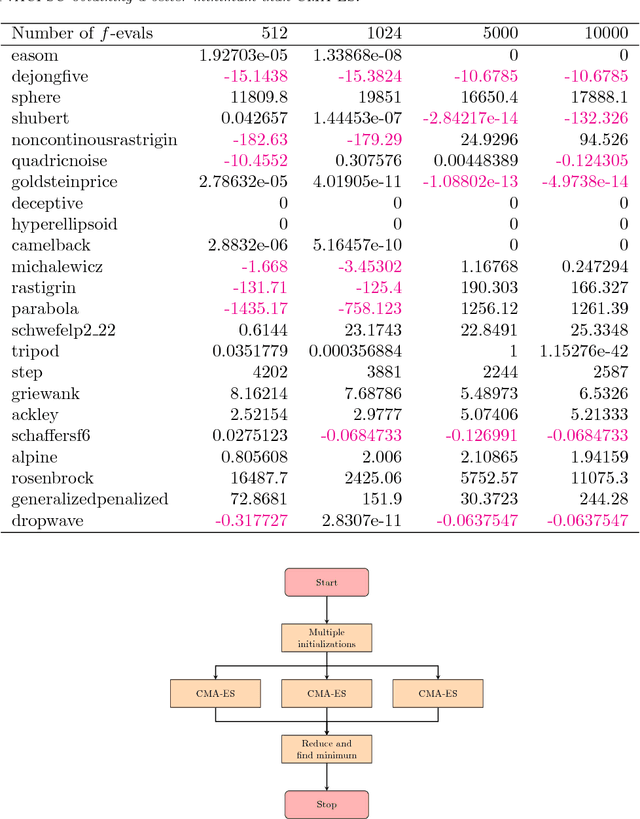
In many practical optimization problems, the derivatives of the functions to be optimized are unavailable or unreliable. Such optimization problems are solved using derivative-free optimization techniques. One of the state-of-the-art techniques for derivative-free optimization is the covariance matrix adaptation evolution strategy (CMA-ES) algorithm. However, the complexity of CMA-ES algorithm makes it undesirable for tasks where fast optimization is needed. To reduce the execution time of CMA-ES, a parallel implementation is proposed, and its performance is analyzed using the benchmark problems in PythOPT optimization environment.
Bridgeout: stochastic bridge regularization for deep neural networks
Apr 21, 2018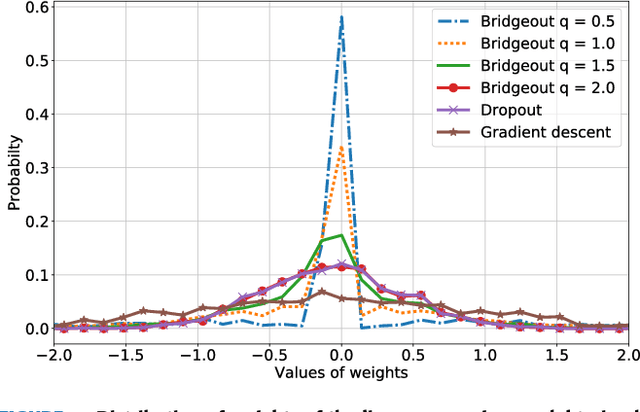



A major challenge in training deep neural networks is overfitting, i.e. inferior performance on unseen test examples compared to performance on training examples. To reduce overfitting, stochastic regularization methods have shown superior performance compared to deterministic weight penalties on a number of image recognition tasks. Stochastic methods such as Dropout and Shakeout, in expectation, are equivalent to imposing a ridge and elastic-net penalty on the model parameters, respectively. However, the choice of the norm of weight penalty is problem dependent and is not restricted to $\{L_1,L_2\}$. Therefore, in this paper we propose the Bridgeout stochastic regularization technique and prove that it is equivalent to an $L_q$ penalty on the weights, where the norm $q$ can be learned as a hyperparameter from data. Experimental results show that Bridgeout results in sparse model weights, improved gradients and superior classification performance compared to Dropout and Shakeout on synthetic and real datasets.
Prediction of Muscle Activations for Reaching Movements using Deep Neural Networks
Jun 13, 2017

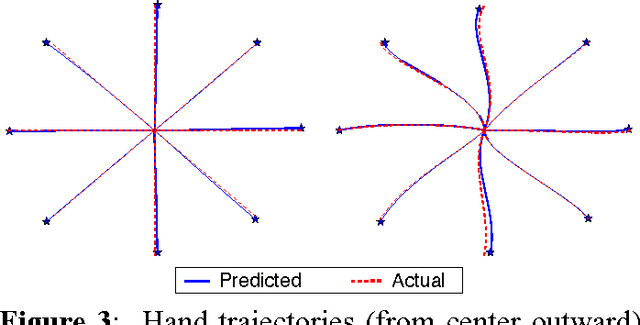
The motor control problem involves determining the time-varying muscle activation trajectories required to accomplish a given movement. Muscle redundancy makes motor control a challenging task: there are many possible activation trajectories that accomplish the same movement. Despite this redundancy, most movements are accomplished in highly stereotypical ways. For example, point-to-point reaching movements are almost universally performed with very similar smooth trajectories. Optimization methods are commonly used to predict muscle forces for measured movements. However, these approaches require computationally expensive simulations and are sensitive to the chosen optimality criteria and regularization. In this work, we investigate deep autoencoders for the prediction of muscle activation trajectories for point-to-point reaching movements. We evaluate our DNN predictions with simulated reaches and two methods to generate the muscle activations: inverse dynamics (ID) and optimal control (OC) criteria. We also investigate optimal network parameters and training criteria to improve the accuracy of the predictions.